【人工智能】智能计算概述、神经网络计算、机器学习计算、遗传算法、模糊计算、群智能计算
智能计算概述
智能计算(Intellectual Computing,IC),也称计算智能(Computational Intelligence,CI)或软计算(Soft Computing,SC),是受人类组织、生物界及其功能和有关学科内部规律的启迪,根据其原理模仿设计出来的求解问题的一类算法。智能计算所含算法的范围很广,主要包括神经网络、机器学习、遗传算法、模糊计算、蚁群算法、人工鱼群算法、粒子群算法、免疫算法、禁忌搜索、进化算法、启发式算法、模拟退火算法、混合智能算法等类型繁多、各具特色的算法。以上这些智能计算的算法都有一个共同的特点就是通过模仿人类智能或生物智能的某一个或某一些方面而达到模拟人类智能、实现将生物智慧、自然界的规律等设计出最优算法,进行计算机程序化,用于解决很广泛的一些实际问题。当然,智能计算的这些不同研究领域和算法各有各的特点,虽然它们具有模仿人类和生物智能的共同点,但是在具体实现方法上还存在一些不同点。例如人工神经网络模仿人脑的生理构造和信息处理的过程,模拟人类的智慧;模糊计算模仿人类语言和思维中的模糊性概念,也是模拟人类的智慧;进化计算模仿生物进化过程和群体智能过程,模拟大自然的智慧等。

智能计算(摘自互联网)
智能计算,借鉴仿生学的思想,基于生物体系的生物进化、细胞免疫、神经细胞网络等诸多机制,用数学语言抽象描述的计算方法,是基于数值计算和结构演化的智能,是智能理论发展的高级阶段。智能计算有着传统计算无法比拟的优越性,它的最大特点就是不需要对问题自身建立精确的数学模型,非常适合于解决那些因为难以建立有效的形式化模型而用传统的数值计算方法难以有效解决、甚至无法解决的问题。
随着计算机系统智能性的不断增强,由计算机自动和委托完成任务的复杂性和难度也在不断增加。所以,智能计算也可以看作是一种经验化的计算机思考性的算法,是人工智能体系的一个分支,是辅助人类去处理各式问题的具有独立思考能力的系统。
智能计算是借助自然界、特别是生物界规律的启示,根据其规律,设计出求解问题的算法。数学、物理学、化学、生物学、心理学、生理学、神经科学和计算机科学等诸多学科的现象与规律都可能成为智能计算算法的基础和思想来源。从相互关系上来看,智能计算属于人工智能的一个分支。现在,智能计算的发展也面临严峻的挑战,其中一个重要原因就是智能计算目前还缺乏坚实的数学理论基础,还不能像物理、化学、天文等学科那样非常自如地运用数学工具解决各自的计算问题。虽然神经网络具有比较完善的理论基础,但是像进化计算等一些重要的智能算法还没有完善的数学基础;智能计算算法的稳定性和收敛性的分析与证明还处于研究的开始阶段。通过数值实验方法和具体应用手段检验智能计算算法的有效性和高效性是研究智能计算算法的重要方法。从其本质上来看,智能计算是仿生的、随机化的、经验性的,大自然也是随机性的、具有经验性的,抽取大自然的这一特性,自动调节形成经验、取得可用的结果。这些方法还具有以下共同的要素:自适应的结构、随机产生的或指定的初始状态、适应度的评测函数、修改结构的操作、系统状态存储结构、终止计算的条件、指示结果的方法、控制过程的参数等等。计算智能的这些方法具有自学习、自组织、自适应的特征和简单、通用、健壮性强、适于并行处理等优点。在并行搜索、联想记忆、模式识别、知识自动获取等方面得到了广泛的应用,取得了诸多开创性的成果。
这里所说的“软计算”是相对于“硬计算”而言的。所谓“硬计算”是指传统的数值计算,具有可用的完善数学模型,坚实的数学理论基础,主要特征是严格、确定和精准。但是硬计算并不适合处理现实生活中的许多问题,如汽车驾驶、人脸识别、信息检索等,软计算通过对不确定、不精确及不完全取值的容错以取得低代价的解决方案和稳定性,模拟自然界中智能系统的生化过程(人的感知、脑结构、生物进化和免疫等)来有效的处理日常工作、科研和生产中遇到的诸多问题。当然,软、硬计算的说法只是相对而言的,很难进行严格的定义和区分。
智能计算跟数值计算的目的是一样的,即通过计算得到令人满意的接近真解的近似解,再拿这个近似解代替真解来说明和解决问题。一般情况下,很多问题是没有解析解的,这时可以通过数学建模、用计算方法来求数值解;当遇到问题特别复杂,用传统计算方法计算量太大或很难在计算机上实现时,可以考虑采用智能算法。
计算智能是受大自然智慧和人类智慧的启发而设计出的一类算法的统称,随着技术的进步,在科学研究和工程实践中遇到的问题变得越来越复杂,采用传统的计算方法来解决这些问题面临着计算复杂度高、计算时间长等问题,特别是对于一类高难度问题,传统算法根本无法在可以接受的时间内求出精确解。因此,为了在求解时间和求解精度上取得平衡,提出了很多具有启发性特征的智能算法。这些算法或模仿生物界的进化过程,或模仿生物的生理构造和身体机能,或模仿动物的群体行为,或模仿人类的思维、语言和记忆过程的特性,或模仿自然界的物理现象,希望通过模拟大自然和人类的智慧实现对问题的优化求解,在可接受的时间内求解出可以接受的解。这些算法共同组成了计算智能算法。
智能计算和不少学科之间有着密切的关系,如智能计算和人工智能、最优化算法及统计计算等。

人工智能(Artificial Intelligence,AI),是研究、开发用于模拟、延伸和扩展人类的智能的理论、方法、技术及应用系统的一门技术科学,是计算机科学的一个分支,它企图了解智能的实质,以得出一种新的能以人类智能相似的方式做出反应的智能性机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作,但智能计算和人工智能是两个完全不同的概念,计算和通信两个领域的融合开创了智能计算的新天地,现在计算机已经可以更聪明地帮助人们获得和处理信息,这已经和人工智能的概念大相径庭了。从相互关系上看,计算智能应属于人工智能的一个分支。
最优化算法解决的是一般的最优化问题。最优化问题可以分为求解一个或一组函数中、使得函数取值最小的自变量的函数优化问题和在一个解空间里面,寻找最优解,使目标函数值最小的组合优化问题等。优化算法有很多,经典算法包括线性规划,动态规划等,改进型局部搜索算法包括爬山法,最速下降法等;智能计算中的模拟退火、遗传算法以及禁忌搜索称作指导性搜索法,而神经网络,混沌搜索则属于系统动态演化方法,从不同的角度和策略实现改进,取得较好的”全局最小解”。二者之间既有区别,而又一定的关系,形成互补去解决常见的一些优化问题。
从比较广泛的意义上讲,智能计算和统计计算、蒙特卡罗方法联系甚为密切,可互为从属关系,是你中有我、我中有你,使用中也是互相补充。从这些算法的介绍和使用中不难发现这一特点。
智能计算是一种多层次级的计算模式,通常可分为6个层次:第一层为操作模拟层,把一些最基础的思考操作进行程序化处理;第二层为存在经验层,即对于优势的经验和便捷的过程代码化;第三层称为绩效评估层,即对各种经验的模拟结果进行评分,并能随着条件和期望结果的变化改进评分体系;第四层分为A、B两个系统:A系统通过智能计算对系统的变数进行有效的预测,B系统对这可能存在的预测结果进行的预判性评估;第五层为决策执行层,对上面的决策执行并在执行过程中进行一些必要的修正;第六层是智能计算的经验系统,对实际运行结果进行总结和经验性判定,判断判定结果的准确度。
现在,智能计算在国内外得到广泛的关注,已经成为人工智能以及计算机科学的重要研究方向,并在自身性能的提高和应用范围的拓展中不断完善。计算智能的研究、发展与应用,无论是研究队伍的规模、发表的论文数量,还是网上的信息资源,发展速度都很快,已经得到了国际学术界的广泛认可,并且在优化计算、模式识别、图像处理、自动控制、经济管理、机械工程、电气工程、通信网络和生物医学等多个领域取得了成功的应用,应用领域涉及国防、科技、经济、工业和农业等各个方面,尤其是在军事、金融工程、非线性系统最优化、知识工程、计算机辅助医学诊断等方面取得了丰硕的成果,下面简单介绍智能计算在这些领域中的应用。
科学技术的不断进步使得军事领域的各个方面都发生了革命性的变革和质的飞跃。当前,以计算机和信息技术为核心的新军事变革,使得现代战争呈现出的特点已不再是过去的以“大”吃“小”,而是现在的以“快”吃“慢”。加快信息处理速度,争夺战场信息优势,运用智能化的武器装备,已经成为21世纪战争的基本形态。面对这一重大变革,世界各国军队都在调整军事战略,其中发展先进的计算技术已成为各国军队的共同选择。计算智能是借助现代计算工具模拟人的智能机制、生命演化过程和人的智能行为而进行信息获取、问题分析、理论应用和方法生成的一种计算技术。近年来,在新的形势下,国家安全和军事领域中出现了许多新的问题,有些问题难以用传统方法来解决,甚至在某些情况下还不能完全将它们表示出来。为此,人们采用包括模糊数学、神经网络和遗传算法在内的计算智能来解决这些问题,取得了一些新的进展和突破。目前,计算智能在军事领域中的应用已涉及到作战指挥、信息处理、管理决策、智能控制、专家系统、故障诊断等方面,并还在不断拓宽深入中。
金融工程是将工程思维引入金融领域,综合运用各种工程方法来设计、开发和实施新型的金融产品,创造性的解决各种金融问题。如在股市预测、智能交易决策系统和证券组合投资策略等方面,计算智能技术都取得了比较好的效果。
对计算智能领域的神经网络融合算法、自适应信号处理所提出的各种算法应用于计算机辅助医学诊断和生物医学信号分析,也取得了许多应用成果。
目前关于计算智能的研究和应用仍处于蓬勃发展初期阶段,应用范围遍及各个科学领域。虽然计算智能是一门新兴的综合型学科,而且各种智能方法的发展历史也不是很长,但是其发展却是相当迅猛,应用也相当广泛。当前除了对单一的算法进行研究和应用之外,现已开始对各种算法的融合进行研究,针对各个算法的特点,有目的的进行取长补短的算法综合。典型的融合方案有人工神经网络与模糊逻辑、人工神经网络与免疫算法和遗传算法、模糊逻辑与免疫算法、模糊逻辑与遗传算法及遗传算法与免疫算法等,特别是和传统数值算法结合,取得了一些突破性成果。融合之后的算法可以提高算法的性能,增强算法的适应性和稳定性,同时还克服了算法选择的盲目性。另外,还有学者提出了计算智能的新框架――生物网络结构,即神经内分泌免疫网络。它由人工神经网络、人工内分泌系统和人工免疫系统等组成。新框架的提出为人们研究其理论和应用技术提供了新平台,为计算智能今后的发展指明了方向。计算智能技术在自身性能的提高和应用范围的拓展中将得到不断完善。
目前的智能计算研究的水平暂时还很难使“智能机器”真正具备人类的常识,但智能计算将在21世纪得到蓬勃发展,不仅仅只是功能模仿要持有信息机理一致的观点,即人工脑与生物脑将不只是功能模仿,而是具有相同的特性。这两者的结合将开辟一个全新的领域,开辟很多新的研究方向。智能计算将探索智能的新概念,新理论,新方法和新技术,而这一切将在今后的发展中都会取得新的重大成就。
神经网络计算
神经网络计算 (Neural Network Computing NNC)是通过对人脑的基本单元——神经元的模拟,经过输入层、隐层、输出层等层次结构,对数据进行调整、评估和分析计算,得到的一类具有学习、联想、记忆和模式识别等功能的智能算法。
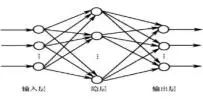
神经网络计算示意图(摘自互联网)
要想比较深入的理解神经网络计算,就必须对神经网络系统有一定的理解,下面对其进行一些简单介绍。
神经网络(Neural Network,NN)是由大量的、简单的处理单元(简称为神经元)经广泛互连而形成的一个复杂网络系统,反映了人脑功能的许多基本特征,是一个高度复杂化的非线性动力学系统。神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学习等能力,特别适合处理需要同时考虑众多因素和条件的、含不精确和模糊信息的实际问题。神经网络的发展与神经科学、数理科学、认知科学、计算机科学、人工智能、控制论、机器人学、心理学、分子生物学等诸多学科有关,是一门新兴的边缘交叉学科。

神经网络示意图(摘自互联网)
神经网络是脑科学、神经心理学和信息科学等多学科的交叉研究领域,也是近年来高科技领域的一个新的研究热点,其目的是想通过对人脑的组成机理和思维方式等的研究,进而通过模拟人脑的结构和工作模式使机器具有类似人类的智能。
神经网络就是通过神经元、细胞、触突等结构组成的一个大型网络结构,用来帮助生物进行思考和行动。那么人们就想到了计算机是不是也可以像人脑一样具有这种结构,这样是不是就可以进行类似的思考。
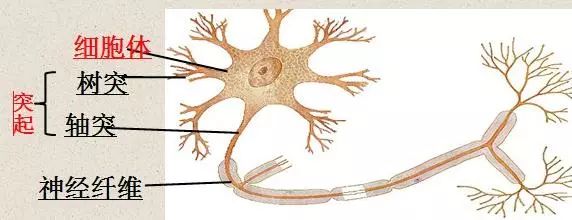
神经元示意图(摘自互联网)
神经网络结构图(摘自互联网)
人脑神经网络系统的基本构造是神经元(神经细胞),是处理人体内各部分之间相互信息传递的基本单元。神经生物学家研究的结果表明,人的一个大脑一般有一千个以上的神经元,每个神经元都由一个细胞体,一个连接其他神经元的轴突和一些向外伸出的其它较短分支——树突组成。轴突的功能是将神经元的输出信号传递给别的神经元,其末端的许多神经末梢使得信号可以同时传送给多个神经元。树突的功能是接受来自其它神经元的信号,神经元细胞体将接受到的所有信号进行简单处理后再由轴突输出。神经元的树突与另外的神经元的神经末梢相连的部分称为突触,这一结构的特点决定着人工神经网络具有高速信息处理的能力。人脑的每个神经元大约有上百个树突及相应的突触,一个人的大脑形成一千个左右的突触。虽然每个神经元的运算功能十分简单,且信号传输速率也较低,但由于各神经元之间的极度并行互连功能,最终使得一个普通人的大脑在约1秒内就能完成现行计算机至少需要数10亿次运算处理能力才能完成的任务。
人脑神经网络的知识存储容量很大。在神经网络中,知识与信息的存储表现为神经元之间分布式的物理联系,分散地表示和存储于整个网络内的各神经元及其连线上。每个神经元及其连线只表示一部分信息,而不是一个完整的具体概念,只有通过各神经元的分布式综合效果才能表达出特定的概念和知识。
由于人脑神经网络中神经元个数众多以及整个网络存储信息容量巨大,使得它具有很强的不确定性信息的处理能力,即使输入信息不完全、不准确或模糊不清,神经网络仍然能够通过联想思维得到存在于记忆中事物的完整图象,只要输入的模式接近于训练样本,系统就能给出正确的推理结论。
下图中的x1、x2、x3等表示输入值,构成第一层L1,组成输入层;中间的圆形成L2、 L3 、L4等多个层次,组成隐层;神经元经过多层的调整、评估和分析计算处理后得出hw,b(x)的结果作为神经元的输出值,构成输出层,组成人们常说的人工神经网络。
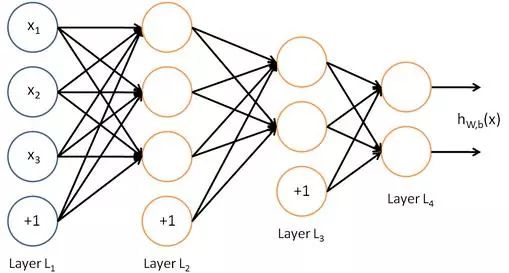
神经网络神经元结构示意图(摘自互联网)
上图中的橙色圆都是用来计算hw,b(x)的,纵向我们叫做层(Layer),每一层都以前一层的结果做为输入,经过处理得到输出结果传递给下一层
如果我们把神经网络看做一个黑盒子,那么最左边的x1、x2、x3等是这个黑盒子的输入X,最右边的hw,b(x)是这个黑盒的输出Y,可以通过一个数学模型进行拟合,通过大量数据来训练这个模型,之后就可以通过训练好的模型预估新的样本X应该能得出什么样的结果Y。
以上简单说明神经网络的结构,通过较深的多个层次来模拟真实情况,从而构造出最能表达真实世界的模型,它的运作成本就是海量的训练数据和巨大的计算处理工作量。
正是因为人脑神经网络的结构特点和其信息存储的分布式特点,使得它相对于其它的判断识别系统,如专家系统、层次分析系统等,具有显著的稳健性优点。生物神经网络不会因为个别神经元的损失而失去对原有模式的记忆,最有力的证明是,当一个人的大脑因意外事故受轻微损伤之后,并不会失去原有事物的全部记忆。神经网络也有类似的情况。因某些原因,无论是网络的硬件实现还是软件实现中的某个或某些神经元失效时,整个网络仍然能继续工作。
人工神经网络是一种非线性的处理单元。只有当神经元对所有的输入信号的综合处理结果超过某一门限值后才输出一个信号,因此神经网络是一种具有高度非线性的超大规模连续时间动力学系统,突破了传统的以线性处理为基础的计算机的局限性,标志着人们智能信息处理能力和模拟人脑智能行为能力的一大飞跃。
神经网络经过多年的研究和发展,已经形成了几十种类型不同并各具特点的神经网络模型,分析处理算法也各具特点,所以下面只简单的介绍几种典型的常用神经网络。
1.多层感知网络。它是一类具有三层或三层以上的阶层型神经网络。典型的多层感知网络是三层、前馈型的阶层网络,即含有输入层、隐层(也称中间层、隐含层)和输出层。相邻层之间的各神经元实现全连接,即下一层的每一个神经元与上一层的每个神经元都实现全连接,而且每层各神经元之间无连接。但它并非十分完善,存在以下一些主要缺陷:学习收敛速度慢、网络的学习记忆具有不稳定性,当给一个训练好的网提供新的学习记忆模式时,将使已有的连接权值被打乱,导致已记忆的学习模式的信息的消失。
2.竞争神经网络。它是基于人的视网膜及大脑皮层对剌激的反应而引出的一类神经网络。神经生物学的研究结果显示生物视网膜中有许多特定的细胞,对特定的输入模式如图形比较敏感,并使得大脑皮层中的特定细胞产生大的兴奋,而其相邻的神经细胞的兴奋程度被抑制。对于某一个输入模式,通过竞争在输出层中只激活一个相应的输出神经元。许多输入模式,在输出层中将激活许多个神经元,从而形成一个反映输入数据的“特征图形”。竞争神经网络是一种以无教师方式进行网络训练的网络,通过自身训练,自动对输入模式进行分类。竞争型神经网络及其学习规则与其它类型的神经网络和学习规则相比,有其自己的鲜明特点。在网络结构上,它既不象阶层型神经网络那样各层神经元之间只有单向连接,也不象全连接型网络那样在网络结构上没有明显的层次界限。它一般是由输入层(模拟视网膜神经元)和竞争层(模拟大脑皮层神经元,也叫输出层)构成的两层网络。两层之间的各神经元实现双向全连接,而且网络中没有隐含层,有时竞争层各神经元之间存在横向连接。竞争神经网络的基本思想是网络竞争层各神经元竞争对输入模式的响应机会,最后仅有一个神经元成为竞争的胜利者,并且只将与获胜神经元有关的各连接权值进行修正,使之朝着更有利于它竞争的方向调整。神经网络工作时,对于某一输入模式,网络中与该模式最相近的学习输入模式相对应的竞争层神经元将有最大的输出值,即以竞争层获胜神经元来表示分类结果。这是通过竞争得以实现的,实际上也就是网络回忆联想的过程。
竞争型神经网络的缺点和不足之处在于它仅以输出层中的单个神经元代表某一类模式,所以一旦输出层中的某个输出神经元损坏,则导致该神经元所代表的该模式信息全部丢失。
3.霍普菲尔网络(Hopfield network,HN)。它是一个由非线性元件构成的全连接型单层反馈系统。网络中的每一个神经元都将自己的输出通过连接权传送给所有其它神经元,同时又都接收所有其它神经元传递过来的信息,即网络中的神经元t时刻的输出状态实际上间接地与自己的t-1时刻的输出状态有关。所以,霍普菲尔神经网络是一个反馈型的网络,状态变化可以用差分方程来表征。反馈型网络的一个重要特点就是它具有稳定状态。当网络达到稳定状态的时候,也就是它的能量函数达到最小的时候。这里的能量函数不是物理意义上的能量函数,而是在表达形式上与物理意义上的能量概念一致,表征网络状态的变化趋势,并可以依据霍普菲尔工作运行规则不断进行状态变化,最终能够达到的某个极小值的目标函数。网络收敛就是指能量函数达到极小值。如果把一个最优化问题的目标函数转换成网络的能量函数,把问题的变量对应于网络的状态,那么霍普菲尔神经网络就能够用于解决优化组合问题。
霍普菲尔神经网络的能量函数是朝着梯度减小的方向变化,但它仍然存在一个问题,那就是一旦能量函数陷入到局部极小值,它将不能自动跳出局部极小点,到达全局最小点,因而无法求得网络的整体最优解
4. BP(back propagation)神经网络。它有一种按照误差逆向传播训练的算法、以此增强网络的分类和识别能力、解决非线性问题而采用多层前馈网络,即在输入层和输出层之间加上隐层,构成多层前馈感知器网络,是一种对非线性可微分函数进行权值训练的多层网络。BP神经网络算法就是以网络误差平方为目标函数、采用梯度下降法来计算目标函数的最小值。
BP神经网络是目前应用最广泛的神经网络,这里将对其算法进行一些进一步的介绍。
BP神经网络算法是一种有监督式的学习算法,由输入层、中间层、输出层组成的多阶层神经网络,中间层可扩展为多层。相邻层之间各神经元进行全连接,而每层各神经元之间无连接。网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,各神经元获得网络的输入响应产生连接权值,然后按减小希望输出与实际输出误差的方向,从输出层经各中间层逐层修正各连接权,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能的接近。此过程反复交替进行,直至网络的全局误差趋向给定的极小值,即完成学习的过程。当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。粗略的计算步骤如下:
(1)初始化,随机给定各连接加权值[wij],[vjt]及阈值θi,rt;
(2)根据给定的输入输出模式,经计算隐层、输出层各单元的输出结果为:
bj=f(⅀wijai-θj), ct=f(⅀vjtbj-rt);
式中bj为隐层第j个神经元的实际输出;ct为输出层第t个神经元的实际输出;wij为输入层至隐层的连接权;vjt为隐层至输出层的连接权;
(3)选取下一个输入模式,返回第2步反复训练,直到网络的输出误差达到要求时结束训练。
传统的BP算法,实质上是把一组样本输入/输出问题转化为一个非线性优化问题,并通过梯度下降算法,利用迭代运算求解权值问题的一种学习方法,但其收敛速度慢且容易陷入局部极小,可用高斯消元法进行改进。欲了解更详细的算法,可参考其他有关文献。
BP神经网络最主要的优点是具有极强的非线性映射能力。理论上,对于一个三层和三层以上的BP网络,只要隐层神经元数目足够多,该网络就能以任意精度逼近一个非线性函数。其次,BP神经网络具有对外界刺激和输入信息进行联想记忆的能力。这是因为它采用了分布并行的信息处理方式,对信息的提取必须采用联想的方式,才能将相关神经元全部调动起来。这种能力使其在图像复原、语言处理、模式识别等方面具有重要应用。再次,BP神经网络对外界输入样本有很强的识别与分类能力。由于它具有强大的非线性处理能力,因此可以较好地进行非线性分类,解决了神经网络发展史上的非线性分类难题,使其具有优化计算的能力。BP神经网络本质上是一个非线性优化问题,它可以在已知的约束条件下,寻找一组参数组合,使该组合确定的目标函数达到最小。不过,其优化计算存在局部极小问题,必须通过改进才能进一步完善。
多层神经网络可以应用于线性系统和非线性系统中,对于任意函数模拟逼近。当然,感知器和线性神经网络能够解决这类网络问题。但是,虽然理论上是可行的,但实际上BP网络并不一定总能有解。
对于非线性系统,选择合适的学习率是一个重要问题。在线性网络中,学习率过大会导致训练过程不稳定;相反,学习率过小又会造成训练时间过长。和线性网络不同,对于非线性多层网络很难选择很好的学习率。
非线性网络的误差面比线性网络的误差面复杂得多,问题在于多层网络中非线性传递函数有多个局部最优解。寻优的过程与初始点的选择关系很大,初始点如果更靠近局部最优点,而不是全局最优点,就不会得到正确的结果,这也是多层网络无法得到最优解的一个原因。为了解决这个问题,在实际训练过程中,应重复选取多个初始点进行训练,以保证训练结果的全局最优性。网络隐层神经元的数目也对网络有一定的影响。神经元数目太少会造成网络的不适性,而神经元数目太多又会引起网络的过适性。
BP神经网络无论在网络理论还是在性能方面都已比较成熟,突出优点就是具有很强的非线性映射能力和柔性的网络结构。网络的中间层数、各层的神经元个数可根据具体情况任意设定,并且随着结构的差异其性能也有所不同。但BP神经网络也存在缺陷,主要表现在学习速度慢,容易陷入局部极小值,网络层数、神经元个数的选择还缺少相应的理论指导。
人工神经网络能较好的模拟人的形象思维,对信息具有很好的隐藏性,还具有容错性强、稳健性强和自学习性强等特点,是一个大规模自组织、自适应且具有高度并行协同处理能力的非线性动力系统。人工神经网络理论的应用已经渗透到多个领域,诸如信息处理、自动化、工程应用、经济发展评价和辅助决策及医学领域中的检测数据分析和医学专家系统等。
总起来看,神经网络模型与传统计算模型不同。从计算方式上讲,神经元网络计算把一些简单的、大量的计算单元连接在一起,形成网络计算,代替只用一个计算单元进行计算的传统模式,也就是用分布式、并行计算代替集中式、串行计算;从模型构建上讲,传统的计算方法采用从上到下的方式预先构建数学模型,在神经元网络中,系统通过采集数据并进行学习的方法在计算过程中构建数据模型,进而建立网络结构;综合讲来,神经元网络适应性较强,并行计算处理速度较快,对经验知识要求较少。
一般来讲,神经网络在规模比较小时效果不错。规模可用三个指标来衡量:特征数量(通常在二三百个左右)、训练样本数(通常由几千到几万)和分类数(通常有几十个)。当问题规模变大时,比如特征数过千、训练样本数达到了几万甚至几十万,特别是分类数达到几百、上千,这时的神经元网络计算可能会出现一些问题。
人工神经网络特有的非线性适应性信息处理能力,克服了传统人工智能方法对于直觉,如模式、语音识别、非结构化信息处理方面的缺陷,使之在神经专家系统、模式识别、智能控制、组合优化、预测等领域得到成功应用。人工神经网络与其它传统方法相结合,将推动人工智能和信息处理技术不断发展。近年来,人工神经网络正向模拟人类认知的道路上更加深入发展,与模糊系统、遗传算法、进化机制等结合,形成计算智能,成为人工智能的一个重要的研究方向,将会在实际应用中得到进一步发展,将信息集合应用于人工神经网络研究,为人工神经网络的理论研究开辟了新的途径。
神经元网络计算越来越受到人们的关注,为解决大型复杂度高的问题提供了一种相对来说比较简单的有效算法,能较容易地解决具有上百个参数的分类和回归计算中一些常见的问题。
机器学习计算
机器学习(Machine Learning),人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,主要使用归纳、综合而不是演绎的方法研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是一门多领域的交叉学科,涉及到概率论、统计学、逼近论、凸分析、算法复杂度理论和计算机科学等诸多学科。

机器学习(摘自互联网)
机器学习计算(Machine Learning Computing)主要设计和分析一些让计算机可以自动“学习”的算法,是一类从数据中自动分析获得规律、利用规律,对未来数据进行分类、聚类和预测等的一类算法。因为机器学习计算中涉及了大量的统计学理论,机器学习与统计推断的联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习计算关注可以实现的、行之有效的学习算法,很多推论问题具有无程序可循的难度,所以部分的机器学习研究是开发简单、处理容易的近似算法。
机器学习已经得到了十分广泛的应用,如数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用等。
从更广泛的意义上来看,机器学习是人工智能的一个子集。人工智能旨在使计算机更加智能化,而机器学习已经证明如何做到这一点。简而言之,机器学习是人工智能的应用,通过应用从数据中反复学习得到算法,可以改进计算机的功能,而无需进行明确的编程。
在给出机器学习计算各种算法之前,最好是先研究一下什么是机器学习和如何对机器学习进行分类,才能更好的理解和掌握一些具体的机器学习算法并将其用于实际问题的计算和处理。
学习是人类具有的一种重要智能行为,但究竟什么是学习,长期以来却众说纷纭。社会学家、逻辑学家和心理学家都各有自己不同的看法和说法。比如,有人定义机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何从经验学习中改善具体算法的性能,也有人认为机器学习是对能通过经验自动改进计算机算法的研究,还有人认为机器学习是用数据或以往的经验,以此优化计算机程序的性能标准等等。尽管如此,为了便于进行讨论和推进机器学习学科的进展,有必要对机器学习给出定义,即使这种定义是不完全、不完整和不充分的并存在诸多争议的。
顾名思义,机器学习是研究如何使用机器来模拟人类学习活动的一门学科。稍为严格的提法是:机器学习是一门研究机器获取新知识、新技能并识别现有知识的学问。这里所说的“机器”,当然指的是计算机;现在是电子计算机,将来还可能是中子计算机、光子计算机或神经网络计算机。
计算机能否象人类一样能具有学习的能力,特别是机器的学习能力是否能超过人类,确有许多不同的想法和看法,争议颇多。持否定意见人的一个主要论据是:机器是人造的,其性能和动作完全是由设计者规定的,因此无论如何其能力也不会超过设计者本人。这种意见对不具备学习能力的计算机来说的确是对的,可是对具备了学习能力的计算机就值得考虑了,因为这种计算机的能力通过学习和实际应用会不断提高和增强,过了一段时间之后,设计者本人也不知它的能力达到了什么水平、是否超过了自己。
对机器学习可按照不同的标准和方法进行分类,下面简单介绍两种常见的分类方法。
(1)基于学习策略的分类 学习策略是指学习过程中系统所采用的推理策略。一个学习系统总是由学习和环境两部分组成。由环境(如书本或教师)提供信息,学习部分则实现信息转换,用能够理解的形式记忆下来,并从中获取有用的信息。学习策略的分类标准就是根据学生实现信息转换所需的推理多少和难易程度来分类的,依照从简到繁、从少到多的次序分为以下六种基本类型:
1)机械学习 学习者无需任何推理或其它的知识转换,直接吸取环境所提供的信息,主要考虑如何索引存贮知识并加以利用。系统的学习方法是直接通过事先编好、构造好的程序来学习,学习者不作任何工作,或者是通过直接接收既定的事实和数据进行学习,对输入信息不作任何的推理。
2)示教学习 学生从环境中获取信息,把知识转换成内部可使用的表示形式,并将新的知识和原有知识有机地结合为一体。所以要求学生有一定程度的推理能力,但环境仍要做大量的工作。教师以某种形式提出和组织知识,以使学生拥有的知识可以不断的增加。这种学习方法和人类社会的学校教学方式有点相似,学习的任务就是建立一个系统,使它能接受教导和建议,并有效地存贮和应用学到的知识。目前,不少专家系统在建立知识库时就使用这种方法以实现知识获取。
3)演绎学习 学生所用的推理形式为演绎推理,从公理出发,经过逻辑变换推导出结论。这种推理是”保真”变换和特化的过程,使学生在推理过程中可以获取有用的知识。这种学习方法包含宏操作学习、知识编辑和组块技术。
4)类比学习 利用源域和目标域二个不同领域中的知识相似性,通过类比从源域的知识推导出目标域的相应知识,从而实现学习。类比学习系统可以使一个已有的计算机应用系统转变为适应于新的领域,来完成原先没有设计出来的类似功能。类比学习需要比上述三种学习方式更多的推理,一般要求先从知识源中检索出可用的知识,再将其转换成新的形式,用到新的状态中去。
5)解释学习 学生根据教师提供的目标概念、该概念的一个例子、领域理论及可操作准则,首先构造一个解释来说明为什么该例子满足目标概念,然后将解释推广为目标概念的一个满足可操作准则的充分条件。
6)归纳学习 归纳学习是由教师或环境提供某些概念的一些实例或反例,让学生通过归纳推理得出该概念的一般描述。这种学习的推理工作量远多于示教学习和演绎学习,因为环境并不提供一般性概念描述。归纳学习是最基本的、发展较为成熟的一类学习方法,在人工智能领域中已经得到广泛的研究和应用。
(2)基于学习方式的分类 机器学习算法按照学习方式的不同可以分为五种类型:有监督学习、无监督学习、半监督学习、强化学习和深度学习。
1)有监督学习 输入的数据为训练数据,并且每一个数据都会带有标签或类别。通过训练过程建模,模型需要作出预测,如果预测出错会被修正,直到模型输出准确的训练结果,训练过程会一直持续。常用于解决的问题有分类和回归,常用的算法包括分类、逻辑回归和BP神经网络。
2)无监督学习 输入数据没有标签或类别,输出没有标准答案,就是一系列的样本。无监督学习通过推断输入数据中的结构建模,可能是提取一般规律,可以是通过数学处理系统以减少冗杂,或者根据相似性组织数据。常用于解决的问题有聚类,降维和关联规则的学习。常用的算法包括了Apriori算法和K均值算法等。
3)半监督学习 半监督学习可以看做无监督学习的延伸,介于有监督学习和无监督学习二者之间,其输入数据包含标签和不带标签的样本。常用于解决的问题是分类和回归,常用的算法是对所有的无标签的数据建模进行的预测算法。
4)强化学习 强化学习是一个连续决策的过程,每次预测都有一定形式的反馈,但是没有精确的标签或者错误信息。
5) 深度学习 深度学习并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习,由于近几年该领域发展迅猛,一些特有的学习手段和算法相继提出,因此将其看作一种单独的学习方法。
深度学习是机器学习研究中的一个新的领域,目的在于建立、模拟人脑进行分析学习的神经网络,模仿人脑的机制来解释数据,如图像、声音和文本等多媒体数据。深度学习是无监督学习的一种,其概念源于人工神经网络的研究,含有多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示其属性类别或特征,以发现数据的分布式特征。基于深信度网络提出非监督逐层训练算法,为解决深层结构相关的优化难题带来了希望,随后提出多层自动编码器深层结构。此外提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
目前,机器学习领域的研究工作主要围绕在以下三个方面:
1)任务研析 对一组预定任务的学习系统进行研究,改进执行性能并提高其有效性;
2)模型研发 研究人类学习过程并进行计算机模拟和分析,改进现有模型,提出新的更加有效的模型;
3)理论分析 从理论上探索各种可能的机器学习方法,给出独立于应用领域的高效算法。
机器学习算法的功能可粗略的分为四大类,即分类、聚类、预测和降维,可用的机器学习算法不下数百种,包括回归分析、判别分析、聚类分析、因子分析和主成分分析、贝叶斯分类、决策树、支持向量机、EM、Adaboost、人工神经网络及它们之间的一些集成算法等。其中的回归分析、判别分析、聚类分析等已在统计计算里进行了介绍,神经网络计算也在上一篇文章中进行了较多的讨论,下面仅对机器学习中最常用的一些特有算法,如决策树算法、支持向量机算法、朴素贝叶斯算法、最大期望算法、KNN算法和K均值算法等,进行一些思考性、原理性的简单介绍。
1)决策树(Decision Trees)算法
决策树是一个预测模型,代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若想有多个输出,可以建立独立的决策树以处理不同输出。
一个决策树包含三种类型的节点,即决策节点,机会节点和终结点。这里,每个决策树都表述了一种树型结构,由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程完成。
决策树算法根据数据的属性采用树状结构建立决策模型,常常用来解决分类和预测问题。常见的算法有分类及回归树,ID3,C4.5,随机森林,多元样条回归等实际可用的一些算法。
2)支持向量机(Support Vector Machine,SVM)算法
SVM是一种監督式學習算法,广泛用于统计分类以及预测分析计算中。
SVM属于一般化线性分类器。这类分类器的特点是他们能够同时最小化经验误差与最大化几何边缘区,因此支持向量机也被称为最大边缘区分类器。
SVM的主要思想可以概括为两点:① 针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;② 基于结构风险最小化理论,在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定的上界。
3)朴素贝叶斯分类(Naïve Bayesian classification)算法
朴素贝叶斯是一种基于贝叶斯定理与特征条件独立假设的概率分类算法,通过对象的先验概率,利用贝叶斯公式
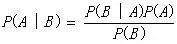
其中P(A|B)是后验概率,P(B|A)是似然概率,P(A)是先验概率,P(B)是预测先验概率。
根据上述公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类别作为该对象所属的类别。朴素贝叶斯算法简单,快速,具有较小的出错率,对结果解释容易理解。
4)最大期望(Expectation–Maximization,EM)算法
在统计计算中,最大期望算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量,经常用在机器学习和计算机视觉的数据集聚领域。最大期望算法经过两个步骤交替进行计算,第一步是计算期望(E),也就是将隐藏变量象能够观测到的一样包含在内从而计算最大似然的期望值;第二步是最大化(M),也就是最大化在E步上找到的最大似然的期望值从而计算参数的最大似然估计。M步上找到的参数然后用于另外一个E步计算,这个过程不断交替进行,进行改进,以寻求渐近最优结果。
5)K最近邻(k-Nearest Neighbor,KNN)分类算法
KNN分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN方法虽然从原理上依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
K-近邻算法的思想如下:首先,计算新样本与训练样本之间的距离,找到距离最近的K个邻居;然后,根据这些邻居所属的类别来判定新样本的类别,如果它们都属于同一个类别,那么新样本也属于这个类;否则,对每个后选类别进行评分,按照某种规则确定新样本的类别。
6)K-均值(K-means)算法
K-均值算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准 k(k<n)个聚类的一种算法。K-means 算法接受输入量 k,然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高,而不同聚类中的对象相似度较小。
k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心,而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的聚类,然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
从算法的表现上来说,它并不保证一定得到全局最优解,最终解的质量很大程度上取决于初始化的分组。由于该算法的速度快,因此常用的一种方法是多次运行k平均算法,选择最优解。
机器学习是继神经网络系统之后人工智能应用的又一重要研究领域,也是人工智能和神经网络计算的核心研究课题。对机器学习的研究及其进展,必将促使人工智能和整个科学技术的进一步发展。
遗传算法
遗传算法(Genetic Algorithms),也有人把它叫作进化算法(Evolutionary Algorithms),是基于生物进化的“物竞天择,适者生存”理论发展起来的一种应用广泛且高效随机搜索与优化并举的智能算法,其主要特点是群体搜索策略和群体中个体之间的信息交换,不依赖于问题的梯度信息。遗传算法最初被研究的出发点不是为专门解决最优化问题而设计的,它与进化策略、进化规划共同构成了遗传算法的主要框架,都是为当时人工智能的发展服务的。迄今为止,遗传算法是智能计算中最广为人知的一种算法。
遗传算法就是模拟自然界进化论的基本思想,可以很好地用于优化问题,若把它看作对自然过程高度理想化的模拟,更能显出它本身的优雅与应用的重要。该算法以一个群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、杂交和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五要素组成了遗传算法的核心内容。作为一种新的全局优化搜索算法,遗传算法以其简单通用、健壮性强、适于并行处理以及高效、实用等显著特点,在各个领域得到了广泛应用,取得了良好效果,并逐渐成为重要的智能算法之一。
近几年来,遗传算法主要在复杂优化问题求解和工业工程领域应用等方面,取得了一些令人信服的结果,所以引起更多人的关注。
要想进一步的了解遗传算法,当然要先了解遗传、进化及其有关的一些概念和知识,下面就对其进行一些简单介绍。作为遗传算法生物背景的介绍,了解下面的一些概念及内容也就够了。
个体:组成种群的单个生物;
种群:生物进化以群体的形式进行,这样的一个群体称为种群;
基因:DNA长链结构中占有一定位置的基本遗传单位,也叫遗传因子;
基因DNA、RNA片段(摘自互联网)
染色体:是生物细胞中含有的一种微小的丝状物,是遗传物质的主要载体,由多个遗传基因组成;
遗传:新个体会遗传父母双方各自一部分的基因,承现出亲子之间以及子代个体之间性状相似性,表明性状可以从亲代传递给子代;
变异:亲代和子代之间、子代和子代的不同个体之间总会存在一些差异,这种现象称为变异;变异是随机发生的,变异的选择和积累是生命多样性的根源;
进化:生物在其延续生命的过程中,逐渐适应其生存环境使得其品质不断得到改良,这种生命现象称为进化;生物的进化是以种群的形式进行的;
生存竞争,适者生存:生物的繁殖过程,会发生基因交叉、基因突变,适应度低的个体会被逐步淘汰,而适应度高的个体会越来越多;这样经过多代的自然选择后,保存下来的都是适应度很高的个体,其中很可能包含史上产生的适应度最高的那些个体。
遗传算法是解决搜索问题的一种通用算法,各种各样、类型不同的问题都可以使用。遗传算法的共同特征有: ① 首先组成一组候选解; ② 依据某些适应性条件测算这些候选解的适应度; ③ 根据适应度保留某些优良候选解,放弃其中欠佳的部分候选解; ④ 对保留的候选解进行某些操作,生成新的候选解。在遗传算法中,上述几个特征以一种特殊的方式组合在一起,如基于染色体群的并行搜索,带有猜测性质的选择操作、交换操作和突变操作。这种特殊的组合方式将遗传算法与其它搜索算法区别开来。
除上述共同特征外,遗传算法还具有以下几方面的特点:
(1) 遗传算法从问题解的串集中开始搜索,而不是从单个解开始,这是遗传算法与传统优化算法的最大区别。传统优化算法是从单个初始值迭代求最优解,容易误入局部最优解。遗传算法从串集开始搜索,覆盖面大,利于全局择优。
(2) 许多传统搜索算法都是单点搜索算法,容易陷入局部的最优解。遗传算法同时处理群体中的多个个体,即对搜索空间中的多个解进行评估,减少了陷入局部最优解的风险,同时算法本身易于实现并行化。
(3) 遗传算法基本上不用搜索空间的知识或其它辅助信息,而仅用适应度函数值来评估个体,在此基础上进行遗传操作。适应度函数不仅不受连续、可微等的约束,而且其定义域可以任意设定。这一特点使得遗传算法的应用范围得到很大扩展。
(4) 遗传算法不是采用确定性规则,而是采用概率的变迁规则来指导它的搜索方向。
(5) 具有自组织、自适应和自学习等特性。遗传算法利用进化过程获得的信息自行组织搜索时,硬度大的个体具有较高的生存概率,并获得更适应环境的基因结构。
遗传算法以一个群体中的所有个体为对象,利用随机化技术对编码参数空间进行高效搜索,把选择、杂交和变异等遗传现象构成遗传操作。作为一种全局优化搜索算法,遗传算法不考虑函数本身是否连续、是否可微等性质,以其简单通用、健壮性强和高效、实用、隐含并行性、容易找到“全局最优解”等显著特点,在许多领域得到成功应用,成为一种重要的智能算法。
上面的描述是简单的遗传算法模型,可由此给出下面的遗传算法流程图,再加延伸,可以在这一基本型上进行改进和发展,形成诸多不同类别的遗传算法,使其在科学和工程领域得到更广泛的应用。
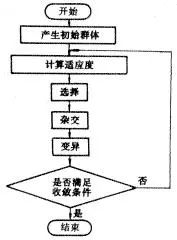
遗传算法流程图
上面遗传算法流程图中有六个重要的环节:
(1)编码和初始群体的生成:遗传算法在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结构数据,这些串结构数据的不同组合便构成了不同的点。然后随机产生N个初始串结构数据,每个串结构数据称为一个个体, N个体构成了一个群体。遗传算法以这N个串结构数据作为初始点开始迭代。当然,初始群体应该选取适当,如果选取的过小则杂交优势不明显,算法性能很差,群体选取太大则计算量会过大。
(2)检查算法收敛准则是否满足,控制算法是否结束,也可以采用判断与最优解的适配度或者选定一个迭代次数来结束计算。
(3)适应度评估选择和检测:适应性函数表明个体或解的优劣性,在程序的开始也应该评价适应性,以便和以后的做比较。不同的问题,适应性函数的定义方式也不同。根据适应性的好坏,进行选择。选择的目的是为了从当前群体中选出优良的个体,使它们有机会作为父代为下一代繁殖子孙。遗传算法通过选择过程体现这一思想,进行选择的原则是适应性强的个体为下一代贡献一个或多个后代的概率大。选择实现了达尔文的适者生存原则。
(4)选择:将选择算子作用于群体。选择的目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的。
(5)杂交:按照杂交概率进行杂交。杂交操作是遗传算法中最主要的遗传操作。通过杂交操作可以得到新一代个体,新个体组合了其父辈个体的特性。杂交体现了信息交换的思想。
可以选定一个点对染色体串进行互换,插入,逆序等杂交,也可以随机选取几个点杂交。杂交概率如果太大,种群更新快,但是高适应性的个体很容易被淹没,概率小了搜索会停滞。
(6)变异:按照变异概率进行变异。变异首先在群体中随机选择一个个体,对于选中的个体以一定的概率随机地改变串结构数据中某个串的值。同生物界一样,遗传算法中变异发生的概率很低,但为新个体的产生提供了机会。
变异可以防止有效基因的缺损造成的进化停滞。比较低的变异概率就已经可以让基因不断变更,太大了会陷入随机搜索。不难想象一下,生物界每一代都和上一代差距很大,会出现是怎样一种可怕的情形。
就像自然界的变异适和任何物种一样,对变量进行了编码的遗传算法没有考虑函数本身是否可导,是否连续等性质,所以适用性很强;并且,它开始就对一个种群进行操作,隐含了并行性,也容易找到“全局最优解”。
由上面遗传算法流程图不难看出,遗传算法提供了一种求解复杂系统优化问题的通用框架,计算时不依赖于梯度信息或其它辅助知识,而只需要影响搜索方向的目标函数和相应的适应度函数,不依赖于问题的具体领域,对问题的种类有很强的稳健性,可广泛应用于很多学科。下面是遗传算法的一些主要应用领域。
(1)函数优化:函数优化是遗传算法的经典应用领域,也是对遗传算法进行性能评价的常用算例,特别是对于一些非线性、多模型、多目标的函数优化问题,用其他优化方法较难求解,而遗传算法却可以方便地得到较好的结果;(2)组合优化:随着问题规模的增大,组合优化问题的搜索空间也急剧扩大,实践证明,遗传算法已经在求解旅行商问题、背包问题、装箱问题、布局优化、图形划分问题等各种具有NP难度的问题中得到成功的应用;(3)生产调度问题:车间调度问题是一个典型的NP问题,从最初的传统车间调度问题到柔性作业车间调度问题,遗传算法都有优异的结果显示,在很多算例中都得到了最优解或近优解;(4)自动控制;(5) 机器人学;(6) 图像处理;(7)人工生命;(8)遗传编程;(9)机器学习;(10)数据挖掘等。
随着应用领域的扩展,遗传算法的研究出现了几个引人注目的新动向:(1)基于遗传算法机器学习,这一新的研究课题把遗传算法从历来离散的搜索空间的优化搜索算法扩展到具有独特的规则生成功能的机器学习算法。这一新的学习机制对于解决人工智能中知识获取和知识优化精炼的瓶颈难题带来了希望。(2)遗传算法正日益和神经网络、模糊推理以及混沌理论等其它智能计算方法相互渗透和结合,这对开拓21世纪中新的智能计算技术将具有重要的意义。(3)并行处理的遗传算法的研究十分活跃。这一研究不仅对遗传算法本身的发展,而且对于新一代智能计算机体系结构的研究都是十分重要的。(4)遗传算法和另一个称为人工生命的崭新研究领域正不断渗透。所谓人工生命即是用计算机模拟自然界丰富多彩的生命现象,其中生物的自适应、进化和免疫等现象是人工生命的重要研究对象,而遗传算法在这方面将会发挥一定的作用,(5)遗传算法和进化规划以及进化策略等进化计算理论日益结合。它们几乎是和遗传算法同时独立发展起来的,同遗传算法一样,它们也是模拟自然界生物进化机制的智能算法,即同遗传算法具有相同之处,也有各自的特点。目前,这三者之间的比较研究和彼此结合的探讨正形成热点。
进入二十一世纪,遗传算法迎来了兴盛发展时期,无论是数学理论研究、计算机硬件研发还是应用研究都成了十分热门的课题,尤其是遗传算法的应用研究显得格外活跃,不但它的应用领域扩大,而且利用遗传算法进行优化和规则学习的能力也显著提高。此外一些新的理论和方法在应用研究中亦得到了迅速的发展,这些无疑均给遗传算法增添了新的活力。遗传算法的应用研究已从初期的组合优化求解扩展到了许多更新、更工程化的应用方面,同样也会取得更多新的突破,使得遗传算法的研究更上一层楼。
模糊计算
人们常用“模糊计算”(Fuzzy Computing)笼统地代表诸如模糊系统、模糊语言、模糊推理、模糊逻辑、模糊控制、模糊遗传和模糊聚类等模糊应用领域中所用到的诸多算法及其理论。在这些应用系统中,广泛地应用了模糊集理论,并揉和了人工智能的其他手段,因此模糊计算也常常与人工智能相联系。由于模糊计算可以表现事物本身性质的内在不确定性,因此它可以模拟人脑认识客观世界的非精确、非线性的信息处理能力和亦此亦彼的模糊概念和模糊逻辑。
概念是人类思维的基本形式之一,它反映了客观事物的本质特征。一个概念有它的内涵和外延,内涵是指该概念所反映的事物本质属性的总和,也就是概念的内容;外延是指一个概念所确指的对象的范围。例如“人”这个概念的内涵是指能制造工具,并使用工具进行劳动的动物,外延是指古今中外一切的人。在生产实践、科学实验以及日常生活中,人们经常会遇到诸多模糊概念,如大与小、轻与重、快与慢、动与静、深与浅、美与丑等都包含着一些模糊概念。
美国数学家、控制论专家L.A.Zadeh博士于1965年发表了关于模糊集的论文,首次提出了表达事物模糊性的重要概念——隶属函数(Membership Function)。这篇论文把元素对集的隶属度从原来的非0即1推广到可以取区间[0,1]的任何值,这样用隶属度定量的描述论域中元素符合论域概念的程度,实现了对普通集合的扩展,从而可以用隶属函数表示模糊集。模糊集理论构成了模糊计算系统的基础,人们在此基础上把人工智能中关于知识表示和推理的方法引入进来,或者说把模糊集理论用到知识工程中去就形成了模糊逻辑和模糊推理。为了克服这些模糊系统知识获取的不足及学习能力低下的缺点,又把神经网络计算加入到这些模糊系统中,形成了模糊神经系统。这些研究都成为人工智能研究的热点,因为它们表现出了许多领域专家才具有的能力。同时,这些模糊系统在计算形式上一般多以数值计算为主,也通常被人们归为软计算、智能计算的范畴。
模糊计算在应用上可一点都不模糊,其应用范围非常广泛,它在家电产品中的应用已被人们所接受,如模糊洗衣机、模糊冰箱、模糊相机等。另外,在专家系统、智能控制等许多系统中,模糊计算也都能大显身手,其原因就在于它的工作方式与人类的认知过程有着极大的相似性。
模糊数学(Fuzzy Mathematics),研究现实中许多界限不分明问题的一种数学工具,已广泛应用于模糊控制、模糊识别、模糊聚类分析、模糊决策、模糊评判、系统理论、信息检索、医学、生物学等各个方面。然而模糊数学最重要的应用领域是计算机智能,不少人认为它与新一代计算机的研发有着极其密切的联系。模糊数学基本概念之一是模糊集合,利用模糊集合、模糊矩阵、模糊运算和模糊逻辑等,能很好地处理各个不同领域应用中的模糊问题。
按照经典集合的理论,每一个集合必须由确定的元素构成,元素之于集合的隶属关系是明确的,这一性质可以用特征函数μA(x)来表示,即有:
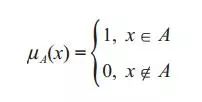
模糊数学把特征函数改写成所谓的“隶属函数μA(x):0≤μA(x)≤1”,在这里A被称为模糊集合,μA(x)为隶属度。经典集合论要求μA(x)取0或1两个值,模糊集合则突破了这一限制,μA(x)=1表示百分之百隶属于模糊集合A,μA(x)=0表示完全不属于模糊集合A,还可以有20%隶属于模糊集合A,80%隶属于模糊集合A,等等,即可取[0,1]区间内的任意值。由于人脑的思维包括精确的和模糊的两个方面,因此模糊数学在人工智能系统模拟人类思维的过程中起到了重要作用,它与新型的计算机设计和许多模糊计算密切相关。
模糊数学的基本思想是隶属度,应用模糊数学建立数学模型的关键是建立符合实际的隶属函数。如何确定一个模糊集的隶属函数至今还是尚未得到很好解决的问题。常用的确定隶属函数的方法有模糊统计法、指派法、专家经验法、二元对比排序法及根据问题的实际意义来确定的方法等。模糊统计方法是一种客观方法,主要是在模糊统计试验的基础上根据隶属度的客观存在性来确定的;指派方法主要依据人们的实践经验来确定某些模糊集隶属函数的一种方法;在实际应用中,用来确定模糊集的隶属函数的方法是多种多样的,主要根据问题的实际意义来确定。譬如,在经济管理、社会管理中,可以借助于已有的“客观尺度”作为模糊集的隶属度。
由于模糊性概念已经找到了模糊集的描述方式,人们运用概念进行判断、评价、推理、决策和控制的过程也可以用模糊性数学的方法来描述。这些方法构成了一种模糊性系统理论,构成了一种思辨数学的雏形,已经在医学、气象、心理、经济管理、石油、地质、环境、生物、农业、林业、化工、语言、控制、遥感、教育、体育等方面取得多方面具体的研究和应用成果。
模糊理论(Fuzzy Theory)是指用到了模糊集合的基本概念或连续隶属度函数的理论,可分为模糊数学,模糊系统,不确定性和信息,模糊决策,模糊逻辑与人工智能众多分支,它们并不是完全独立的,之间存在着紧密的联系,例如,模糊控制就会用到模糊数学和模糊逻辑中的概念。从实际应用的观点来看,模糊理论的应用大部分集中在模糊系统上,尤其集中在模糊控制上,也有一些模糊专家系统应用于医疗诊断和决策支持。
模糊概念(Fuzzy Concept)是指这个概念的外延具有不确定性,或者说它的外延是不清晰的,是模糊的。例如“青年”这个概念,它的内涵我们是清楚的,但是它的外延,即什么样的年龄阶段内的人是青年,恐怕就很难说情楚,因为在“年轻”和“不年轻”之间没有一个确定的边界,这就是一个模糊概念。需要注意的几点:首先,人们在认识模糊性时,是允许有主观性的,也就是说每个人对模糊事物的界限不完全一样,承认一定的主观性是认识模糊性的一个特点。例如,我们让100个人说出“年轻人”的年龄范围,那么我们将会得到数十个不同的答案。尽管如此,当我们用模糊统计的方法进行分析时,年轻人的年龄界限分布又具有一定的规律性;其次,模糊性是精确性的对立面,但不能消极地理解模糊性代表的是落后的事物,恰恰相反,我们在处理客观事物时,经常借助于模糊性。例如,在一个有许多人的房间里,找一位“年老的高个子男人”,这是不难办到的。这里所说的“年老”、“高个子”都是模糊概念,然而我们只要将这些模糊概念经过头脑的分析判断,很快就可以在人群中找到此人。如果我们要求用计算机查询,那么就要把所有人的年龄,身高的具体数据输入计算机,然后我们才可以从人群中找这样的人。最后,人们对模糊性的认识往往同随机性混淆起来,其实它们之间有着根本的区别。随机性是其本身具有明确的含义,只是由于发生的条件不充分,而使得在条件与事件之间不能出现确定的因果关系,从而事件的出现与否表现出一种随机性。而事物的模糊性是指我们要处理的事物的概念本身就是模糊的,即一个对象是否符合这个概念难以确定,也就是由于概念外延模糊而带来的不确定性。
模糊逻辑(Fuzzy Logic)不是二元逻辑——非此即彼的推理,也不是传统意义的多值逻辑,而是在承认事物隶属真值中间过渡性的同时,还认为事物在形态和类属方面具有亦此亦彼性、模棱两可性——模糊性。模糊逻辑善于表达界限不清晰的定性知识与经验,它借助于隶属度函数概念,区分模糊集合,处理模糊关系,模拟人脑实施规则型推理,解决因“排中律”的逻辑破缺产生的种种不确定问题。模糊逻辑模仿人脑的不确定性概念判断、推理思维方式,对于模型未知或不能确定的描述系统,以及强非线性、大滞后的控制对象,应用模糊集合和模糊规则进行推理,表达过渡性界限或定性知识经验,模拟人脑方式,实行模糊综合判断,推理解决常规方法难于对付的规则型模糊信息问题。
模糊系统(Fuzzy System)基于模糊数学理论,能够对事物进行模糊处理。在模糊系统中,元素与模糊集合之间的关系是不确定的,即在传统集合论中元素与集合“非此即彼”的关系不适合模糊逻辑。元素与模糊集合的隶属关系是通过隶属度函数来度量的。当一个元素确定属于某个模糊集合,则这个元素对该模糊集合的隶属度为1;当这个元素确定不属于该模糊集合时,则此时的隶属度值为0;当无法确定该元素是否属于该模糊集合时,隶属度值为一个属于0到1之间的连续数值。模糊系统能够很好处理人们生活中的模糊概念,清晰地表达知识,而且善于利用学科领域的知识,具有很强的推理能力。模糊系统主要应用在自动控制、模式识别和故障诊断等领域并且取得了令人振奋的成果,但是大多数模糊系统都是利用已有的专家知识,缺乏自学习能力,无法对自动提取模糊规则和生成隶属度函数。针对这一问题,可以通过与神经网络算法、遗传算法等自学习能力强的算法融合来解决。目前,很多学者正在研究模糊神经网络和神经模糊系统,这是对传统算法研究和应用的创新。
把模糊概念和一些传统算法及智能算法结合起来,形成了一大批的模糊算法,下面简举几例。
模糊遗传算法(Fuzzy Genetic Algorithm)是指基于模糊逻辑的遗传算法,是当前遗传算法发展的一个新方向。它充分利用了人们对遗传算法已有的知识和经验,并且修正和完善了这些经验,有助于对遗传算法的遗传算子及参数设置与遗传算法性能关系的理解;同时在遗传算法运行过程中,实现了对遗传算法参数或算子的动态调整,保证了整个遗传算法搜索过程中合理的利用性和探索性关系。把模糊逻辑用于遗传算法,是从两个方面着手的:一方面,把已有的关于遗传算法的知识和经验用模糊语言来描述,并用于在线控制遗传操作和参数设置,形成动态遗传算法;另一方面,借鉴模糊逻辑及模糊集合运算的思想,得到模糊编码和相应模糊遗传操作,以改进遗传算法的性能。
模糊聚类算法(Fuzzy Cluster Algorithm)是一种采用模糊数学语言对事物按一定的要求进行描述和分类的数学方法,一般是指根据研究对象本身的属性来构造模糊矩阵,并在此基础上根据一定的隶属度来确定聚类关系,即用模糊数学的方法把样本之间的模糊关系定量的确定,从而客观且准确地进行聚类。聚类就是将数据集分成多个类或簇,使得各个类之间的数据差别应尽可能大,类内之间的数据差别应尽可能小,即为“最小化类间相似性,最大化类内相似性”原则。聚类分析是数理统计中的一种多元分析方法,它是用数学方法定量地确定样本的亲疏关系,从而客观地划分类型。事物之间的界限,有些是确切的,有些则是模糊的。例人群中的面貌相像程度之间的界限是模糊的,天气阴、晴之间的界限也是模糊的。当聚类涉及事物之间的模糊界限时,需运用模糊聚类分析方法。模糊聚类分析广泛应用在气象预报、地质、农业、林业等方面。通常把被聚类的事物称为样本,将被聚类的一组事物称为样本集。模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
模糊数学及其计算的产生不仅拓广了经典数学的基础,而且也是计算机科学向人们的自然机理方面发展的重大突破。它在科学技术、经济发展和社会学等问题的广泛应用领域中显示了巨大的力量,虽然发展的历史并不很长,但已被国内外数学界以及信息、系统、计算机和自动控制科技界人员的普遍关注,具有极其广阔应用前景。
群智能计算
群智能计算(Swarm Intelligence Computing),又称群体智能计算或群集智能计算,是指一类受昆虫、兽群、鸟群和鱼群等的群体行为启发而设计出来的具有分布式智能行为特征的一些智能算法。群智能中的“群”指的是一组相互之间可以进行直接或间接通信的群体;“群智能”指的是无智能的群体通过合作表现出智能行为的特性。智能计算作为一种新兴的计算技术,受到越来越多研究者的关注,并和人工生命、进化策略以及遗传算法等有着极为特殊的联系,已经得到广泛的应用。群智能计算在没有集中控制并且不提供全局模型的前提下,为寻找复杂的分布式问题的解决方案提供了基础。
对一般群智能计算,通常要求满足以下五条基本原则:
邻近原则:群内的个体具有对简单的空间或时间进行计算和评估的能力;
品质原则:群内的个体具有对环境以及群内其他个体的品质作出响应的能力;
多样性原则:群内的不同个体能够对环境中某些变化做出不同的多样反应;
稳定性原则:群内个体的行为模式不会在每次环境发生变化时都发生改变;
适应性原则:群内个体能够在所需代价不高的情况下,适当改变自身的行为模式。
群智能计算现含蚁群算法、蜂群算法、鸡群算法、猫群算法、鱼群算法、象群算法、狼群算法、果蝇算法、飞蛾扑火算法、萤火虫算法、细菌觅食算法、混合蛙跳算法、粒子群算法等诸多智能算法。下面对它们中间常用的一些重要算法进行一些简单介绍。
蚁群算法(Ant Colony Algorithm),受蚂蚁觅食过程及其通信机制的启发,对蚂蚁群落的食物采集过程进行模拟,可用来解决计算机算法中的经典“货郎担问题”,即求出需要对所有n个城市进行访问且只访问一次的最短路径及其距离。
在解决货郎担问题时,蚁群算法设计的虚拟“蚂蚁”将摸索不同路线,并留下会随时间逐渐消失的虚拟“信息素”。虚拟的“信息素”会因挥发而减少;每只蚂蚁每次随机选择要走的路径,它们倾向于选择路径比较短的、信息素比较浓的路径。根据“信息素较浓的路线更近”的原则,即可选择出最佳路线。由于这个算法利用了正反馈机制,使得较短的路径能够有较大的机会得到选择,并且由于采用了概率算法,所以它能够不局限于局部最优解。蚁群算法具有很多特点,简单说来,它是一种自组织的并行算法,具有较强的算法的可靠性、稳健性和全局搜索能力。
蚁群基本算法由三个操作过程组成,它们分别是解构建,信息素更新和后台操作。
(1)解构建:一定数目的虚拟蚂蚁在完全连接图中按照某种规则出发,各自独立地根据信息素和启发式信息,采用一个概率规则选择下一步的移动,直到建立优化问题一个完整的解,并对构成的解进行质量评估。
(2)信息素更新:包括信息素的释放过程和蒸发过程。信息素释放往往根据构成解的质量决定释放量的大小,而信息素蒸发通常是以一个固定比例值衰减所有边上的信息素。整个更新过程一般是在解的构建完成后,但有时也会出现在解构建的每一步中。每条边上信息素的量直接影响蚂蚁对这条边的选择概率,因而信息素的分布情况决定了整个蚁群的搜索空间方向。
(3)后台操作:以灵活的机制执行单独蚂蚁不能完成的宏观操作,如搜集全局信息素情况,采取局部搜索措施等,从而对整个算法的行为进行调控。
以上三个操作过程的结合方式是根据算法设计者考虑问题特征时自由指定的,可以并行、独立、交叉以及同步,从某种程度上来说它们之间是相互作用的。
蚁群算法对于解决货郎担问题并不是最好的方法,但它首先提出了一种解决货郎担问题的新思路;其次,由于这种算法特有的解决方案,已成功用于解决其他组合优化问题,如图着色、最短超串等;最后,通过对蚁群算法进行的精心研究和应用开发,现己被大量应用于数据分析、机器人协作问题求解,也在电力、通信、水利、采矿、化工、建筑、交通等领域得到成功的应用。
蜂群算法(Bee Colony Algorithm)根据蜜蜂各自的分工不同,对蜂群信息共享和交流及进行采蜜活动等的观察和研究,对蜂群的采蜜行为进行计算机模拟,以此找到问题的最优解,是一种基于群智能的全局优化算法。
经过对蜜蜂采蜜机制的观察和研究,可将除蜂王外的整个蜂群的蜜蜂分为三类,即采蜜蜂、观察蜂和侦察蜂,整个蜂群的目标是寻找花蜜量最大的蜜源。在蜂群算法中,采蜜蜂利用先前的蜜源信息采蜜,寻找新的蜜源并与观察蜂分享蜜源信息;观察蜂依据与采蜜蜂分享的信息寻找新的蜜源;侦查蜂的任务是寻找一个新的更有价值的蜜源,它们在蜂房附近随机地寻找蜜源。蜂群算法通过对三类蜜蜂功能的模拟,以寻找最短路径、最大蜜源为目标,用于寻求问题的最优解。
狼群算法(Wolf Colony Algorithm)是基于狼群群体智能,模拟狼群捕食行为及其猎物分配方式,抽象出游走、召唤、围攻三种智能行为以及“胜者为王”的头狼产生规则和“强者生存”的狼群更新机制,提出一种新的群智能算法。算法采用基于狼主体的自下而上的设计方法和基于职责分工的协作式搜索路径结构,通过狼群个体对猎物气味、环境信息的探知、人工狼相互间信息的共享和交互以及人工狼基于自身职责的个体行为决策最终实现了狼群捕猎的全过程模拟。
粒子群算法(Particle Swarm Algorithm)源于对鸟群和兽群捕食行为的研究,基本核心是利用群体中的个体对信息的共享从而使得整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的最优解。
可以利用一个有关粒子群算法的经典描述,对粒子群算法进行直观描述和简要介绍。
设想这么一个场景:一群鸟进行觅食,而远处有一片玉米地,所有的鸟都不知道玉米地到底在哪里,但是它们知道自己当前的位置距玉米地不远。找到玉米地的最佳策略,就是搜寻目前距离玉米地最近的周围区域。粒子群算法就是从这种群体觅食的行为中得到了启示,从而构建的一种优化模型。
在粒子群算法中,把搜索空间中的鸟称之为“粒子”,而问题的“最优解”对应为鸟群要寻找的“玉米地”。所有的粒子都具有一个位置向量(粒子在解空间的位置)和速度向量(决定下次飞行的方向和速度),并可以根据目标函数来计算当前的所在位置的适应值,可以将其理解为距离“玉米地”的距离。在每次的迭代中,群中的粒子除了根据自身的“经验”(历史位置)进行学习以外,还可以根据种群中最优粒子的“经验”来学习,从而确定下一次迭代时需要如何调整和改变飞行的方向和速度,进行逐步迭代,最终整个种群的粒子就会逐步趋于最优解。
粒子群算法的计算步骤如下:
步骤1 种群初始化:可以进行随机初始化或者根据被优化的问题设计特定的初始化方法,然后计算个体的适应值,从而选择出个体的局部最优位置向量和种群的全局最优位置向量。
步骤2 迭代设置:设置迭代次数;
步骤3 速度更新:更新每个个体的速度向量;
步骤4 位置更新:更新每个个体的位置向量;
步骤5 局部位置向量和全局位置向量更新;
步骤6 终止条件判断:判断迭代次数是否达到要求,如满足,输出计算结果;否则继续进行迭代,跳转至步骤3。
在粒子群算法的应用中,主要是对速度和位置向量迭代算子的设计。迭代算子是否有效将决定整个粒子群算法算法性能的优劣,所以如何设计粒子群算法的迭代算子是粒子群算法算法应用的研究重点和难点。
通过上面几个群智能算法的介绍,不难看出,它们一般都具有如下一些特点:群体中相互合作的个体是分布式的,这样更能够适应当前网络环境下的工作状态;没有中心的控制与数据,这样的系统更具有稳健性,不会由于某一个或者某几个个体的故障而影响整个问题的求解;可以不通过个体之间直接通信而是通过非直接通信进行合作,这样的系统具有更好的可扩充性;由于系统中个体的增加而随之增加的开销十分小,系统中每个个体的能力十分简单,这样每个个体的执行时间比较短,并且实现起来也比较简单,具有简单性,在计算机上容易实现编程和并行处理。
此外,需要对群智能算法实行进一步研发和改进,经常遇到的问题有:
从上面已经列出的十多种群智能算法来看,类似性似乎比较多,应按照数学的抽象性、理论性、应用性和计算机程序的编程类似性等进行合理整顿,需要合并的就进行合并,能略去的就略去,更应加强算法收敛性、有效性等的基础研究;
智能算法重在应用,要特别加强已有算法的应用研究,不断扩大应用范围和领域;
对现有的群智能算法在加强理论研究的同时,进行必要的算法改进,提高应用的广泛性和有效性,克服诸如精度不高、收敛速度较慢、容易收敛到局部极小值、多样性下降过快、参数敏感等问题;
进一步寻求更好、更快、更新和更高效的群智能算法。
群智能算法和传统优化算法相比,具有简单、并行、适用性强等优点,它不要求问题连续可微,特别适用于具有高度可重入性、高度随机性、大规模、多目标、多约束等特征的各类典型优化问题求解。但是,由于群体智能计算是一种新兴的理论和算法,其理论基础还不够完善,数学基础相对薄弱,因此,如何提高算法在解空间内的搜索效率,算法收敛性分析与证明以及对算法模型框架本身的研究都需要进行更深入的探索,特别是对群体智能归纳出统一的计算模式和框架建模理念。
群体智能来源于对自然界中生物群体行为的模拟,而智能个体在群体中的行为在很多方面类似于生物群体在自然环境中的生态行为,物种乃至整个生态系统的进化都离不开种群之间的协同作用。因此,可以从自然界中获取很多具有参考意义的科学法则以及相关理论,用来指导群体智能计算模式的研究及其算法改进。如借鉴自然界中种群生态学中的竞争、捕食和协同进化等机制以及自然系统中的混沌现象与机理以及运行规律来进行群体智能计算模式的设计与改进研究,将是一个很有意义的研究领域。
群智能计算因为具有以上诸多特点,虽说研究还处于初级阶段,理论上存在不少缺空,并有诸多困难和问题,但是由于其具有的分布式、自组织、协作性、稳健性和实现简单等特点,在诸如优化问题求解、机器人领域、电力系统领域、网络及通讯领域、计算机领域、交通领域和半导体制造领域等取得了较为成功的应用,为寻找复杂问题的解决方案提供了快速可靠的基础,为人工智能、认知科学等领域的基础理论问题的研究开辟了新的途径。因此,可以预见群智能的研究代表了以后各类算法研究发展的一个重要方向,具有重要意义和广阔的不可忽视的应用前景,会逐渐成为一个新的重要研究方向,值得给予更多的重视。

工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。