Conditional Batch Normalization 详解
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | 尹相楠
来源 | https://zhuanlan.zhihu.com/p/61248211(注:本文封面图误)
Conditional Batch Normalization 的概念来源于这篇文章:Modulating early visual processing by language 。后来又先后被用在 cGANs With Projection Discriminator 和Self-Attention Generative Adversarial Networks 。本文将首先简略介绍
Modulating early visual processing by language ,接着结合 Self-Attention GANs 的 pytorch 代码,详细分析
categorical conditional Batch Normalization 的具体实现。
太长不看版
传统的 Batch Normalization (BN) 公式为:

其中的 



下面将详细介绍 CBN 的来龙去脉。
Modulating early visual processing by language
这篇文章改进了一个基于图片的问答系统 (VQA: Visual Question Answering)。系统的输入为一张图片和一个针对图片的问题,系统输出问题的答案,如下图所示:
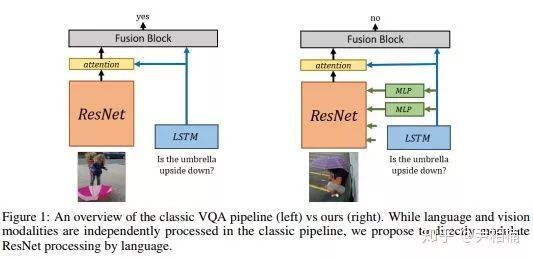
这类系统通常是这样设计的:一个预训练的图像识别网络,例如 ResNet,用于提取图片特征;一个 sequential 模型,例如 LSTM、GRU 等,用于提取句子的特征,并根据句子预测应该关注图片的什么位置(attention);将语言特征、由 attention 加权过后的图片特征结合起来,共同输入一个网络,最终输出问题的答案。
上图左侧为传统的 VQA 系统,我们发现,LSTM 提取的特征只在 ResNet 的顶层才和图片特征结合起来,因为通常意义上讲,神经网络的底层提取的是基础的几何特征,顶层是有具体含义的语义特征,因此,应该把语言模型提取的句子特征在网络顶层和图片特征结合。然而,作者认为,底层的图片特征也应该结合语言特征。理由是,神经科学证明:语言会帮助图片识别。例如,如果事先告诉一个人关于图片的内容,然后再让他看图片,那么这个人识别图片的速度会大大加快。因此,作者首创了将图片底层信息和语言信息结合的模型,如上图右侧所示。
具体是如何结合的呢?首先,ResNet 是预训练的网络,用于提取图片特征,因此不能轻易修改里面 filter 的参数。而其中的 BN 层有两组参数 


这个想法用最小的代价(只修改了 BN 层参数),在图像的底层 feature 中结合了自然语言信息,取得了很好的表现。相关的代码为:
https://github.com/ap229997/Conditional-Batch-Norm/blob/master/model/cbn.py
Categorical Conditional Batch Normalization
在 conditional generative model 里面,存在一个隐隐让人不安的问题:一个 batch 里面不同类别的训练数据,放在一起做 Batch Normalization 不太妥当。因为不同类别的数据理应对应不同的均值和方差,其归一化、放缩、偏置也应该不同。针对这个问题,一个解决方案是不再考虑整个 batch 的统计特征,各个图像只在自己的 feature map 内部归一化,例如采用 Instance Normalization 和 Layer Normalization 来代替 BN。但是这些替代品的表现都不如 BN 稳定,接受程度不如 BN 高。
这时我们想到了上一节中介绍的 conditional BN。CBN 以 LSTM 提取的自然语言特征作为 condition,预测 BN 层参数的增量,达到对不同的输入,都有相对应的归一化参数。既然自然语言特征可以作为 condition,用于预测 BN 参数的变化,那么图片的类别信息自然也可以作为 condition 来预测 BN 层的参数。因此 cGANs With Projection Discriminator 和 Self-Attention GANs 借鉴了 CBN 里面的 condition 的思想,稍加修改,用在了自己的 conditional GAN 模型中。
Modulating early visual processing by language 一文中,由于使用了预训练的 ResNet,不敢对预训练网络 BN 层的参数做大修改,因此 MLP 的输出为 BN 层参数的增量,而不是直接输出新的 BN 层参数。conditional GANs 没有用到预训练网络,因此没有了历史包袱,直接用图片的 categorical 信息,预测新的
接下来我们将研究其具体的实现,代码来自:
https://github.com/crcrpar/pytorch.sngan_projection/blob/master/links/conditional_batchnorm.py
class ConditionalBatchNorm2d(nn.BatchNorm2d):"""Conditional Batch Normalization"""def __init__(self, num_features, eps=1e-05, momentum=0.1,affine=False, track_running_stats=True):super(ConditionalBatchNorm2d, self).__init__(num_features, eps, momentum, affine, track_running_stats)def forward(self, input, weight, bias, **kwargs):self._check_input_dim(input)exponential_average_factor = 0.0if self.training and self.track_running_stats:self.num_batches_tracked += 1if self.momentum is None: # use cumulative moving averageexponential_average_factor = 1.0 / self.num_batches_tracked.item()else: # use exponential moving averageexponential_average_factor = self.momentumoutput = F.batch_norm(input, self.running_mean, self.running_var,self.weight, self.bias,self.training or not self.track_running_stats,exponential_average_factor, self.eps)if weight.dim() == 1:weight = weight.unsqueeze(0)if bias.dim() == 1:bias = bias.unsqueeze(0)size = output.size()weight = weight.unsqueeze(-1).unsqueeze(-1).expand(size)bias = bias.unsqueeze(-1).unsqueeze(-1).expand(size)return weight * output + bias
我们看到,这个 ConditionalBatchNorm2d类,继承自 pytorch 的 BatchNorm2d类,对比这个代码和官方的 BatchNorm2d 的代码,发现其构造函数的参数和BatchNorm2d完全相同,构造函数中直接调用了基类,也就是BatchNorm2d的构造函数。而 forward函数中,多了weight和bias两个参数。forward的代码大部分也是直接 copy 自 BatchNorm2d的基类_BatchNorm的代码,无非是设置一下 moving average 的 momentum,记录一下总共读取了多少个 batch,以便在没有设置 momentum 的情况下,在全体样本上计算均值和方差。直到调用官方的底层 C 函数库 F.batch_norm,代码完全没有对_BatchNorm类的forward函数做出任何修改,其output 就是对输入的 feature map 做了一次 BatchNorm2d。 真正修改的是后面加的几行:
if weight.dim() == 1:weight = weight.unsqueeze(0)if bias.dim() == 1:bias = bias.unsqueeze(0)size = output.size()weight = weight.unsqueeze(-1).unsqueeze(-1).expand(size)bias = bias.unsqueeze(-1).unsqueeze(-1).expand(size)return weight * output + bias
这里用到了forward函数参数中的 weight和bias。由于是在图像 feature 上操作,需要对 weight 和 bias 的维度做一些改变,使其与 feature map output的维度相同。最后代码返回weight*output+bias 。似乎很 naive,可是说好的 condition 呢?说好的 categorical 信息呢?别着急,它们都隐藏在 weight和bias中。这个类只不过是个基类,下面的类才是真正要用到的类:
class CategoricalConditionalBatchNorm2d(ConditionalBatchNorm2d):def __init__(self, num_classes, num_features, eps=1e-5, momentum=0.1,affine=False, track_running_stats=True):super(CategoricalConditionalBatchNorm2d, self).__init__(num_features, eps, momentum, affine, track_running_stats)self.weights = nn.Embedding(num_classes, num_features)self.biases = nn.Embedding(num_classes, num_features)self._initialize()def _initialize(self):init.ones_(self.weights.weight.data)init.zeros_(self.biases.weight.data)def forward(self, input, c, **kwargs):weight = self.weights(c)bias = self.biases(c)return super(CategoricalConditionalBatchNorm2d, self).forward(input, weight, bias)
这个类的构造函数中比它的基类多加了一项num_classes。构造函数中,首先调用了它的基类,也就是ConditionalBatchNorm2d的构造函数,用于初始化大部分参数。接下来设置了两个网络层:
self.weights = nn.Embedding(num_classes, num_features)self.biases = nn.Embedding(num_classes, num_features)
nn.Embedding层的作用是,把图片的 label 转换成 dense 向量,而不像 one-hot-encoding,只能把 label 转换成稀疏向量。nn.Embedding的第一个参数表示总共有多少个类,第二个参数表示每个 label 映射成多少维的向量。这个网络层的好处是,可以任意指定 label vector 的 dimension,它的本质是一个 num_classes行num_feature列的矩阵,这个矩阵的参数随着网络的训练不断更新。前向传播时,label 是几就取第几行的向量出来,用以表示这个 label。其实这个 Embedding 相当于把 one-hot encoding 输入一个 bias 为 0 的 linear layer。
在构造函数的最后,通过调用 self._initialize初始化 self.weights 和 self.bias,分别把它们初始化为全 1 和全 0。这样在网络训练的初期,这俩相当于不存在一样,整个类就是一个BatchNorm2d。
接下来看前向传播函数:
def forward(self, input, c, **kwargs):weight = self.weights(c)bias = self.biases(c)return super(CategoricalConditionalBatchNorm2d, self).forward(input, weight, bias)
这个函数也很简单,输入 feature map input和类别标签c,注意c 应该是 LongTensor 格式的,否则会报错。接下来,根据 c 挑出 weights embedding 层和 biases embedding 层中的第c行,作为 weight 和 bias 输入基类的前向传播函数,最终得到 Conditional Batch Normalization 的输出。这个 categorical condition 发挥作用的阶段,就是 embedding 的阶段。
这个类的实现,对原始 Modulating early visual processing by language 论文做了几点改动:
原始论文中,基于的条件是 LSTM 提取的自然语言信息,而在这里的条件是图片的类别信息。
原始论文中把 LSTM 提取的信息通过两个小神经网络(每个小网络都是 2 层 linear layers,中间夹着一个 ReLU),映射为
和
。这里的 categorical 信息,直接通过 embedding layer 映射到向量,由于 embedding layer 本身相当于一个 one-hot-encoding+linear layer的组合,因此,这里实际上是把原文中的 linear+ReLU+ linear 小网络变成了一层 linear layer,原因大概是,比起自然语言的信息, categorical 信息太稀疏了,没有映射两遍的必要。
原始论文中,MLP 的输出为
和
的增量:
和
。原因上文也提到过,是因为不能轻易改变预训练的 ResNet 中 BN 的参数,只能针对具体的 condition ,在预训练 BN 的参数上做小改。而 Categorical Conditional Batch Normalization 没有历史包袱,可以直接预测
和
。
原始论文中,输出的
和
代入公式(2) 和 BN 参数整合到一起,做一遍映射就好了。而这里,
和
是在原始的 BatchNorm2d映射之后,又做了一遍映射,我猜主要是为了实现起来比较方便,毕竟求 moving average 设置 momentum 这些杂活,实现起来比较麻烦,不如直接借用 pytorch 在 BatchNorm2d里的官方实现。
总结
提出 conditional Batch Normalization 这一思想的论文 Modulating early visual processing by language,是为了解决特定问题:即在预训练 ResNet 提取的图片底层信息中,融合进自然语言信息,用于辅助图片信息的提取。
而后面的 cGANs With Projection Discriminator 和Self-Attention Generative Adversarial Networks 则是利用 condition 的思想,把图片的 categorical 信息用来指导生成 BN 层的映射参数。我们发现,网络训练完成后,同一个类别的图片,将对应同一套 BN 层参数,不同类别的图片,将对应不同的 BN 层参数。
通过这个微小的改动,我们终于可以愉快地在 conditional generative model 上使用 Batch Normalization 操作,而不必担心不同类别的图片对应不同的映射参数了。
*推荐阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~



