轻量attention模块:Spatial Group-wise Enhance
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:李翔
来源:https://zhuanlan.zhihu.com/p/66928045
已获作者授权,请勿二次转载。

论文地址:https://arxiv.org/pdf/1905.09646.pdf
本篇是轻量attention模块的系列之作,它的一个重要的亮点就是同时几乎不增加参数量和计算量的情况下也能让分类与检测性能得到极强的增益。同时,与其他attention模块相比,它是首个利用local与global的相似性作为attention mask的generation source,同时具有非常强的语义表示增强的可解释性。
一句话来概括本文的技术:在每个特征语义组内,利用local与global feature的相似性来指导增强语义特征的空间分布。我们来看核心技术图:
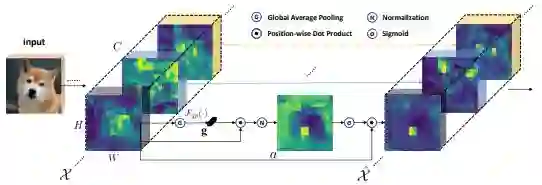
作者为了尽可能让模块轻量,同时又要达到建模目的可谓是煞费苦心,基本上每加一个操作都必须小心翼翼,最后merge出一个基本达到最简的表达,具体操作如下:
首先将特征分组,每组feature在空间上与其global pooling后的feature做点积(相似性)得到初始的attention mask,在对该attention mask进行减均值除标准差的normalize,并同时每个组学习两个缩放偏移参数使得normalize操作可被还原,然后再经过sigmoid得到最终的attention mask并对原始feature group中的每个位置的feature进行scale。
每个SGE模块引入大约2倍组数个参数,组数一般在32或64,这个数量级基本在大几十。相比于百万级别的CNN而言基本上参数量的增加基本可忽略不计。
这么设计的出发点也很容易理解,我们希望能够增强CNN学到的feature的语义分布,使得在正确语义的region,特征能够突出,而在无关语义的region,特征向量能够尽可能接近0。概念上受Capsule等启发,首先我们将特征分组,并认为每组特征在学习地过程中能够捕捉到某一个特定的语义。自然地,我们可以将global的平均feature代表该组学习到的语义向量(至少是接近的,否则该组就都被noise feature dominate了,那我做不做操作都没太大影响)。接下来,我们用每个position的feature与该global feature做点积,那么根据点积的定义,那些本身模长大的feature以及与global feature向量方向接近的feature就会得到一个较大的初始attention mask数值,这也是我们所期望的。因为不同样本在同一组上求得的attention mask分布差异很大,所以我们需要归一到同样的范围来给出准确的attention。最后,每一个location的feature都会scale上最终的0-1之间的数值。该方法的名称也准确地反应了核心操作:我们是group-wise地在spatial上enhance了语义feature的分布。
接下来看这个操作是否真的增强了分布。作者用模长代表响应值,将SGE-ResNet50在第4个stage的图像plot出来:

反正当时将feature对比画出的时候我是震惊了的,尽管只有label的监督,CNN的确非常精准地学习到了一些语义特征,如狗的鼻子,舌头,耳朵,眼睛等等。而且,被SGE增强后的feature map能够更加精准地凸显这些语义区域,完全达到了建模预期的效果。令人惊叹的是,4,7行连闭眼的眼睛SGE都能很好地给capture住。
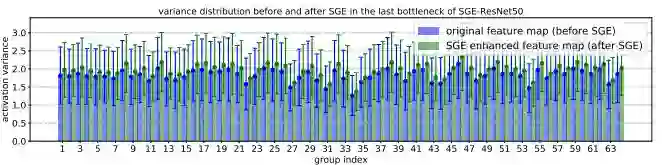
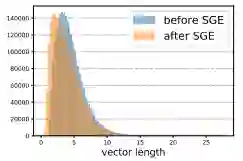
同时,在最高语义层上,SGE在ImageNet validation set所有50k样本上的统计分布完全符合我们的建模预期:更大的variance,较大的激活保留,较小的激活向0偏移:
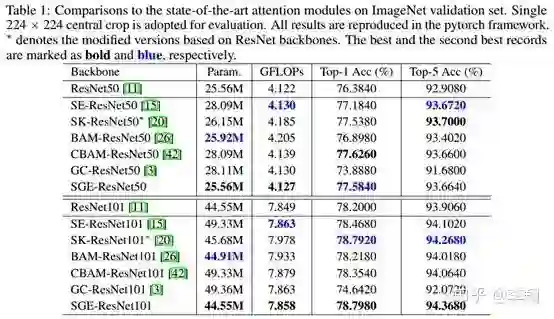
接下来就是一波在ImageNet和COCO上的实验了,为了公平比较,统一用pytorch的框架实现,每个实验都是现跑的。在ImageNet上,用ResNet50,ResNet101做backbone,与state-of-the-art的attention module比,性价比非常可观。
Ablation study告诉我们3个knowledge:
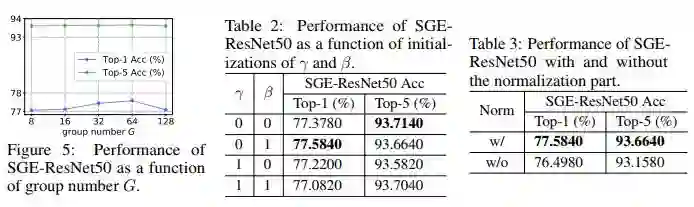
1. Group参数取适中,Top-1性能可到最高;
2. 初始化建议将缩放的参数初始化为0,目的是在attention起到作用前先让网络脱离attention自己学一会,先学习到一个基本的semantic的表示,然后学着学着缩放参数经过梯度下降变成非0之后再渐渐使得attention起到作用;
3. Normalization非常必要,不可去除;
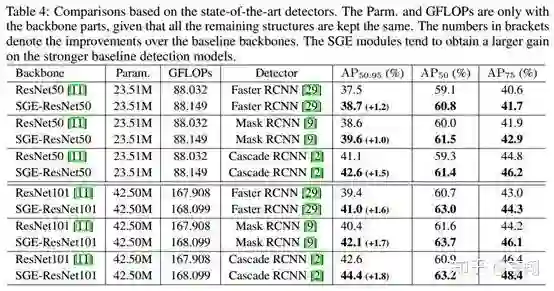
最后是COCO上的实验,首先是在Two-Stage detector上的增益在1~2% AP,相当可观,同时SGE竟然还表现出了遇强则强的状态,在Cascade RCNN的较高的ResNet101的baseline上还能涨接近2个AP:
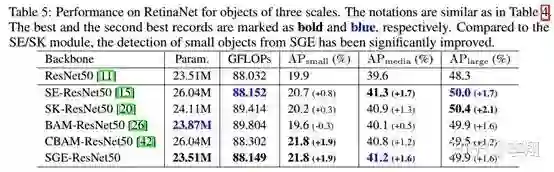
在one-stage的RetinaNet上,在保持media和large与最强的attention module接近的情况下,small object的增益超过了SE/SK 1个点以上,可见其对小区域的空间分布增强带来了非常大的好处。
最后,我们的代码和模型将会陆续放在这里:
https://github.com/implus/PytorchInsight
并且,我们计划把这个工程打造成一个方便大家高效Research的地方,不断更新最新的模型、方法及技术,欢迎star,fork使用~
------------------------------------------------------------
更新:cbam flops 计算小bug更新;detection实验中backbone的Param. Flops严格按照detection设定计算(去掉fc层,使用1333 x 800 的图forward)。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~





