推理速度提升29倍,参数少1/10,阿里提出AdaBERT压缩方法
机器之心发布
机器之心编辑部
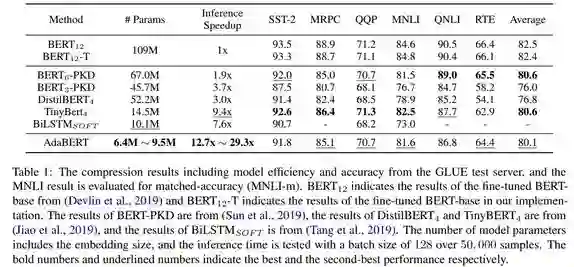
作为当前最佳的自然语言处理模型,BERT 却存在规模大、成本高和实时性差等缺点。为了能在实际应用中部署这种技术,有必要对 BERT 进行压缩。此前机器之心就已经介绍了几种来自不同研究机构的压缩方案,参阅《 内存用量 1/20,速度加快 80 倍,腾讯 QQ 提出全新 BERT 蒸馏框架,未来将开源》和《 AAAI 2020 | 超低精度量化 BERT,UC 伯克利提出用二阶信息压缩神经网络》。

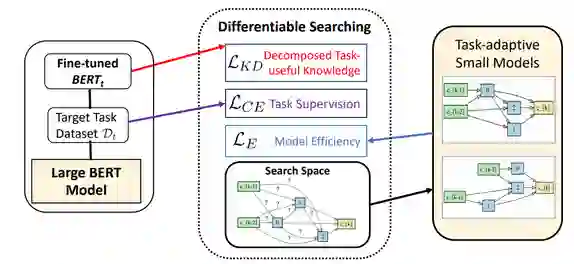
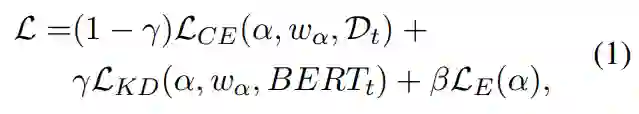
找到对任务有用的知识的探针
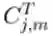 表示 BERT_t 的第 j 层的隐藏表征,用
表示 BERT_t 的第 j 层的隐藏表征,用 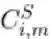 表示压缩后学生模型的第 i 层上通过注意力机制求和的隐藏状态,注入对任务有用的知识(分类 logit)的方式如下:
表示压缩后学生模型的第 i 层上通过注意力机制求和的隐藏状态,注入对任务有用的知识(分类 logit)的方式如下:
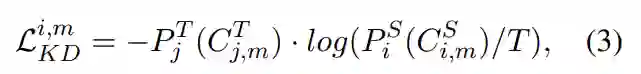
注意力机制的分层迁移
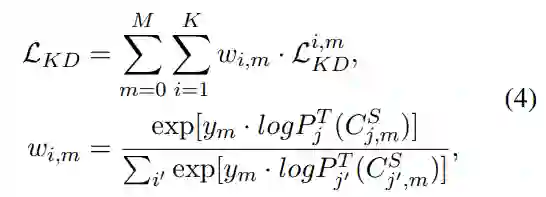
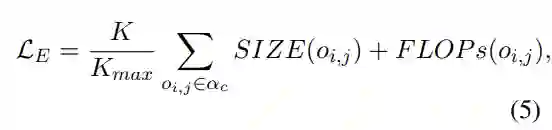
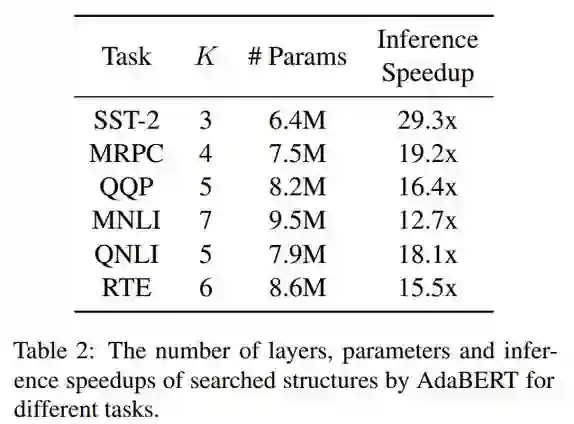
搜索空间设置
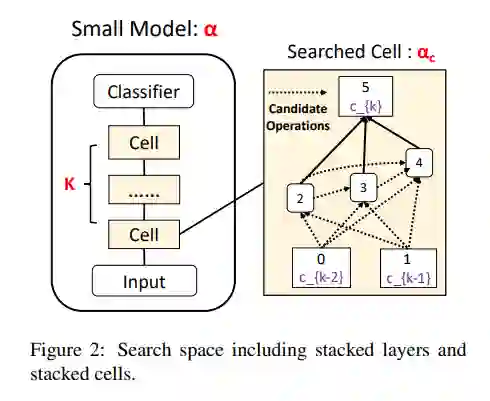
搜索算法
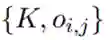 建模为离散的变量,并使其服从离散概率分布
建模为离散的变量,并使其服从离散概率分布 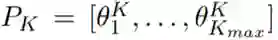 和
和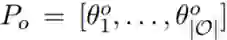 。
。
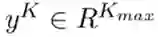 1和
1和 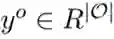 中:
中:
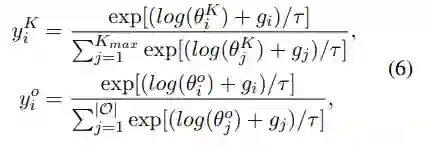
登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
5+阅读 · 2018年4月3日




相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月3日