学界 | 与模型无关的元学习,UC Berkeley提出一种可推广到各类任务的元学习方法
选自BAIR Blog
作者:Chelsea Finn
机器之心经授权编译
参与:路雪、蒋思源
学习如何学习一直是机器学习领域内一项艰巨的挑战,而最近 UC Berkeley 的研究人员撰文介绍了他们在元学习领域内的研究成功,即一种与模型无关的元学习(MAML),这种方法可以匹配任何使用梯度下降算法训练的模型,并能应用于各种不同的学习问题,如分类、回归和强化学习等。

智能的一个关键特征是多面性(versatility):完成不同任务的能力。目前的 AI 系统擅长掌握单项技能,如围棋、Jeopardy 游戏,甚至直升机特技飞行。但是,让 AI 系统做一些看起来很简单的事情,对它们来说反而比较困难。取得 Jeopardy 冠军的程序无法进行对话,专业的直升机特技飞行控制器无法在全新的简单环境中航行,比如定位起火现场、飞过去然后扑灭它。然而,人类可以在面对多种新情况时灵活应对并自发适应。怎样才能使人工智能体获得这样的多面性呢?
人们正在开发多种技术来解决此类问题,我将在本文中对其进行概述,同时也将介绍我们实验室开发的最新技术「与模型无关的元学习」(model-agnostic meta-learning)。
论文地址:https://arxiv.org/abs/1703.03400
代码地址:https://github.com/cbfinn/maml
现在的 AI 系统可以通过大量时间和经验从头学习一项复杂技能。但是,我们如果想使智能体掌握多种技能、适应多种环境,则不应该从头开始在每一个环境中训练每一项技能,而是需要智能体通过对以往经验的再利用来学习如何学习多项新任务,因此我们不应该独立地训练每一个新任务。这种学习如何学习的方法,又叫元学习(meta-learning),是通往可持续学习多项新任务的多面智能体的必经之路。
什么是学习如何学习?它可以应用到哪里呢?
最早的元学习法可以追溯到 20 世纪 80 年代末和 90 年代初,包括 Jürgen Schmidhuber 的理论和 Yoshua、Samy Bengio 的研究工作。最近,元学习再次成为热门话题,相关论文大量涌现,多数论文使用超参数选择(hyperparameter)和神经网络优化(neural network optimization)技术,进而发现优秀的网络架构、实现小样本图像识别和快速强化学习。
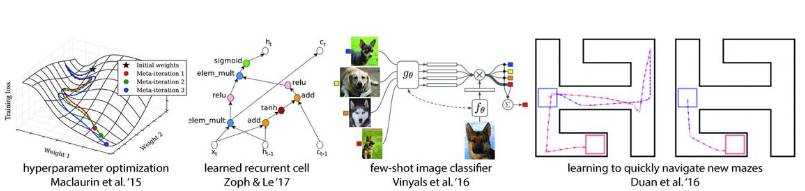
近来多种元学习方法
少次学习(Few-Shot Learning)

2015 年,Brendan Lake 等人发表论文挑战现代机器学习方法,新方法能够从一个概念的一个或多个样本中学习新概念。Lake 举例说,人类能够将上图识别为「奇怪的两轮车」,但机器不能仅根据一张图片泛化一个概念(同样仅展示一个示例,人类就可以从新的字母表中学习到一个字符)。在该论文中,Lake 总结出一组手写字符数据集 Omniglot,它被认为是 MNIST 的「调换(transpose)」,该数据集共有 1623 个字符类,每一类仅仅只有 20 个样本。2015 年国际机器学习大会(ICML)论文中,就有学者分别使用了记忆增强神经网络(memory-augmented neural network)和顺序生成模型(sequential generative model)展示了深度模型能够学会从少量样本中学习,即使目前仍然达不到人类的水平。
元学习方法的运行机制
首先元学习系统会在大量任务中进行训练,然后测试其学习新任务的能力。例如每一个类别给出几个样本,那么元学习是否能在将新的图片正确分类,或者在仅提供一条穿过迷宫的通道时,模型能否学会快速穿过新的迷宫。该方法包括在单个任务上训练和在留出样本上测试,与很多标准机器学习技术不同。
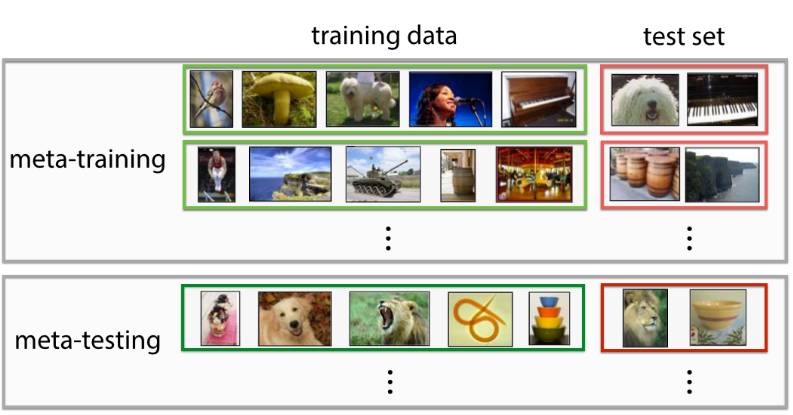
用于少量图像分类的元学习样本
在元学习过程中,模型在元训练集中学习不同的任务。在该过程中存在两种优化:学习新任务的学习者和训练学习者的元学习者。元学习方法通常属于下面三个范畴中的一个:循环模型(recurrent model)、度量学习(metric learning)和学习优化器(learning optimizer)。
循环模型
这种元学习方法训练一个循环模型(即 LSTM),模型从数据集中获取序列输入,然后处理任务中新的输入。在图像分类设置中,这可能包括从(图像、标签)对数据集中获取序列输入,再处理必须分类的新样本。
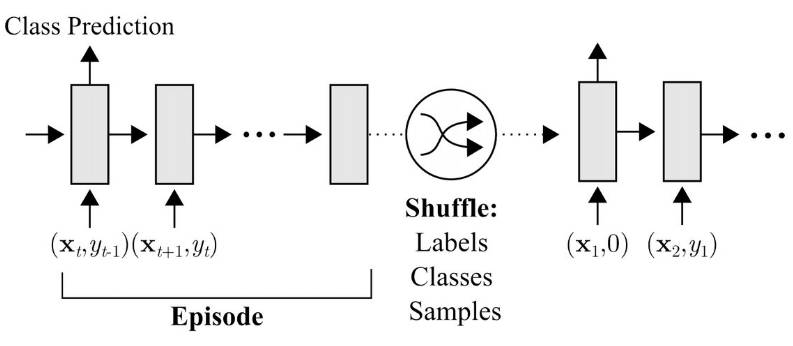
输入 xt 和对应标签 yt 的循环模型
元学习者使用梯度下降,而学习者仅运行循环网络。该方法是最通用的方法之一,且已经用于小样本的分类、回归任务,以及元强化学习中。尽管该方法比较灵活,但由于学习者网络需要从头设计学习策略,因此该方法比其他元学习方法的效率略低。
度量学习
即学习一个度量空间,在该空间中的学习异常高效,这种方法多用于小样本分类。直观来看,如果我们的目标是从少量样本图像中学习,那么一个简单的方法就是对比你想进行分类的图像和已有的样本图像。但是,正如你可能想到的那样,在像素空间里进行图像对比的效果并不好。不过,你可以训练一个 Siamese 网络或在学习的度量空间里进行图像对比。与前一个方法类似,元学习通过梯度下降(或者其他神经网络优化器)来进行,而学习者对应对比机制,即在元学习度量空间里对比最近邻。这些方法用于小样本分类时效果很好,不过度量学习方法的效果尚未在回归或强化学习等其他元学习领域中验证。
学习优化器
最后一个方法是学习一个优化器,即一个网络(元学习者)学习如何更新另一个网络(学习者),以使学习者能高效地学习该任务。该方法得到广泛研究,以获得更好的神经网络优化效果。元学习者通常是一个循环网络,该网络可以记住它之前更新学习者模型的方式。我们可以使用强化学习或监督学习对元学习者进行训练。近期,Ravi 和 Larochelle 证明了该方法在小样本图像分类方面的优势,并表示学习者模型是一个可学习的优化过程。
作为元学习的初始化
迁移学习最大的成功是使用 ImageNet 预训练模型初始化视觉网络的权重。特别是当我们进行新的视觉任务时,我们首先只需要收集任务相关的标注数据,其次在 ImageNet 分类任务中获取预训练神经网络,最后再使用梯度下降在相关任务的训练集中微调神经网络。使用这种方法,神经网络从一般大小数据集中学习新的视觉任务将会变得更有效。然而,预训练模型也只能做到这一步了,因为神经网络最后几层仍然需要重新训练以适应新的任务,所以过少的数据仍会造成过拟合现象。此外,我们在非视觉任务中(如语音、语言和控制任务等)并没有类似的预训练计划。那么我们能从这样的 ImageNet 预训练模型迁移学习过程中学习其他经验吗?
与模型无关的元学习(MAML)
如果我们直接优化一个初始表征,并且该表征能采用小数据样本进行高效的的调参会,那么这样的模型怎么样?这正是我们最近所提出算法的背后想法,即与模型无关的元学习(model-agnostic meta-learning MAML)。像其他元学习方法一样,MAML 需要在各种任务上进行训练。该算法需要学习训练一种可以很快适应新任务的方法,并且适应过程还只需要少量的梯度迭代步。元学习器希望寻求一个初始化,它不仅能适应多个问题,同时适应的过程还能做到快速(少量梯度迭代步)和高效(少量样本)。下图展示了一种可视化,即寻找一组具有高度适应性的参数θ的过程。在元学习(黑色粗线)过程中,MAML 优化了一组参数,因此当我们对一个特定任务 i(灰线)进行梯度迭代时,参数将更接近任务 i 的最优参数θ∗i。
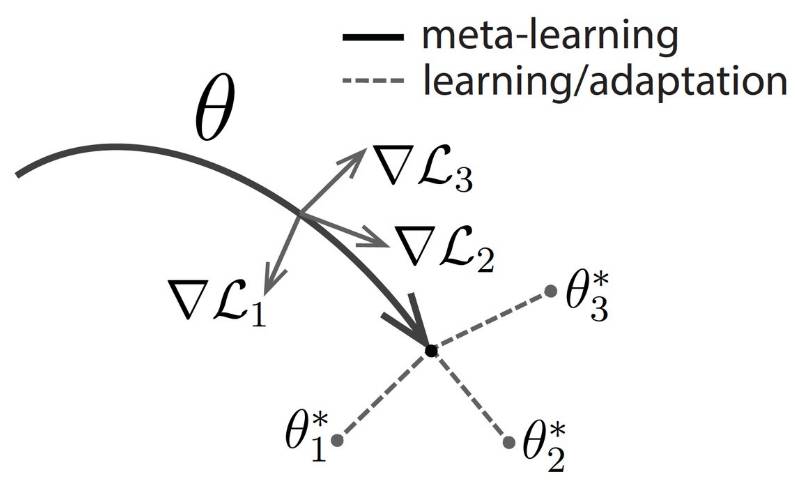
MAML 方法的图解
这种方法十分简单,并且有很多优点。MAML 方法并不会对模型的形式作出任何假设。因此它十分高效,因为其没有为元学习引入其他参数,并且学习器的策略使用的是已知的优化过程(如梯度下降等)而不是从头开始构建一个。所以,该方法可以应用于许多领域,包括分类、回归和强化学习等。
尽管这些方法十分简单,但我们仍惊喜地发现,该方法在流行的少量图片分类基准 Omniglot 和 MiniImageNet 中大幅超越许多已存的方法,包括那些更复杂和专门化的现有方法。除了分类之外,我们还尝试了学习如何将仿真机器人的行为适应到各种目标中,正如同本博客最开始所说的动机,我们需要多面体系统。为此,我们将 MAML 方法结合策略梯度法进行强化学习。如下所示,MAML 可以挖掘到优秀的策略,即令仿真机器人在单个梯度更新中适应其运动方向和速度。


MAML on HalfCheetah


MAML on Ant
该 MAML 方法的普适性:它能与任何基于梯度优化且足够平滑的模型相结合,这令 MAML 可以适用于广泛的领域和学习目标。我们希望 MAML 这一简单方法能高效地训练智能体以适应多种情景,该方法能带领我们更进一步开发多面体智能体,这种智能体能在真实世界中学习多种技能。
论文:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks

论文地址:https://arxiv.org/abs/1703.03400
摘要:我们提出了一种与模型无关的(model-agnostic)元学习算法,它能匹配任何使用梯度下降算法训练的模型,并能应用于各种不同的学习问题,如分类、回归和强化学习等。元学习的目标是在各种学习任务上训练一个模型,因此我们就可以只使用少量的梯度迭代步来解决新的学习任务。在我们的方法中,模型的参数能精确地进行训练,因此少量的梯度迭代步和训练数据样本能在该任务上产生十分优秀的泛化性能。实际上,我们的方法可以很简单地对模型进行参数微调(fine-tune)。我们证明,MAML 方法在两个小规模图像分类基准上有最优秀的性能,在少量样本回归中也产生了非常优秀的性能,同时它还能通过神经网络策略加速策略梯度强化学习(policy gradient reinforcement learning)的微调。

原文地址:http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓




