论文 | 2017CIKM - 迁移学习专题论文分享
导读
ACM CIKM 2017全称是The 26th ACM International Conference on Information and Knowledge Management,是国际计算机学会(ACM)主办的数据库、知识管理、信息检索领域的重要学术会议。
参会归来后,小编邀请了参会的同学与各位读者们第一时间分享了CIKM的参会感受。在接下来的CIKM系列分享中,你将会看到:CIKM最佳论文分享,Network Embedding专题和迁移学习专题。本篇文章是CIKM系列分享的三篇:CIKM 迁移学习专题分享。(CIKM其他系列分享请参考本周二、周三的推送。)
Transfer learning (迁移学习,以下简称TL),有时也称为domain adaptation,是机器学习主流的技术之一。TL的核心思想是从一个有很多标注数据的源领域里学习一些知识来帮助一个标注数据不多的目标领域。TL在工业界有很大的需求,因为大量新的应用场景不断涌现。传统的机器学习需要对每个场景积累大量训练数据,这将会耗费大量的人力与物力。如果我们能利用好现有的训练数据去帮助学习新的场景的学习任务将会大大减少标注的资源。香港科技大学教授、人工智能和数据挖掘专家杨强在TL领域有非常大的贡献,这次他的CIKM2017 keynote就是关于TL怎么和近几年大火的DL(深度学习)结合的。
PS.完整的keynote的ppt,请关注本账号“蚂蚁金服科技”后在后台回复“CIKM”即可收到!
值得一提的是,斯坦福的教授吴恩达(Andrew Ng)认为下一个机器学习成功的应用将是由TL来驱动的:「TL will be the next driver of ML sucess」。
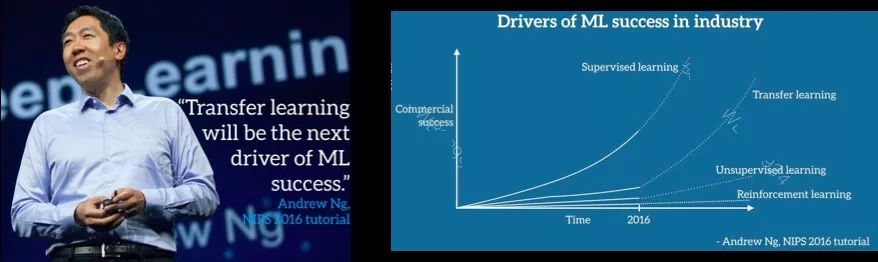
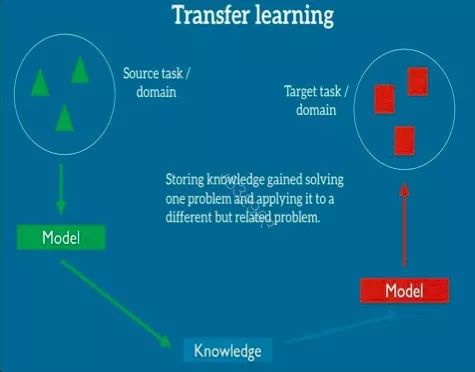
Why TL is hard? TL的最大挑战是如何学习出源领域和目标领域共同的knowledge(知识),这个knowledge需要具有很好的领域的适应性。
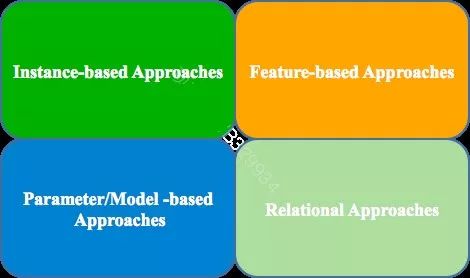
通常来说有以下四类TL算法:
样本迁移(Instance based TL)
这里需要在源域中找到与目标域相似的数据,然后调整这个数据的权重在和目标域混合训练。这里的假设是,源域和目标域可能有部分重叠,找出这些重叠的部分可以帮助学习目标域。下个例子就是找到源域的例子3来帮助目标域的学习。这个方法比较简单,但是不适合源域与目标域分布不一致的情况。

特征迁移(Feature based TL)
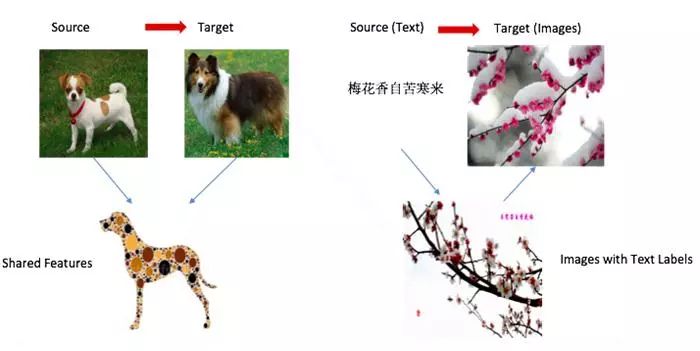
这里假设源域和目标域有一些交叉特征,通过映射可以把源域和目标域放到相同的空间,在这个新的空间里再进行传统的机器学习。这个优点是方法比较通用,效果也不错,但是特征映射比较难,容易过拟合。下图1就是可以从两种类型的狗里面抽象出狗的一些特征,用来帮助目标领域的学习。
模型迁移(Parameter based TL)
这里通常是把一个领域训练好的模型用到新的领域,这个时候可能需要新的领域的样本就比较少。再一些图片的分类场景,大家用imagenet训练好的模型来finetune,通常finetune最后几层就可以达到不错的效果。这个方法可以充分利用模型之间的相似性,但是主要问题是不容易收敛。
关系迁移(Relation based TL)
这里假设源域和目标域是相似的,可以将源域学到的一些逻辑关系用到目标域。
近年来随着DL(深度学习)的火热,越来越多的研究开始关注DL和TL的结合。深度学习,也被称为representation learning,是个非常有效的feature representation方法。所以DL和TL的结合很自然的是在feature based TL的基础上的。下面我们会重点讲述一下这几类工作:supervised TL, unsupervised TL,和Transitive Transfer Learning。
Supervised TL: Feature learning
[Deep Adaptation Networks (DAN) Long et al. 2015] 这个论文展示了一个fully-shared的TL模型,也是最常用的一种TL模型,基本idea是用一个NN学一个shared representation,然后对于源领域和目标领域各自训练一个分类器来学习各自的label。他们还提出了一个MK-MMD来学习最后一层的domain difference。整体结构如下:
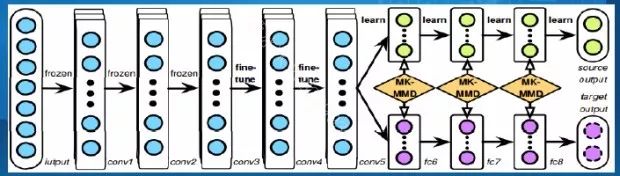
[Yosinski, Jason, et al. "How transferable are features in deep neural networks?."NIPS. 2014.] 这篇文章详细的分析了对于DL来说,哪些特征是可以transfer的,哪些特征是不可以transfer的。基本的idea是,对于DL来说,底层学习的是一些通用或者基础的特征,高层学的特征比较高级,抽象,通常来说越高层学到的信息越和domain相关。所以对于DL来说,我们通常把底层的特征share,最后的几层的特征分开学。这个和上面讲的fully-shared TL模型的思路是一致的。
Unsupervised Deep TL
这类方法假设没有目标领域的标注。这里需要优化的是源领域的loss(有标注)和目标领域的差异(目标领域和源领域的差异),然后把源领域的模型直接用在目标领域。整体的优化目标如下:
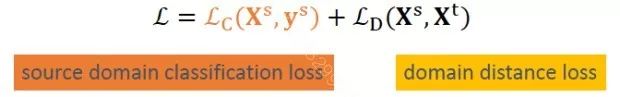
考虑domain loss常用的方式是计算domain间的相似度,有以下几个工作:

另外,也可以用一个domain discrimninator去区别不同domains,同时用adversarial loss去学习一个common features。详见这几个工作: [Ganinetal.2015, Tzengetal.2015, Liu and Tuzel2016, Tzeng et al.2017]. 还有一种是build一个reconstruction loss, 相当于加了一个autoencoder,详见[Ghifaryet al. 2016,Bousmaliset al.2016]。
Transitive Transfer Learning
Transitive TL (传递性迁移学习)是指,如果两个domain之间如果相隔得太远,那么我们就插入一些intermediate domains,一步步做迁移。传统迁移学习就好比是踩着一块石头过河,传递迁移学习就好比是踩着连续的两块石头。更进一步,远领域迁移学习Distant domain transfer learning,这就好比是踩着一连串石头过河。传统迁移学习只有两个领域足够相似才可以完成,而当两个领域不相似时,传递迁移学习却可以利用处于这两个领域之间的若干领域,将知识传递式的完成迁移。
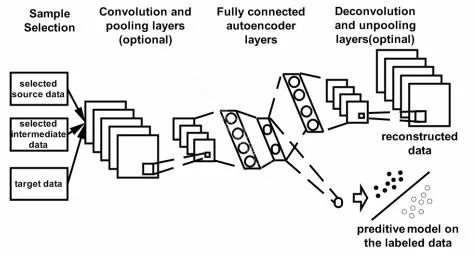
[Distant Domain TL, Ben Tan, et al., AAAI 2017] 这篇文章核心的idea就是通过reconstruction loss来选出好的source和intermediate data,然后把source, intermediate, target三个领域的数据合起来用一个shared的模型来拟合结果。这里的reconstruction是通过autoencoder来做的。Instance selection loss:
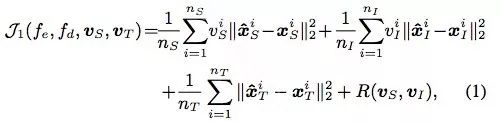
这个是instance selection需要优化的loss,其中:
v是binary的,表示该数据有没有被选中。
第一项和第二项表示的是选中的source和intermediate数据的reconstruction loss。
第三项是target的reconstruction loss。
最后一项是为了是的选的source和intermediate数据越多越好,具体计算公式如下。
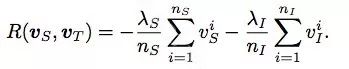
Incorporation of Side Information: 通过J1可以选出好的source和intermediate数据,然后reconstruction没有考虑source和target的labels,所以使用J2来计算这部分的loss。
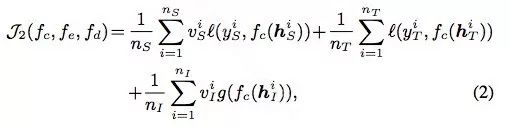
第一项是source data的classification loss,第二项是target的。
第三项是intermediate的,由于这部分没有label,第三项是用来选出高置信度的intermediate data。
最后J1和J2可以通过block coordinate descent (BCD)来优化,简单来说就是不断重复下面两步:
fix v,用BP优化模型参数。
fix模型参数,优化v。
模型的框架如下:
Reference
A Survey on Transfer Learning, Sinno Jialin Pan and Qiang Yang. In IEEE Transactions on Knowledge and Data Engineering (IEEE TKDE). Volume 22, No. 10, Pages 1345-1359, October 2010.
https://www.qcloud.com/community/article/952504
http://www.xtecher.com/Xfeature/view?aid=7383(请将网址复制至浏览器中打开即可查看)
— END —
推荐阅读




