CVPR 2022 Oral | MetaFormer:证明Transformer的威力源自其整体架构!颜水成团队工作!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

MetaFormer is Actually What You Need for Vision
论文地址:
https://arxiv.org/abs/2111.11418
GitHub仓库:
https://github.com/sail-sg/poolformer
Transformer在计算机视觉任务中显示出了巨大的潜力。一个普遍的观念就是,基于注意力的
token mixer module对Transformer的贡献最大。然而,最近的研究表明,Transformer中基于注意力的模块可以被spatial MLPs所取代,并且所得到的模型仍然表现得很好。基于这一结果,作者假设,Transformer的一般架构对模型来说更为重要,而不是特定的
token mixer module。为了验证这一假设,作者故意将Transformer中的注意力模块替换为简单空间池化操作,以便只进行最基本的token mixer。令人惊讶的是PoolFormer在多个计算机视觉任务上都取得了具有竞争力的性能。例如,在ImageNet-1K上,PoolFormer达到了82.1%的Top-1精度,超过了DeiTB/MLP-B240.3%/1.1%,参数减少了35%/52%,mac减少了48%/60%。PoolFormer的有效性验证了作者的假设,并敦促启动
MetaFormer的概念,这是一种从Transformer中抽象出来的一般架构,没有指定的token mixer。基于大量的实验,作者认为
MetaFormer是为最近的Transformer和类似MLP的视觉任务模型获得优越结果的关键。这项工作需要更多的未来研究,致力于改进MetaFormer,而不是专注于token mixer module。此外,作者提出的PoolFormer可以作为未来MetaFormer设计的Baseline。
1说在前面
为什么学MetaFomer这个模型?
小编其实一直在寻找一个精度与速度都很nice的变形金刚,当我在看李沐大神的Transformer课程的时候,听到介绍MetaFormer,我们都知道范式革命者和提出者都是伟大的,MetaFormer毫无意外就是范式的提出者,其使用pool操作代替了非常耗费算力的MSA,你敢想象吗?作者自己都称之为'Embarrassingly Simple',这多么骚气,不用想我们都知道pool没有参数学习,计算量是真的小,还说什么呢!肝吧!
下面我们就开始吧,不要错过这个文章,MetaFormer也是CVPR2022的Oral作品,值得反复学习的。文末小编也针对ResNet与MetaFormer的推理速度进行了对比。
2简介
Transformer已经在计算机视觉领域的中获得了极大的影响和成功。由于ViT的开创性工作,使Transformer适应图像分类任务,同时许多后续模型也被开发出来,并在各种计算机视觉任务中取得良好的性能。
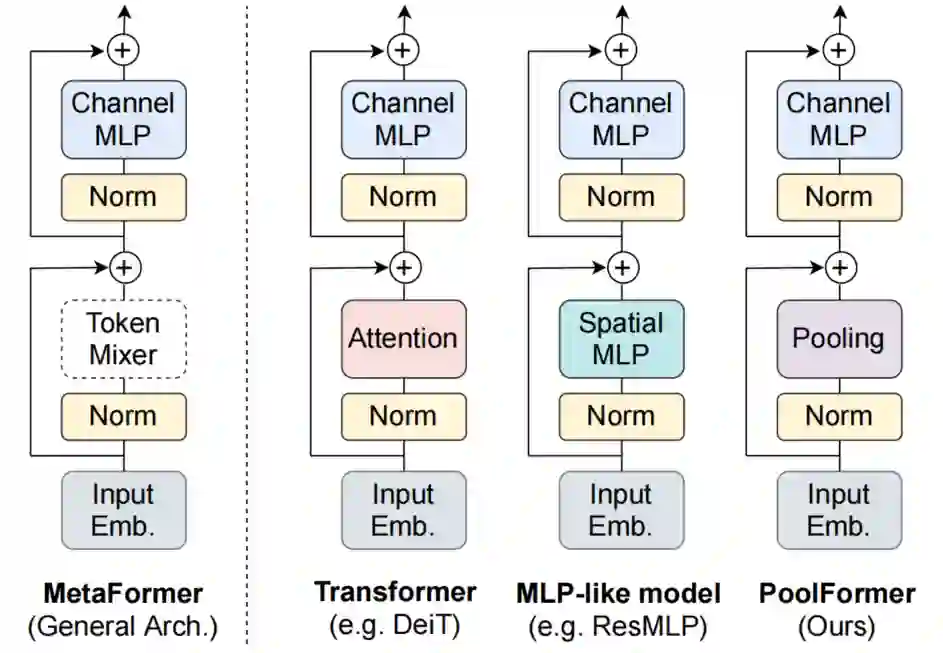
如图1(a)所示,通过不指定
token mixer,将MetaFormer作为从Transformer中抽象出来的通用架构。当使用注意力/空间MLP作为token mixer时,MetaFormer被实例化为Transformer/MLP-like的模型。作者认为,Transformer/MLP-like模型的性能优势主要来自通用架构
MetaFormer,而不是配备的特定的token mixer。
如图1(a)所示,Transformer编码器由2个组件组成:
一个组件是在token之间混合信息的注意力模块,将其命名为 token mixer。另一个组件包含残差的模块,如通道mlp和残差连接。
通过将注意力模块视为一个特定的token mixer,作者进一步将整个Transformer抽象为一个通用架构MetaFormer,其中没有指定token mixer。
Transformer的演变长期以来一直归功于基于注意力的token mixer。基于这一普遍的观念,许多注意力模块的变体已经被开发出来,以改善Vision Transformer。然而,最近的一项工作使用Spatial MLPs完全取代了基于注意力模块的作为token mixer,并发现衍生的MLP-like模型可以很容易地在图像分类基准上获得具有竞争力的性能。后续的工作通过数据高效的训练和特定的MLP模块设计,进一步改进了MLP-like模型,逐渐缩小了与ViT的性能差距,并挑战了基于注意力的token mixer的主导地位。
最近的一些方法探索了MetaFormer体系结构中其他类型的token mixer,并表现出了令人鼓舞的性能。例如,FNet用傅里叶变换代替了注意力,并且仍然达到了标准Transformer的97%左右的精度。综合所有这些结果,似乎只要一个模型采用MetaFormer作为一般的体系结构,就可以获得很好的结果。因此,作者假设,与特定的token mixer相比,MetaFormer对于模型实现竞争性能更为重要。
为了验证这一假设,作者应用了一个非常简单的非参数算符,池化,作为token mixer来进行最基本的token混合。如图1(b),PoolFormer实现了具有竞争力的性能,甚至性能始终优于Transformer和MLP-Like模型,包括DeiT和ResMLP。

所示更具体地说,Poole-m36在ImageNet-1k分类基准上达到了82.1%的Top-1精度,分别超过DeiT/MLP-B24B 0.3%/1.1%,同时参数减少了35%/52%,mac减少了48%/60%。
这些结果表明,MetaFormer即使使用一个简单的token mixer,仍然可以提供良好的性能。因此,作者认为,token mixer值得未来进行更多的研究。
本文的贡献主要有2个方面:
-
首先,将Transformer抽象为一个通用的
MetaFormer,并通过经验证明了Transformer/MLP-Like模型的成功很大程度上归因于MetaFormer结构。具体地说,通过只使用一个简单的非参数池化算子作为一个极弱的token mixer,建立了一个简单的模型,发现它仍然可以获得具有很高竞争力的性能。作者希望这个发现能激发更多的研究,致力于改进MetaFormer,而不是专注于token mixer模块。 -
其次,对图像分类、目标检测、实例分割和语义分割等多个视觉任务上的PoolFormer进行了评估,发现其与精心设计
token mixer的SOTA模型相比具有良好的性能。PoolFormer可以很容易地作为未来MetaFormer架构设计的一个良好的起始Baseline。
3相关工作
Transformer最初是在Attention is all you need这篇文章中提出的,主要用于翻译任务,然后迅速在各种NLP任务中流行起来。在语言预训练任务中,Transformer在大规模的无标记文本语料库上进行训练,实现了惊人的性能。受Transformer在NLP中的成功的启发,许多研究者将注意力机制和Transformer应用到视觉任务中。值得注意的是,Chen等人引入了iGPT,其中训练Transformer来自动回归预测图像上的像素,以进行自监督学习。
Dosovitskiy等人提出了以Hard Patches Embedding作为输入的Vision Transformer(ViT)。ViT的实验结果表明,在有监督图像分类任务中,在一个大型数据集(JFT数据集)上预训练的ViT可以获得优异的性能。
DeiT和T2T-ViT进一步证明,仅在ImageNet-1K(∼130万张图像)上进行预训练的ViT可以也获得良好的性能。
现在有许多工作都集中在通过移动窗口、相对位置编码、细化注意力图或合并卷积等来改进Transformer的token mixer方法上。除了类似注意力的token mixer外,仅仅采用mlp作为token mixer仍然可以实现具有竞争力的性能。这一发现挑战了基于注意力的token mixer的主导地位,并在研究界引发了关于哪种token mixer是更好的的激烈讨论。
然而,这项工作的目标既不是参与这场辩论,也不是设计新的复杂的token mixer来实现新的技术状态。相反,本文研究了一个基本的问题:什么才是真正给Transformer及其变体带来成功的原因?作者的答案是一般的架构MetaFormer。作者简单地利用池化操作作为基本的token mixer来探测MetaFormer的能力。
与此同时,一些工作也有助于回答同样的问题。Dong等人证明了在没有残差连接或MLPs的情况下,输出以双指数收敛于秩1矩阵。Raghu等人比较了ViT和CNN之间的特征差异,发现自注意力使全局信息很快聚集,而残差连接可以很快地从lower到higher层继续宁特征传播。不幸的是,它们既没有将Transformer抽象为一般架构,也没有明确解释Transformer性能优秀的原因。
4本文方法
4.1 MetaFormer
首先提出这项工作的核心概念MetaFormer。如图1所示,从Transformer中抽象出来,MetaFormer是一种通用架构,其中没有指定token mixer,而其他组件与Transformer保持相同。输入I首先通过输入Patch Embedding进行处理,比如ViTs的Patch Embedding:
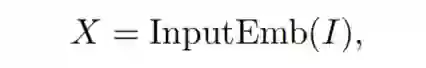
其中,
表示序列长度为N、Embedding维数为C的Embedding token。
然后,将Embedding token输入重复的MetaFormer blocks,每个Block包含2个residual sub-blocks。
第1个sub-block
具体地说,第1个sub-block主要包含一个在token之间通信信息的token mixer,该sub-block可以表示为:
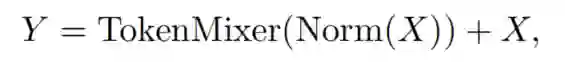
其中,Norm(·)表示Normalization,如层Layer Normalization或Batch Normalization;
TokenMixer(·)是指一个主要用于token mixer信息的模块。它是通过最近的Vision Transformer或spatial MLP模型中的各种注意力机制实现的。
请注意,
token mixer的主要功能是传播token信息,尽管一些token mixer也可以混合通道,比如注意力。
第2个sub-block
第2个sub-block主要由一个具有非线性激活的双层MLP组成:
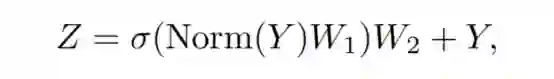
其中 和 是MLP展开比 的可学习参数; 是一个非线性激活函数,如GELU或ReLU。
MetaFormer的实例化
MetaFormer描述了一种通用的体系结构,通过指定token mixer的具体设计,可以立即获得不同的模型。如图1(a)所示,如果token mixer被指定为注意力或Spatial MLP,那么MetaFormer分别成为Transformer或MLP-Like模型。
4.2 PoolFormer
从Transformer的引入开始,许多工作都非常重视注意力,并专注于各种基于注意力的token mixer组件的设计。相比之下,这些作品很少关注一般的架构,即MetaFormer。
在这项工作中,作者认为这种MetaFormer的通用架构主要有助于最近的Transformer和MLP-Like的模型的成功。为了演示它,作者故意使用了一个简单的池化操作作为token mixer。这个操作符没有可学习的参数,它只是使每个token平均聚合其附近的token特征。
由于这项工作是针对视觉任务的,假设输入是通道优先的数据格式,即 。池化运算符可以表示为:
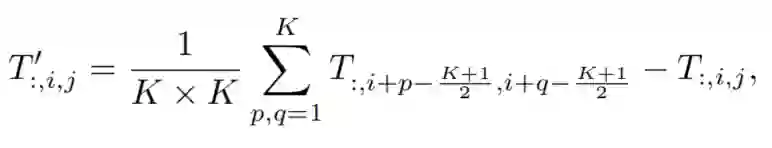
其中,K是pooling size。由于MetaFormer blocks已经有了一个残差连接,因此在上式中删除了输入本身相加的做法。
算法1显示了池化的Pytorch代码:

对应的Pytorch实现如下:
class Pooling(nn.Module):
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
众所周知,自注意力和Spatial MLP的计算复杂度与要混合的token的数量呈二次关系。更糟糕的是,Spatial MLP在处理更长的序列时带来了更多的参数。因此,自注意力和Spatial MLP通常只能处理数百个token。相比之下,pool仅仅需要线性的计算复杂度同时还没有任何可学习的参数。
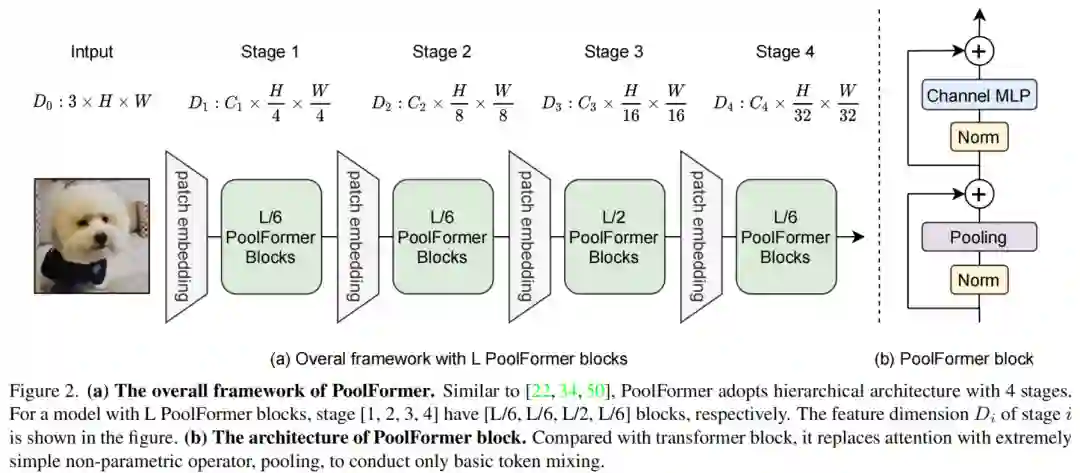
因此,通过采用类似于传统CNNs和最近的分层Transformer的分层结构来利用pool。图2显示了PoolFormer的整体框架。
具体来说,前者有4个阶段,分别有 、 、 和 的token,其中H和W代表输入图像的宽度和高度。
Embedding size分为2组:
Small-size model 4个阶段的 Embedding size分别为64、128、320、512;Medium-sized model 4个阶段的 Embedding size为96、192、384、768。
假设总共有L个PoolFormer blocks,则Stage-1、2、3、4将分别包含L/6、L/6、L/2和L/6个PoolFormer blocks。MLP膨胀比设为4。
PoolFormer blocks的Pytorch实现如下:
class PoolFormerBlock(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4., act_layer=nn.GELU, norm_layer=GroupNorm, drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers, pool_size=3, mlp_ratio=4., act_layer=nn.GELU, norm_layer=GroupNorm, drop_rate=.0,
drop_path_rate=0., use_layer_scale=True, layer_scale_init_value=1e-5):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PoolFormerBlock(dim, pool_size=pool_size, mlp_ratio=mlp_ratio, act_layer=act_layer,
norm_layer=norm_layer, drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value,))
blocks = nn.Sequential(*blocks)
return blocks
根据上述简单的模型比例规则,得到了5种不同的PoolFormer的模型尺寸,其超参数如表所示:
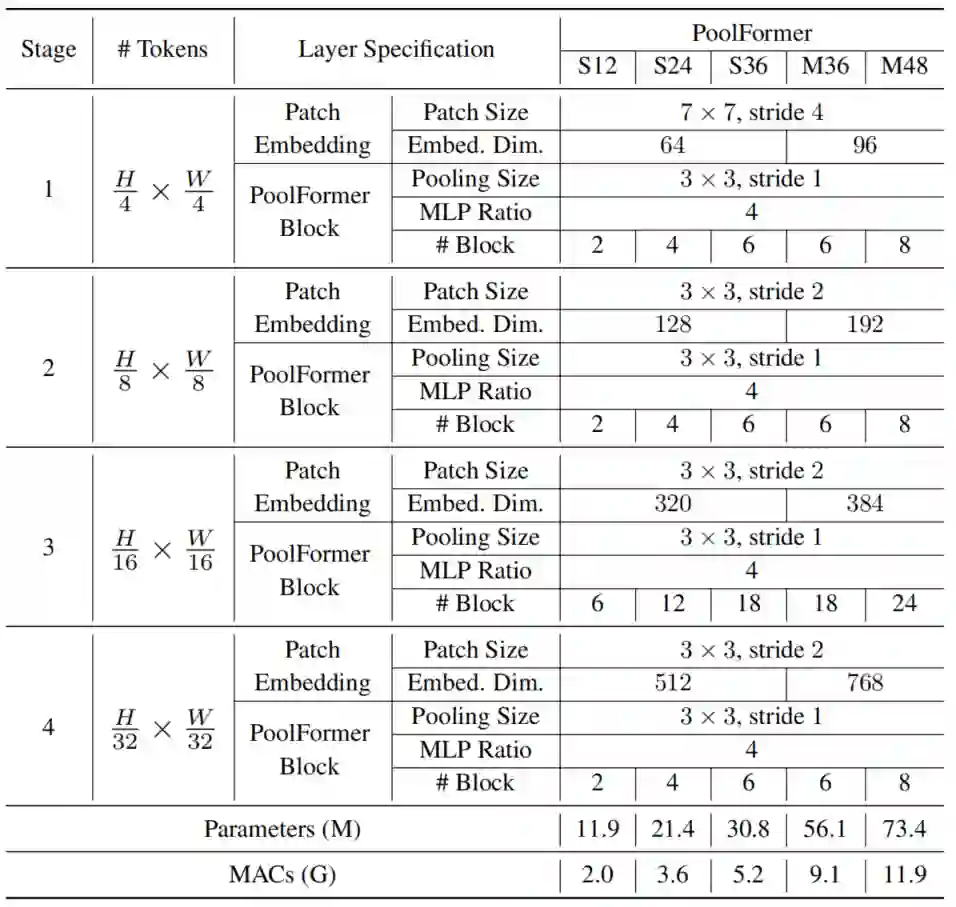
不同配置的模型Pytorch实现如下:
def poolformer_s12(pretrained=False, **kwargs):
"""
PoolFormer-S12 model, Params: 12M
--layers: [x,x,x,x], numbers of layers for the four stages
--embed_dims, --mlp_ratios:
embedding dims and mlp ratios for the four stages
--downsamples: flags to apply downsampling or not in four blocks
"""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, **kwargs)
model.default_cfg = default_cfgs['poolformer_s']
return model
def poolformer_s24(pretrained=False, **kwargs):
"""
PoolFormer-S24 model, Params: 21M
"""
layers = [4, 4, 12, 4]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, **kwargs)
model.default_cfg = default_cfgs['poolformer_s']
return model
def poolformer_s36(pretrained=False, **kwargs):
"""
PoolFormer-S36 model, Params: 31M
"""
layers = [6, 6, 18, 6]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, layer_scale_init_value=1e-6, **kwargs)
model.default_cfg = default_cfgs['poolformer_s']
return model
def poolformer_m36(pretrained=False, **kwargs):
"""
PoolFormer-M36 model, Params: 56M
"""
layers = [6, 6, 18, 6]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, layer_scale_init_value=1e-6, **kwargs)
model.default_cfg = default_cfgs['poolformer_m']
return model
def poolformer_m48(pretrained=False, **kwargs):
"""
PoolFormer-M48 model, Params: 73M
"""
layers = [8, 8, 24, 8]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, layer_scale_init_value=1e-6, **kwargs)
model.default_cfg = default_cfgs['poolformer_m']
return model
5实验
5.1 消融实验
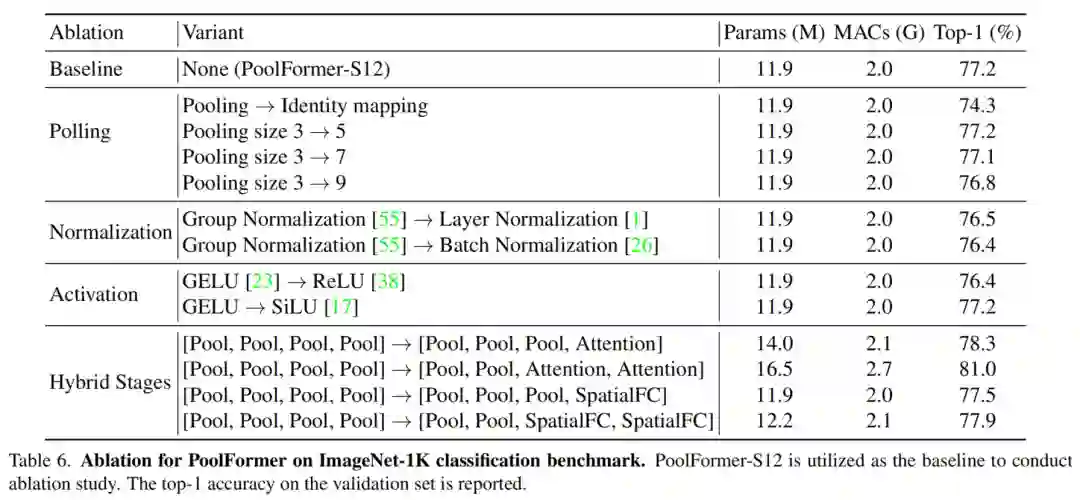
1、Pooling
与Transformer相比,PoolFormer所做的主要改变是使用简单的pool操作作为token mixer。首先通过直接用identity mapping替换pool来对该操作符进行消融。令人惊讶的是,带有identity mapping的MetaFormer仍然可以达到74.3%的Top-1准确率,这支持了MetaFormer实际上是保证合理性能的说法。
作者还测试了pooling size对PoolFormer的影响。当pooling size分别为3、5和7时,可以观察到类似的性能。然而,当pooling size增加到9时,性能明显下降了0.5%。因此,采用默认的pooling size为3。
2、Normalization
PoolFormer采用3种Normalization,分别是Group Normalization、 Layer Normalization和Batch Normalization。
作者发现PoolFormer更倾向于Group Normalization,Group Normalization分别比 Layer Normalization和Batch Normalization高0.7%或0.8%。因此,Group Normalization被设置为PoolFormer的默认Normalization。
3、Activation
作者将GELU更改为ReLU或SiLU。当采用ReLU进行激活时,其性能明显下降了0.8%。对于SiLU,其性能几乎与GELU相同。因此,仍然采用GELU作为默认激活函数。
4、Hybrid stages
在基于池化、Attention和Spatial MLP的token mixer中,基于池化的token mixer可以处理更长的输入序列,而Attention和Spatial MLP则善于捕获全局信息。因此,考虑到序列已经被大部分缩短,在lower阶段使用池化来处理长序列,在higher阶段使用注意力或基于Spatial MLP的mixer是很直观的。因此,在PoolFormer的前1个或1个阶段用自注意力或Spatial FC取代token mixer pool。
从表6中可以看出,Hybrid模型表现得相当好。在最后2个阶段的集中和在前2个阶段的注意力提供了高度具有竞争力的性能。仅使用16.5M参数和2.7G mac,准确率达到81.0%。
5.2 分类实验
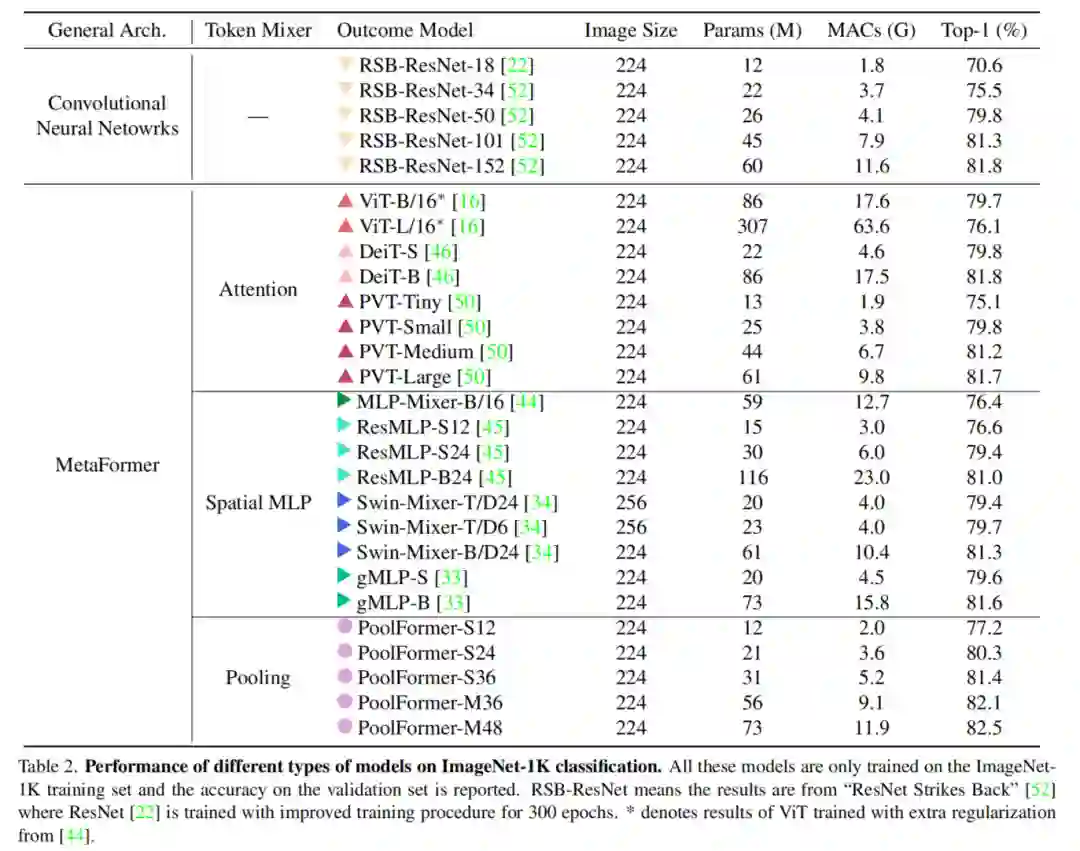
上表显示了PoolFormer在ImageNet分类上的性能。令人惊讶的是,尽管使用了简单的pool token mixer,但与CNN和其他MetaFormer-like的模型相比,PoolFormer仍然可以实现具有高度竞争力的性能。
例如,PoolForter-S24的最高精度超过80%,而只需要21M参数和3.6G mac。相比之下,ViT Baseline DeiT-S的准确率略差为79.8%,但需要增加28%的mac(4.6G)。为了获得类似的精度,MLP-Like模型ResMLP-S24需要增加43%的参数(30M)和67%的计算量(6.0G),而仅获得79.4%的精度。
即使与更多改进的ViT和MLP-like变体相比,PoolFormer仍然表现出更好的性能。其中,PVT-Medium在44M参数和6.7GMAC下,精度达到81.2%,而Pool-s36的参数(31M)少30%(31M),MACs(5.2G)减少22%。
此外,与RSB-ResNet相比,ResNet在相同的300个Epoch中使用改进的训练程序进行训练,PoolFormer训练者仍然是不败的。使用∼22M parameters/3.7GMACs,RSB-ResNet-34可以获得75.5%的精度,而PoolFormer-s24可以获得80.3%的精度。
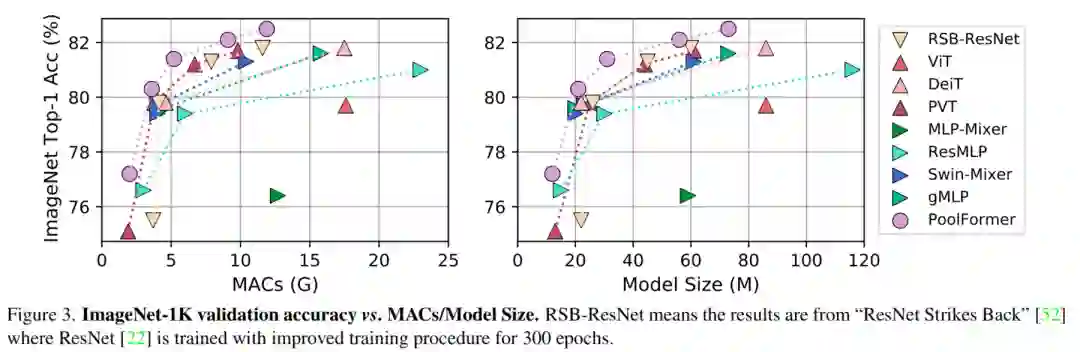
使用池化操作符,每个token平均聚合其附近token的特征。因此,它是最基本的token mixer操作。然而,实验结果表明,即使使用这种极其简单的token mixer,它仍然具有很高的竞争性能。图3清楚地显示,PoolFormer优于其他具有较少mac和参数的模型。
5.3 目标检测实验
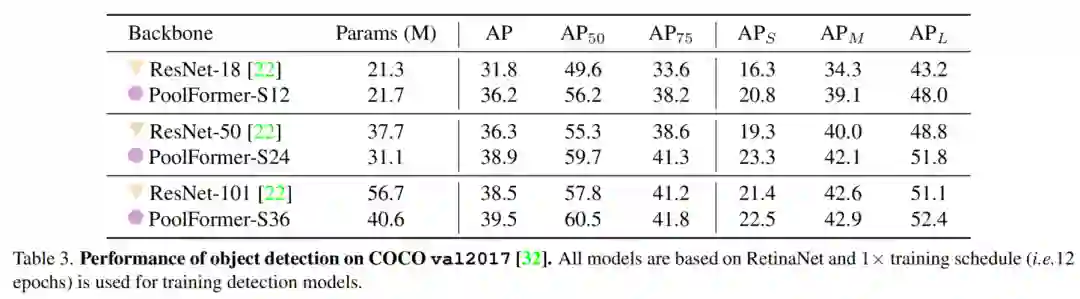
目标检测的架构是RetinaNet,基于PoolFormer模型始终优于其类似的ResNet模型,如表所示。PoolFrorer-S12达到36.2AP,大大超过ResNet-18(31.8AP)。

基于MaskR-CNN的模型在目标检测和实例分割方面也得到了类似的结果。例如,PoolFore-S12大大超过ResNet-18(AP37.3 vs 34.0,maskAP34.6 vs 31.2)。
总的来说,对于COCO目标检测和实例分割,PoolFormer实现了具有竞争力的性能,始终优于ResNet。
5.4 语义分割实验
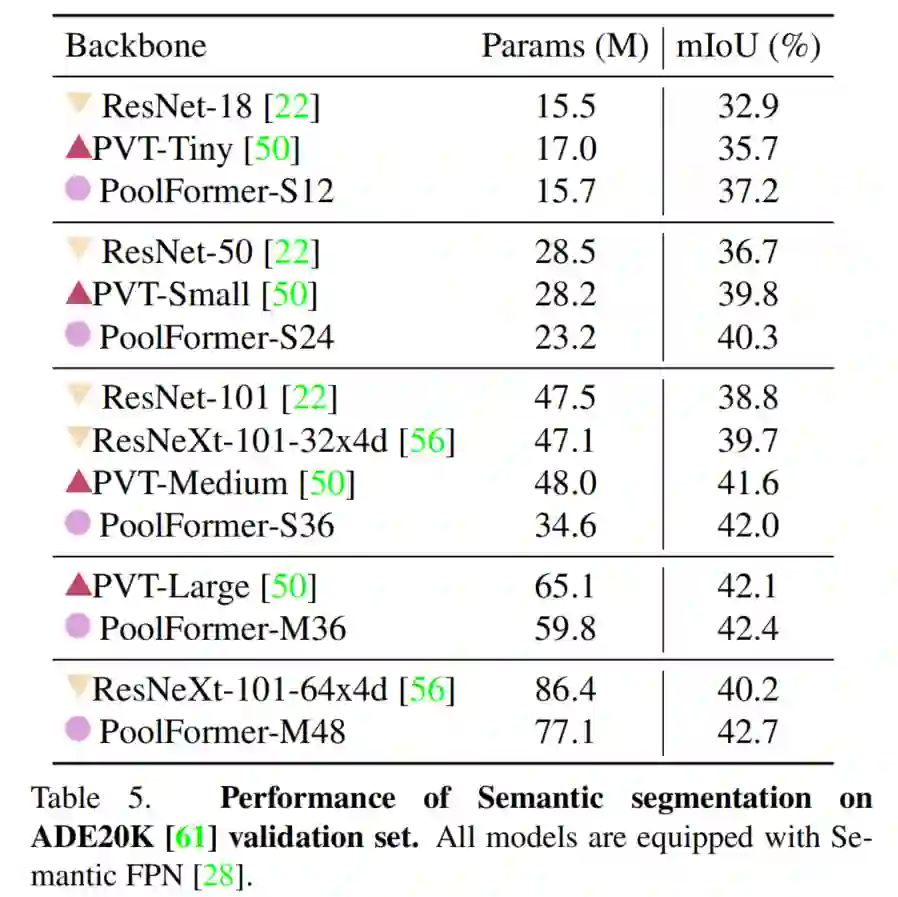
上表显示了使用FPN对不同Backbone的ADE20K语义分割性能。基于PoolFormer的模型始终优于基于CNN的ResNet和ResNeXt以及PVT模型。例如,PoolFormer-S12达到了37.1的mIoU,比PvT和ResNet18都高。
5.5 ResNet与PoolFormer的速度对比
实验参数:2070 Super 显卡, Pytorch fp32 推理,除
PoolFormer-m48以外的模型推理Batch均为10,循环10000次得到的平均结果。

通过上图可以看到,选择PoolFormer-S12或者PoolFormer-S24作为Backbone是比较划算的,速度分别可以达到ResNet34和ResNet50,但是精度却分别达到了77.2%和80.3%。如果算力和显存允许PoolFormer-S36也是不错的选择,速度与ResNet101相当,但是精度却高出3.7%。
上面MetaFormer论文和代码下载
后台回复:MetaFormer,即可下载论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看