CVPR 2022 Oral | 腾讯优图&厦门大学提出无需训练的ViT结构搜索算法
无需训练的 ViT 结构搜索算法是怎么样的?性能又如何呢? 腾讯优图实验室、厦门大学等机构对此进行了深入的探讨与研究。论文被选中为 CVPR 2022 Oral。
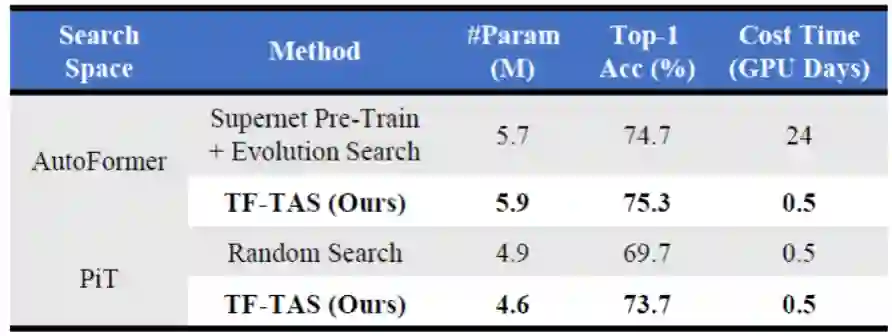
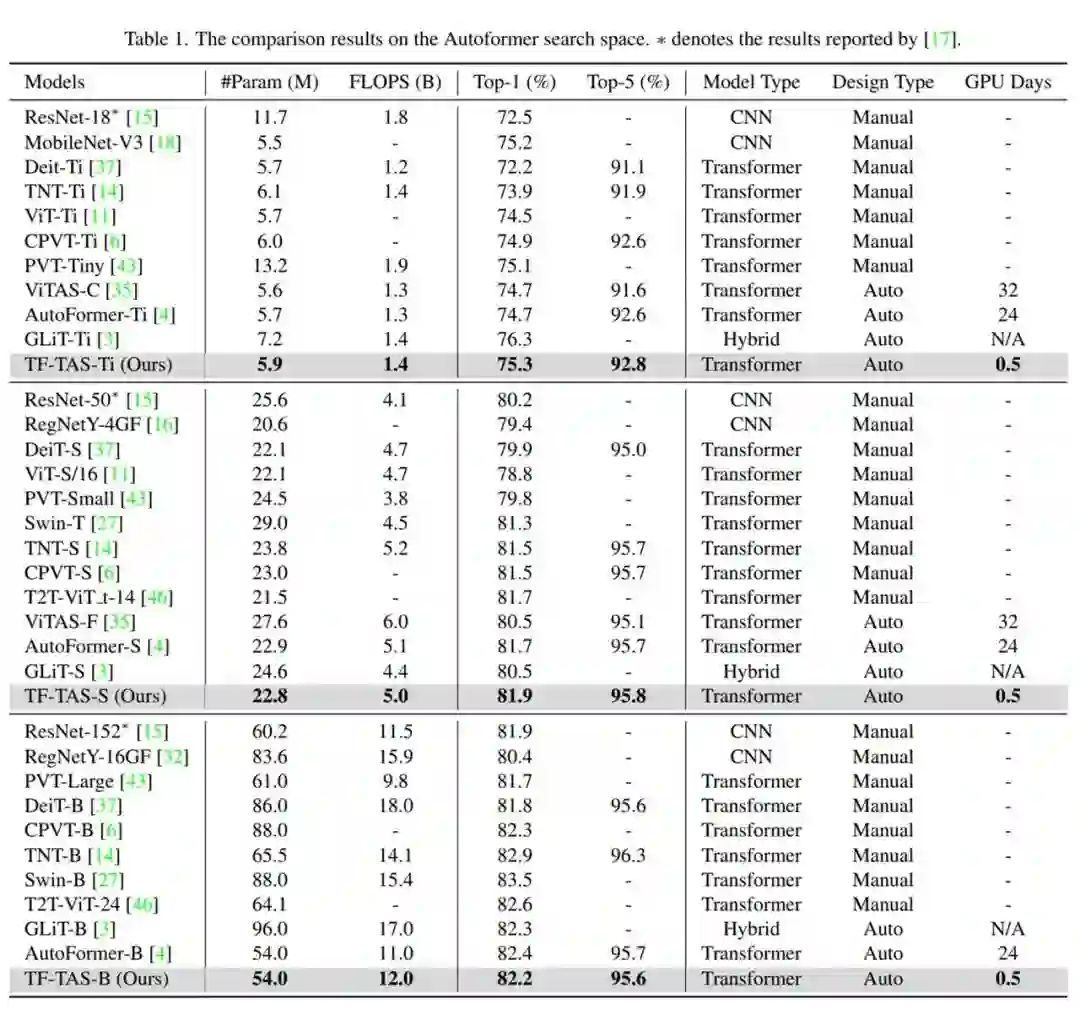
在空间的复杂度上,ViT 搜索空间(如,GLiT 空间的量级约 10^30)在数量上远远超过 CNN 搜索空间(如,DARTS 空间的量级约 10^18);
ViT 模型通常需要更多的训练周期(如300 epochs)才能知道其对应的效果。

论文地址:https://arxiv.org/pdf/2203.12217.pdf
项目地址:https://github.com/decemberzhou/TF_TAS
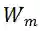 。m 表示 MSA 中第 m 个线性层。因此,
的 F 范数可以定义为:
。m 表示 MSA 中第 m 个线性层。因此,
的 F 范数可以定义为:
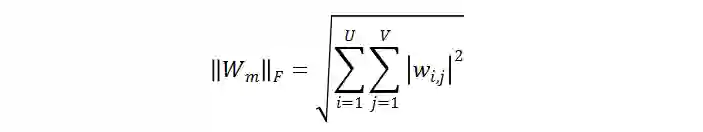
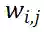 表示
表示
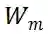 中第 i 行 j 列的元素,根据算术均值和几何均值的不等式,
中第 i 行 j 列的元素,根据算术均值和几何均值的不等式,
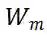 的上界为:
的上界为:
 的上界即为
的上界即为
 的最大线性独立的向量数,即矩阵的秩。随机给定
中的两个向量
的最大线性独立的向量数,即矩阵的秩。随机给定
中的两个向量
 ,
,
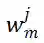 。当
。当
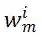 ,
独立时,
,
独立时,
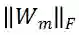 的值相应的会更大。这表明:
的值相应的会更大。这表明:
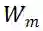 的 F 范数越大,
的秩越接近
的多样性。当
的 F 范数越大,
的秩越接近
的多样性。当
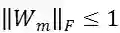 时,
时,
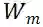 的核范数可以是
秩的近似。形式上,
的核范数可以是
秩的近似。形式上,
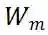 的核范数被定义为:
的核范数被定义为:
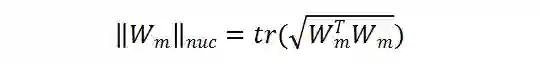
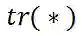 表示相应矩阵的迹,从而容易得到:
表示相应矩阵的迹,从而容易得到:
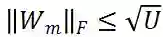 。因此,
。因此,
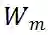 的秩可近似为
的秩可近似为
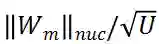 。理论上,
。理论上,
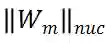 和
和
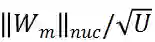 成正比,这也表明利用的核范数可以测度
成正比,这也表明利用的核范数可以测度
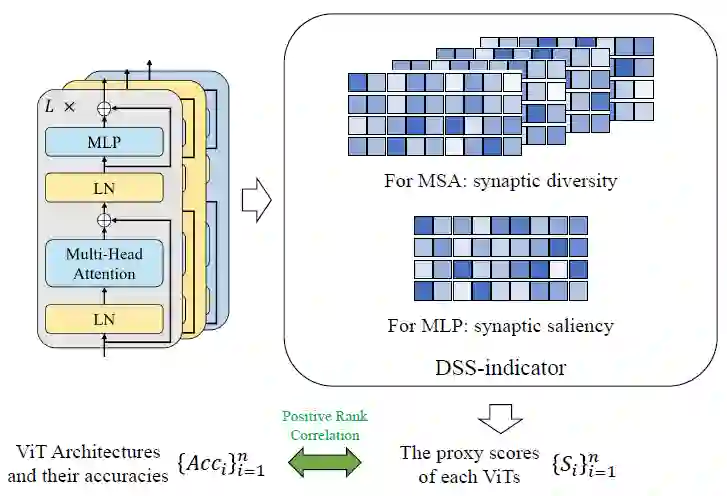
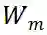 的多样性。为了更好地估计权重随机初始化的 ViT 网络中 MSA 模块的突触多样性,研究者在每个 MSA 模块的梯度矩阵
的多样性。为了更好地估计权重随机初始化的 ViT 网络中 MSA 模块的突触多样性,研究者在每个 MSA 模块的梯度矩阵
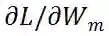 (L 为损失函数) 上进一步考虑上述步骤。
(L 为损失函数) 上进一步考虑上述步骤。
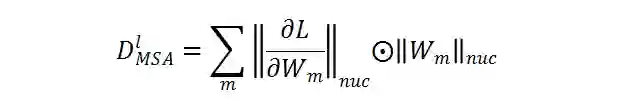
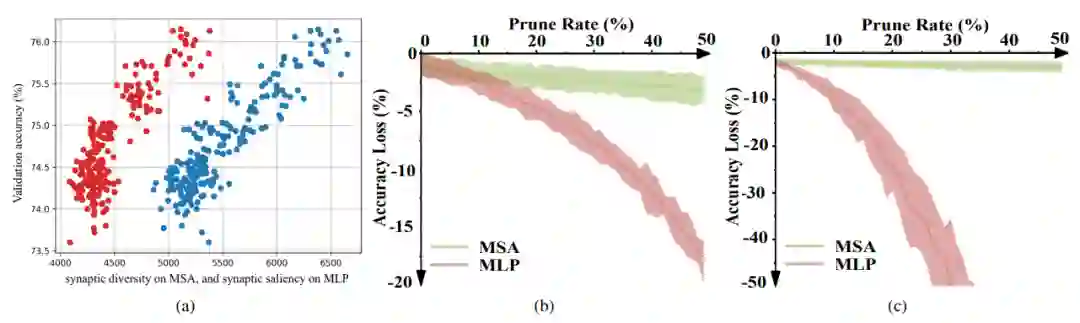
测量在初始化状态下衡量突触的显著性用于 CNN 模型的剪枝;
由于 Transformer 中不同模块在初始化阶段也有不同程度的冗余,因而可以通过对不同大小的 Transformer 进行剪枝。
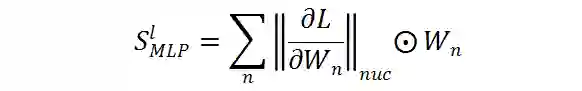
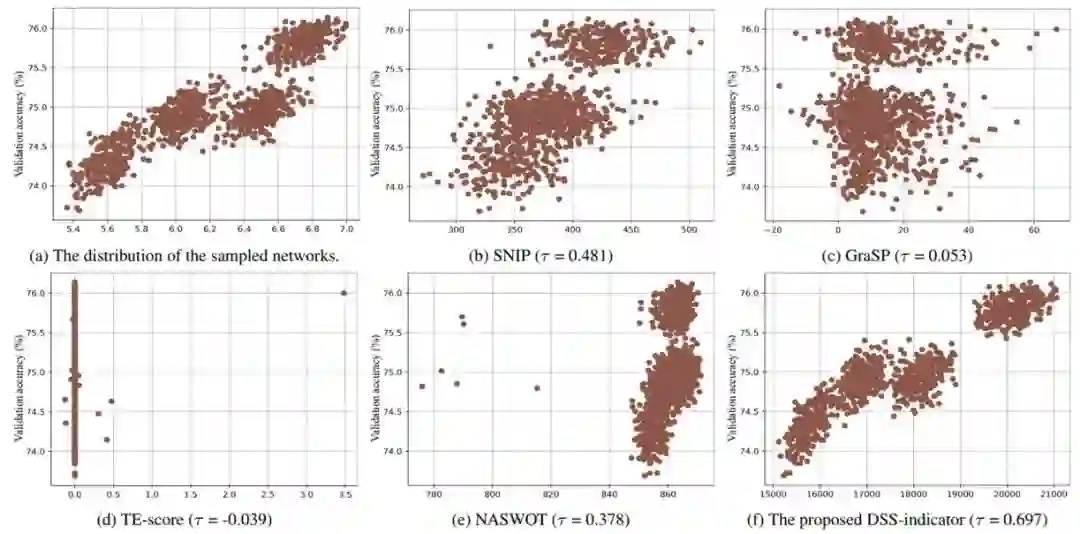
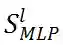 在评估 ViT 架构方面的有效性。
在评估 ViT 架构方面的有效性。
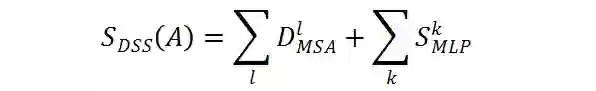
 ,作为相应的 ViT 模型的代理分数。
研究者保持模型的输入数据的每个像素为 1,以消除输入数据对权重计算的影响。
因此,
,作为相应的 ViT 模型的代理分数。
研究者保持模型的输入数据的每个像素为 1,以消除输入数据对权重计算的影响。
因此,
 对随机种子具有不变性,与真实的图片输入数据无关。
对随机种子具有不变性,与真实的图片输入数据无关。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月18日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日