计算成本缩减100倍!港中文提出语义分割新方法:张量低秩重建|ECCV2020
点击蓝字
关注我们


1.引言
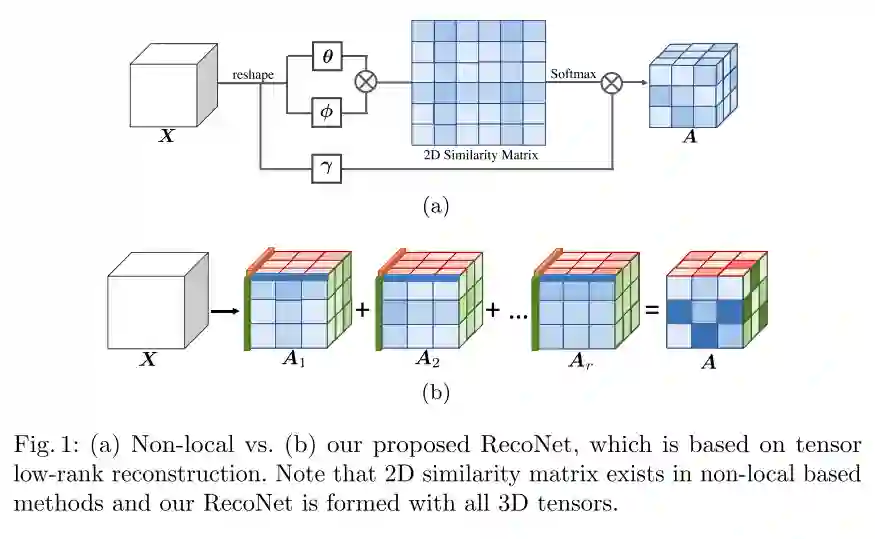 图1
图1
2.方法
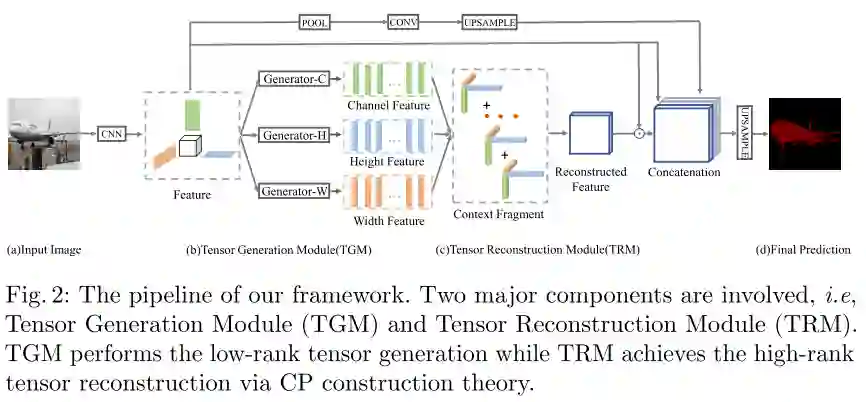 图2
图2
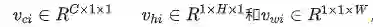
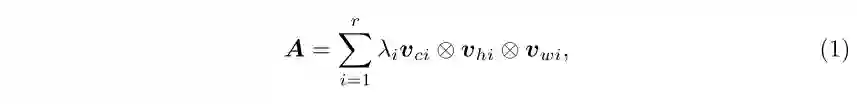
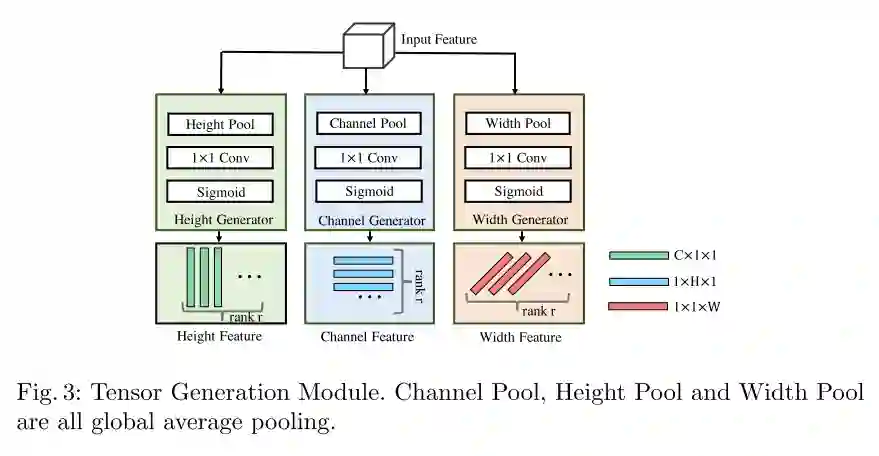 图3
图3
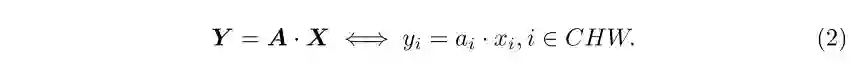
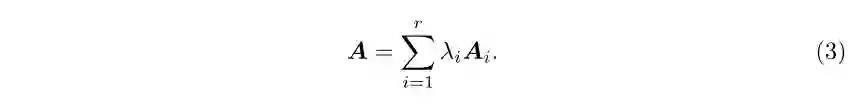
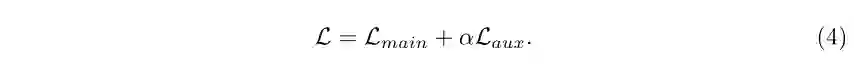
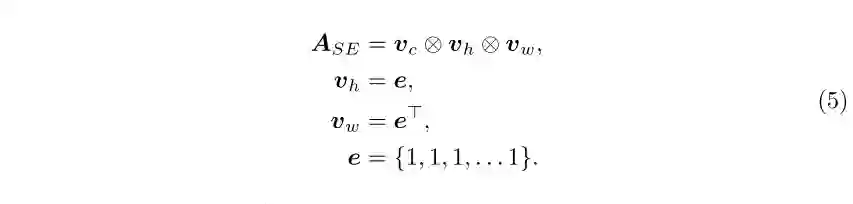
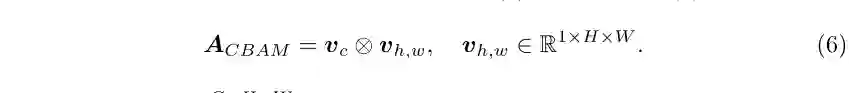
3 实验
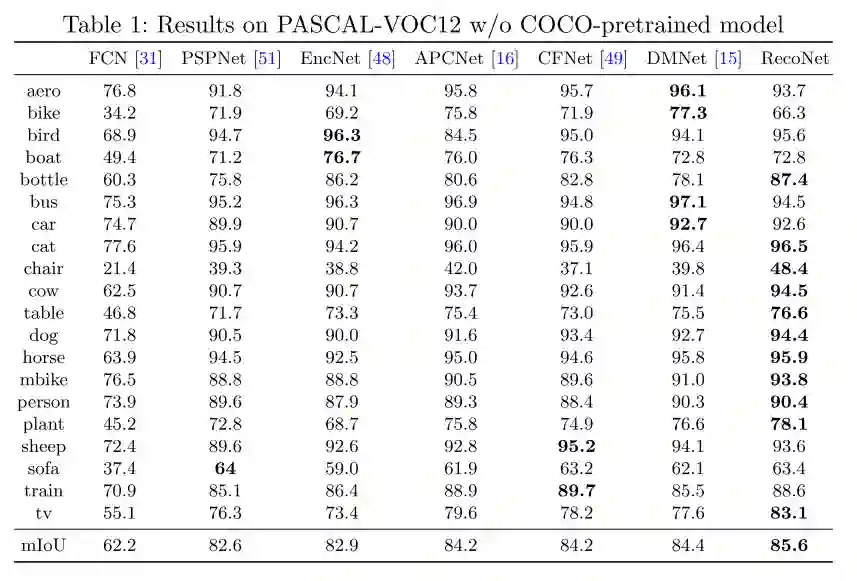
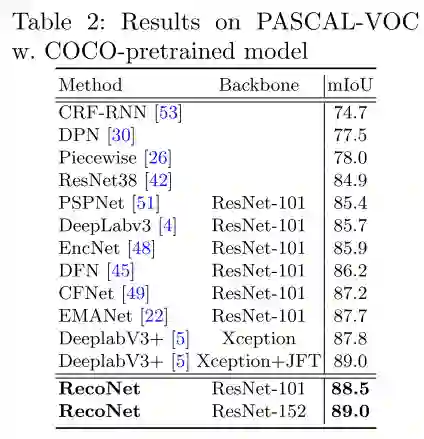
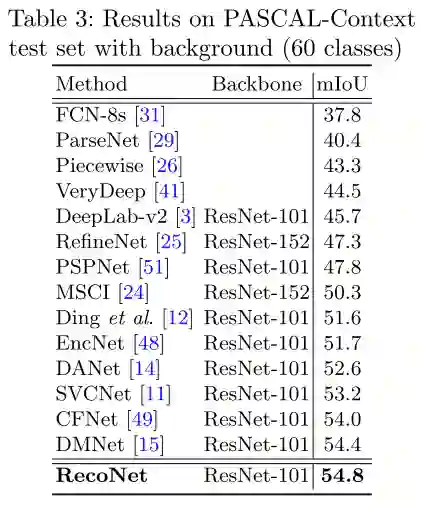
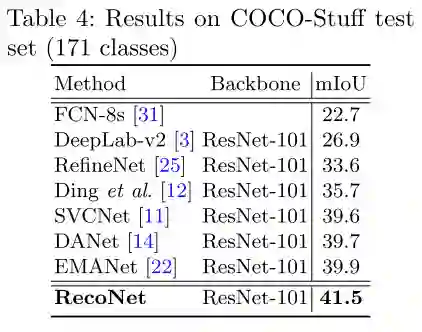
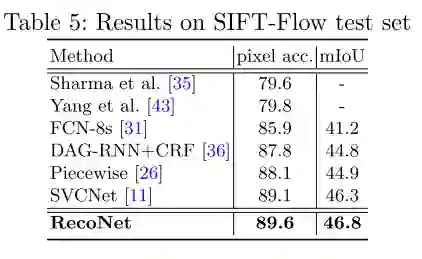
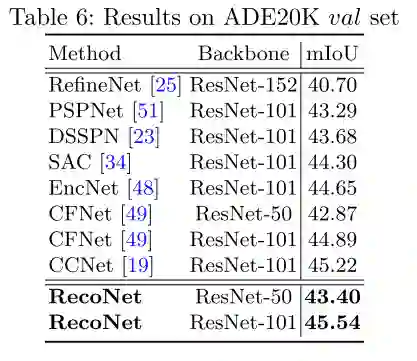

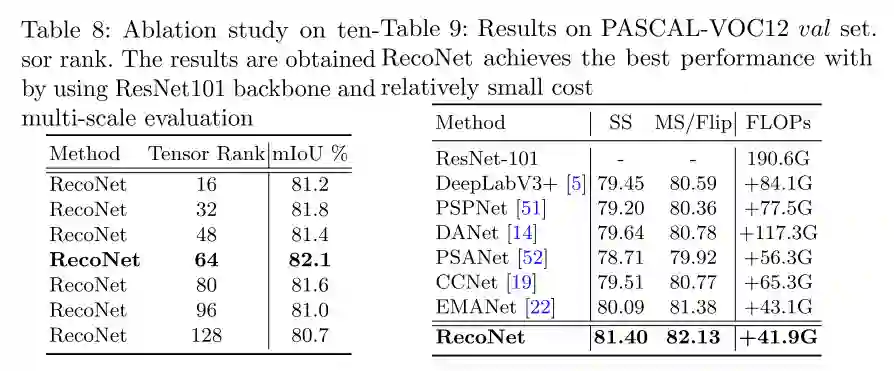
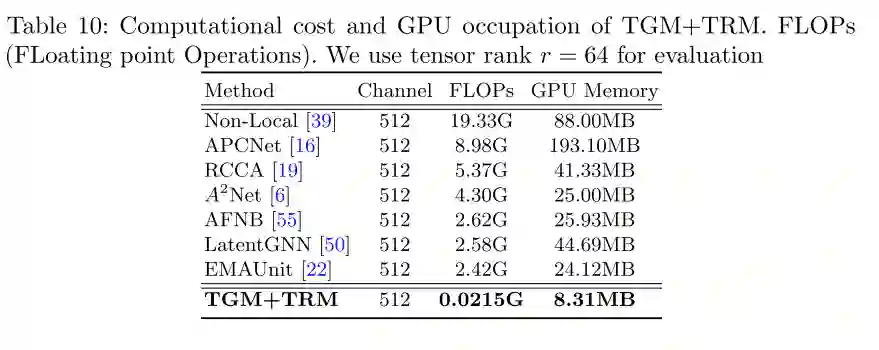

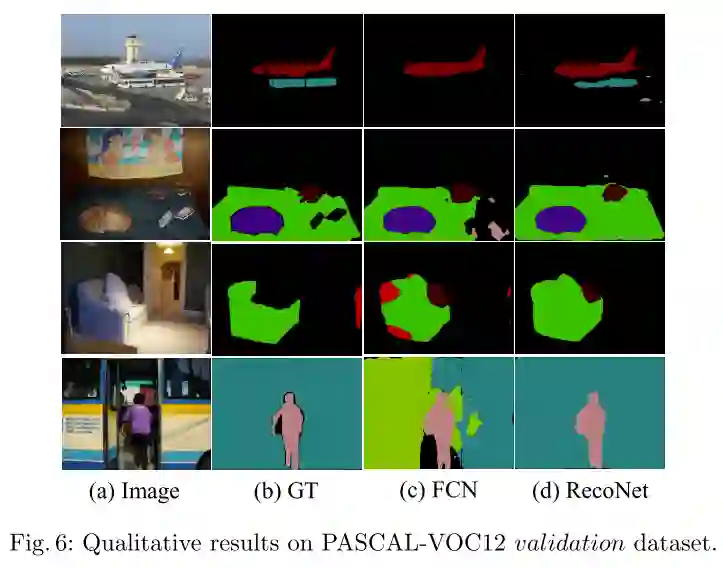 图6 PASCAL-VOC12数据集的量化结果
图6 PASCAL-VOC12数据集的量化结果
4.总结
推荐阅读:




登录查看更多
相关内容
Arxiv
5+阅读 · 2019年5月16日
Arxiv
5+阅读 · 2018年3月13日
Arxiv
8+阅读 · 2018年2月7日


相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年5月16日
Arxiv
5+阅读 · 2018年3月13日
Arxiv
8+阅读 · 2018年2月7日