简明机器学习算法选型指南
作者:Daniil Korbut
编译:weakish
编者按:面对琳琅满目的机器学习算法,你的选择困难症是否发作了?不知道哪类问题最适合手头的问题?Statsbot数据科学家Daniil Korbut最近撰写了一篇简明指南,简要介绍了线性回归、线性分类器、逻辑回归、决策树、K 均值、PCA、神经网络等最常用的机器学习算法,希望能给读者一些在不同任务选择不同算法的直觉。
当我开始进入数据科学领域的时候,我经常遇到一个问题,如何为我手头的特定问题选择最合适的算法。你也许和我有类似的经历,打开一些关于机器学习算法的文章时,会看到许多详细的描述。吊诡的是,这些文章让你的选择更困难了。
在Statsbot上发表的这篇文章中,我将尝试讲解一些基本概念,并给出在不同任务中使用不同种类的机器学习算法的一些直觉。文章末尾会提供一个本文涉及的算法的结构化概述。

首先,你需要区分机器学习任务的4种类型:
监督学习
无监督学习
半监督学习
强化学习
监督学习
监督学习从标注过的训练数据中推断出一个函数。通过拟合标注过的训练集,我们想要找到最优模型参数来预测其他对象(测试集)上的未知标签。 如果标签是一个实数,我们称之为任务回归。如果标签取自有限数量的值,而且这些值是无序的,那么我们称之为分类。
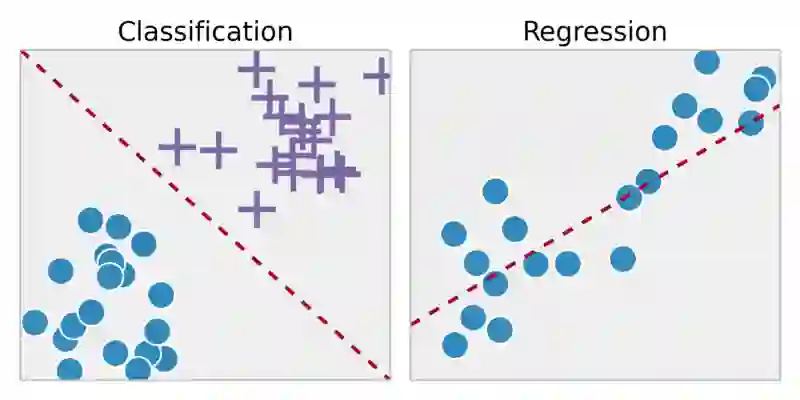
左:分类;右:回归(图片来源:Laura Edell)
无监督学习
在无监督学习中,我们对于对象所知甚少,特别是,训练集没有标签过。那么我们的目标是什么?我们可以观察一组组对象的一些相似性,并将它们纳入适当的聚类之中。有些对象可能与所有聚类大不相同,这样我们就假定这些对象是异常。
图片来源:constonline.com
半监督学习
半监督学习任务包含我们前面提到的两个问题:同时使用标注过和未标注的数据。对于那些无力标注数据的人而言,这是一个巨大的机会。该方法使我们显著地提高准确性,因为我们可以使用未标注的训练集,其中有一小部分标注过的数据。
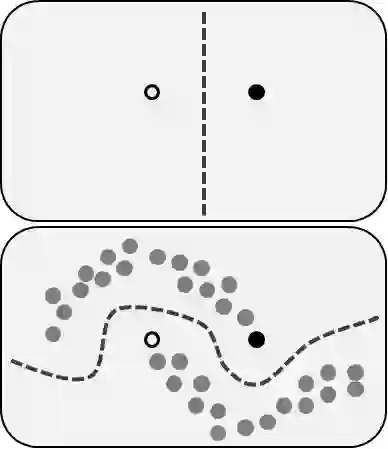
图片来源:维基百科
强化学习
强化学习和我们之前提到的任务都不一样,这里没有标注过或未标注的数据集。RL是一种机器学习方法,涉及软件代理应该如何在某些环境中采取行动,以最大化某种概念上的累积奖励。
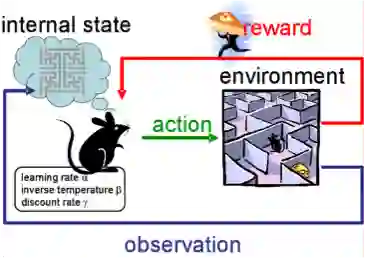
想象一下,你是一个身处陌生环境的机器人,你可以执行某些行动,并从环境中获得奖励。在每一个行动之后,你的行为变得越来越复杂和聪明,所以你正训练自己在每一步采取最有效的行动。在生物学上,这被称为适应自然环境。
常用机器学习算法
我们对机器学习任务的类型已经有了一些直觉,现在来探索一下最流行的算法及其在现实生活中的应用。
线性回归和线性分类器
这些可能是机器学习中最简单的算法。你有对象(矩阵A)的特征x1,… xn,以及相应的标签(向量B)。你的目标是根据某些损失函数(例如,用于回归问题的MSE或MAE)找到这些特征的最优权重w1,… wn和偏置值。在MSE的情况下,有一个来自最小二乘法的数学公式:
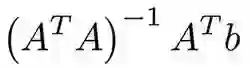
在实践中,使用梯度下降来优化更容易,在算力上也更高效。尽管这个算法很简单,但是当你有数以千计的特征时(例如文本分析中的词袋或者n元语法),它的效果相当不错。更复杂的算法面临过拟合众多特征和数据集大小受限的问题,而线性回归在这方面表现不错。

图片来源:newsdog.today
为了防止过拟合,我们经常使用lasso和ridge之类的规整化技术。这个想法是,将权重模总和与权重平方总和分别与我们的损失函数相加。你可以阅读一下文章结尾推荐的关于这两个算法的精彩教程。
逻辑回归
别因为逻辑回归的名称中带有“回归”一词而将它与回归方法相混淆了,逻辑回归实际上是分类算法。逻辑回归进行二元分类,所以标签输出是二进制的。给定输入特征向量x,定义P(y=1|x)为输出y为1的条件概率。系数w是模型想要学习的权重。
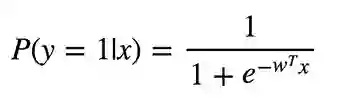
由于该算法计算归属每个类别的概率,因此应该考虑概率与0或1的偏离程度,并像在线性回归中一样对所有对象进行平均。这样,损失函数是交叉熵的平均值:

不要恐慌,我来让上面的公式容易理解一点。y表示正确答案(0或1),y_pred表示预测答案。如果y等于0,总和内的第一个加数等于0,根据对数的性质,我们预测的y_pred越接近0,第二个加数就越小。y等于1的情况同理。
逻辑回归哪里强?它接受线性组合的特征,并对其应用非线性函数(sigmoid),所以它是一个非常非常小的神经网络实例!
决策树
另一个流行和易于理解的算法是决策树。决策树的图形帮助你看到你在思考什么,决策树的引擎要求一个系统的、记录在案的思考过程。
这个算法的想法很简单。在每个节点上,我们选择所有特征和所有可能的分割点之中的最佳分割。每个分割都基于极大化某个泛函进行选择。在分类树中我们使用交叉熵和基尼指数。在回归树中,我们最小化该区域中的点的目标值的预测变量与给定赋值的平方误差的总和。
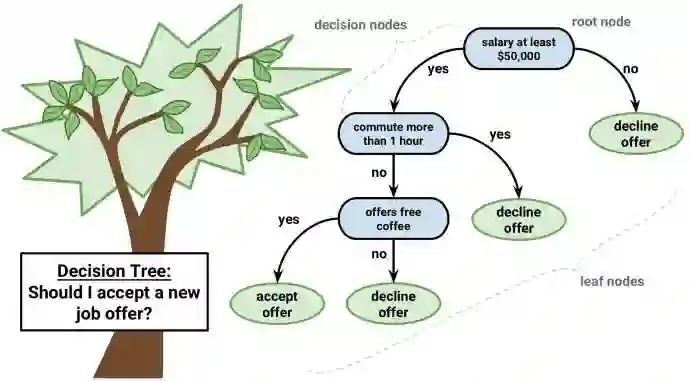
是否接受新工作的决策树(来源:cway-quantlab)
我们在每个节点上递归地进行这一流程,直到满足停止条件时结束。停止条件可以是叶节点的最小数量,也可以是树高。 单独的决策树极少使用,但是与其他算法一起,可以构成非常高效的算法,例如随机森林或梯度树提升(Gradient Tree Boosting)。
K 均值
有时你对标签一无所知,你的目标是根据对象的特征来分配标签。这被称为聚类任务。
假设你想把所有的数据对象分成k个聚类。你需要从数据中选择随机的k个点,并将它们命名为聚类的中心。其他对象的聚类由最近的聚类中心确定。然后,重复转变聚类中心直到收敛。

这是最明晰的聚类技术,但它仍有一些缺点。首先,你应该知道我们尚不知道的聚类的数量。其次,结果取决于在开始时随机选择的点,算法不保证我们达到泛函的全局最小值。
推荐阅读中包括了一系列各有优劣的聚类方法。
主成分分析(PCA)
你是否曾在最后一晚或者最后几个小时准备艰难的考试? 你没有机会记住所有的信息,但是你想要在可用的时间内最大限度地记住信息,例如,首先学习多场考试中都会用到的定理,等等。
主成分分析基于同样的想法。该算法提供了降维。有时你有范围很广的特征,而且很可能彼此高度相关,并且模型很容易会过拟合大量的数据。那么,你可以应用PCA。
你应该计算某些向量的投影,以最大化数据的方差,并尽可能少地损失信息。令人惊讶的是,这些向量正是数据集特征的相关矩阵的特征向量。
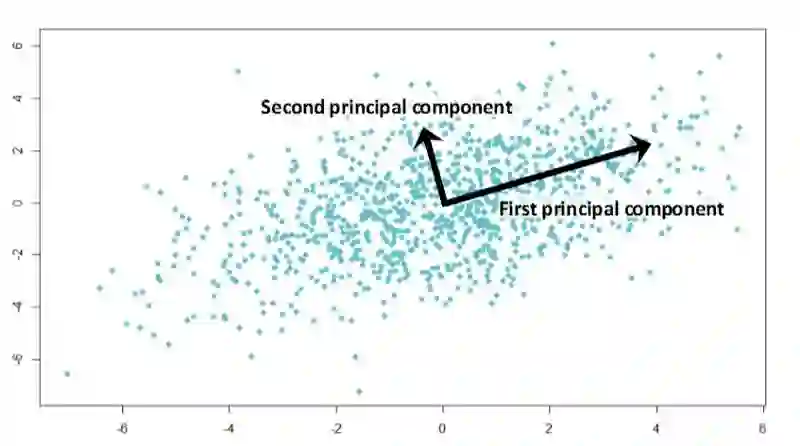
图片来源:Analytics Vidhya
现在,算法的思路已经很清楚了:
计算特征列的相关矩阵,找出该矩阵的特征向量。
接受这些多维向量,并计算它们上的所有特征的投影。
新特征是投影的坐标,其数量取决于计算投影的特征向量的计数。
神经网络
讨论逻辑回归时,我已经提到了神经网络。有很多不同架构的神经网络,它们在特定的任务中价值很高。更常见的情况,神经网络是一系列的层和组件,其间是线性连接,接着会用到非线性。
卷积深度神经网络在处理图像方面展现出很好的效果。非线性表现为卷积层和池化层,能够捕捉图像的特征。

图片来源:smash
处理文本和序列,较好的选择是循环神经网络。 RNN包含LSTM或GRU模块,并且可以使用我们预先知道维度的数据。也许,RNN最著名的应用之一就是机器翻译。
总结
希望我能向你解释最常用的机器学习算法的通常看法,并给你一些针对特定问题选择一种机器学习算法的直觉。为了方便你的选择,我准备了这些算法主要特性的结构化概述。
线性回归和线性分类器。 尽管看起来简单,但是它们很善于处理大量特征(更高级的算法在这种情况下面临过拟合问题)。
逻辑回归是最简单的非线性分类器。它基于参数的线性组合和非线性函数(sigmoid),并适用于二元分类。
决策树经常与人们的决策过程类似,因此易于解释。但它们通常用于诸如随机森林或梯度提升之类的组合中。
K 均值是一个更原始,但非常容易理解的算法,可以完美地成为许多问题的基准。
PCA是一个优秀的选择,在最小化信息损失的前提下,降低特征空间的维度。
神经网络是机器学习算法的一个新时代,可以应用于许多任务,但是神经网络的训练需要巨大的计算复杂度。
推荐阅读
http://scikit-learn.org/stable/modules/clustering.html#overview-of-clustering-methods
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
https://www.youtube.com/channel/UCWN3xxRkmTPmbKwht9FuE5A
原文地址:https://blog.statsbot.co/machine-learning-algorithms-183cc73197c