
随着基于机器学习(ML)系统在医学、军事、汽车、基因组以及多媒体和社交网络等多种应用中的广泛应用,对抗式学习(AL)攻击(adversarial learning attacks)有很大的潜在危害。此篇AL的综述,针对统计分类器的攻击的防御。在介绍了相关术语以及攻击者和维护者的目标和可能的知识范围后,我们回顾了最近在test-time evasion (TTE)、数据中毒(DP)和反向工程(RE)攻击方面的工作,特别是针对这些攻击的防御。在此过程中,我们将鲁棒分类与异常检测(AD)、无监督和基于统计假设的防御和无攻击(no attack)假设的防御区分开来;我们识别了特定方法所需的超参数、其计算复杂性以及评估其性能的指标和质量。然后,我们深入挖掘,提供新的见解,挑战传统智慧,并针对尚未解决的问题,包括:1)稳健的分类与AD作为防御策略;2)认为攻击的成功程度随攻击强度的增加而增加,这忽略了对AD的敏感性;3)test-time evasion (TTE)攻击的小扰动:谬误或需求?4)一般假设的有效性,即攻击者知道要攻击的示例的真实程度;5)黑、灰或白盒攻击作为防御评估标准;6)基于查询的RE对广告防御的敏感性。 然后,我们给出了几种针对TTE、RE和DP攻击图像的防御的基准比较。论文最后讨论了持续的研究方向,包括检测攻击的最大挑战,其目的不是改变分类决策,而是简单地嵌入“假新闻”或其他虚假内容,而不被发现。
成为VIP会员查看完整内容
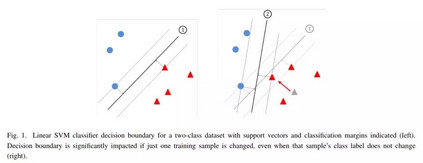
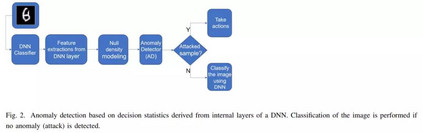

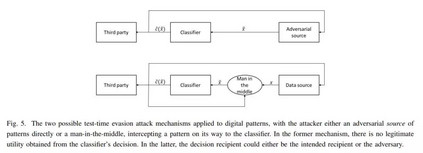
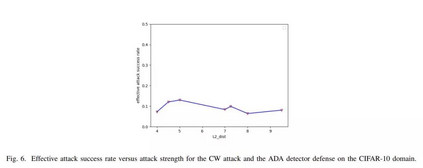

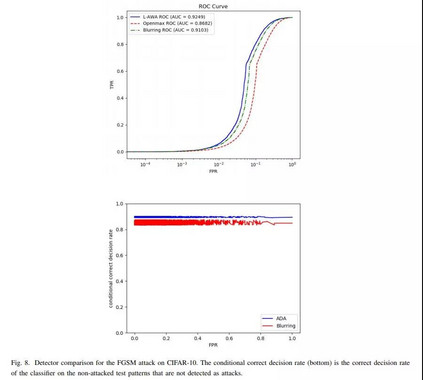
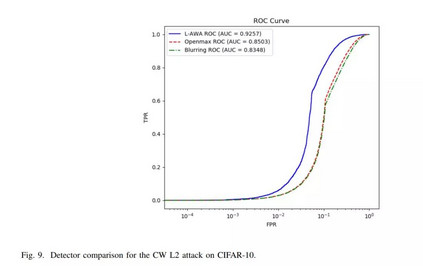
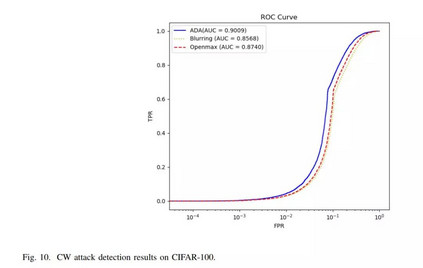

相关内容

Arxiv
21+阅读 · 2018年12月25日
Arxiv
4+阅读 · 2018年9月23日

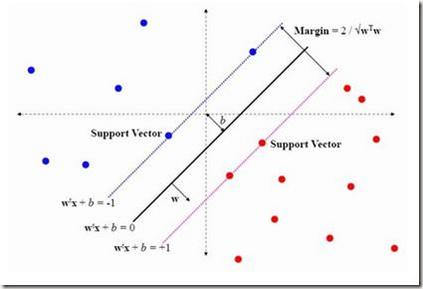

相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2018年12月25日
Arxiv
4+阅读 · 2018年9月23日