【干货】数据科学与机器学习面试指南
【导读】当前人工智能火热,许多人找工作都需要面对面试官各种刁钻的问题,机器学习爱好者 George Seif 最近分享了他在找工作时遇到的常见的面试问题,并与大家分享如何处理这些问题,23道面试题让你熟悉机器学习、数据科学常见知识点,建议大家学习和收藏。
作者 | George Seif
编译 | 专知
参与 | Sanglei, Shengsheng

Data Science and Machine Learning Interview Questions
数据科学与机器学习面试指南
啊!可怕的机器学习面试。面试前你可能觉得你自己什么都知道,直到你被测试的时候才发现情况并没有你想象的那么简单!但是你大可不必担心!
在过去的几个月里,我也面试了许多涉及数据科学和机器学习初级职位的公司。先透露一点我的学习背景,在一年前,我刚攻读完机器学习和计算机视觉的硕士学位,这些学习经历主要还是偏向研究/学术方面的。但是在最近的8个月我在一家创业公司工作。我主要的学习和工作包括数据科学、机器学习和自然语言处理或计算机视觉专业。我面试了亚马逊( Amazon )、特斯拉( Tesla )、三星( Samsung )、优步( Uber )、华为( Huawei )等大公司,也面了大大小小的许多初创企业。
今天我将与大家分享我被问到的所有面试问题以及如何处理这些问题。许多问题都是很常见的和有成熟的理论支撑,但也有许多问题都很有挑战性。我将简单地列出一些最常见的问题,这些问题的答案很容易找到相关的解答资源,除此之外我还将更深入地讨论一些不那么常见和棘手的问题。我希望在阅读这篇文章后,你能在机器学习面试中取得优异成绩,并找到你梦想中的工作!
我们接着将深入探讨:
偏插(Bias)和方差(Variance)之间的权衡是什么?
什么是梯度下降(gradientdescent)?
解释什么是过拟合(over-fitting)和欠拟合(under-fitting)以及如何控制它们?
你如何对抗维度的灾难?
什么是正则化(regularization),我们为什么使用它,并给出一些常见方法的例子?
解释主成分分析( PCA )?
为什么ReLU在神经网络中比Sigmoid更好、更常用?
什么是数据正则化/归一化(normalization)?为什么我们需要它?
我觉得这一点很重要。数据归一化是非常重要的预处理步骤,用于重新缩放输入的数值以适应特定的范围,从而确保在反向传播期间更好地收敛。一般来说采取的方法都是减去每个数据点的平均值并除以其标准偏差。如果我们不这样做,那么一些特征(那些具有高幅值的特征)将在cost函数中得到更大的加权(如果较高幅值的特征改变1 %,则该改变相当大,但是对于较小的特征,该改变相当小)。数据归一化使所有特征的权重相等。
解释降维(dimensionality reduction),降维在哪里使用,降维的好处是什么?
降维是通过获得一组基本上是重要特征的主变量来减少所考虑的特征变量的过程。特征的重要性取决于特征变量对数据信息表示的贡献程度,以及决定使用哪种技术。决定使用哪种技术取决于试错和偏好。通常从线性技术开始,当结果表明拟合不足时,就转向非线性技术。
数据集降维的好处可以是:
( 1 )减少所需的存储空间。
( 2 )加快计算速度(例如在机器学习算法中),更少的维数意味着更少的计算,并且更少的维数可以允许使用不适合大量维数的算法。
( 3 )去除冗余特征,例如在以平方米和平方英里存储地形尺寸方面没有意义(可能数据收集有缺陷)。
( 4 )将数据的维数降低到2D或3D可以允许我们绘制和可视化它,可能观察模式,给我们提供直观感受。
( 5 )太多的特征或太复杂的模型可以导致过拟合。
如何处理数据集中丢失或损坏的数据(missing or corrupted)?
您可以在数据集中找到丢失/损坏的数据,然后删除这些行或列,或者决定用其他值替换它们。在Pandas中,有两种非常有用的方法: isnull ( )和dropna ( ),它们将帮助您查找丢失或损坏数据的数据列并删除这些值。如果要用占位符值(例如0 )填充无效值,则可以使用fillna ( )方法。
解释这个聚类算法?
我写了一篇关于数据科学家需要了解的5种聚类算法的文章《数据科学家需要知道的五种聚类方法》The5 Clustering Algorithms Data Scientists Need to Know,用了一些很直观的可视化方法详细解释了所有这些算法。
https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68
您将如何进行探索性数据分析(Exploratory Data Analysis, EDA )?
EDA是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们对这些数据中的信息没有足够的经验,不知道该用何种传统统计方法进行分析时,探索性数据分析就会非常有效。
您如何知道应该使用哪种机器学习模型?
虽然我们应该永远记住“没有免费午餐定理”,但有一些一般的指导方针。我在这里写了一篇关于如何选择合适回归模型的文章《Selecting the best Machine Learning algorithm for your regressionproblem》
原文链接:https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef。
专知翻译:【干货】对于回归问题,我们该怎样选择合适的机器学习算法
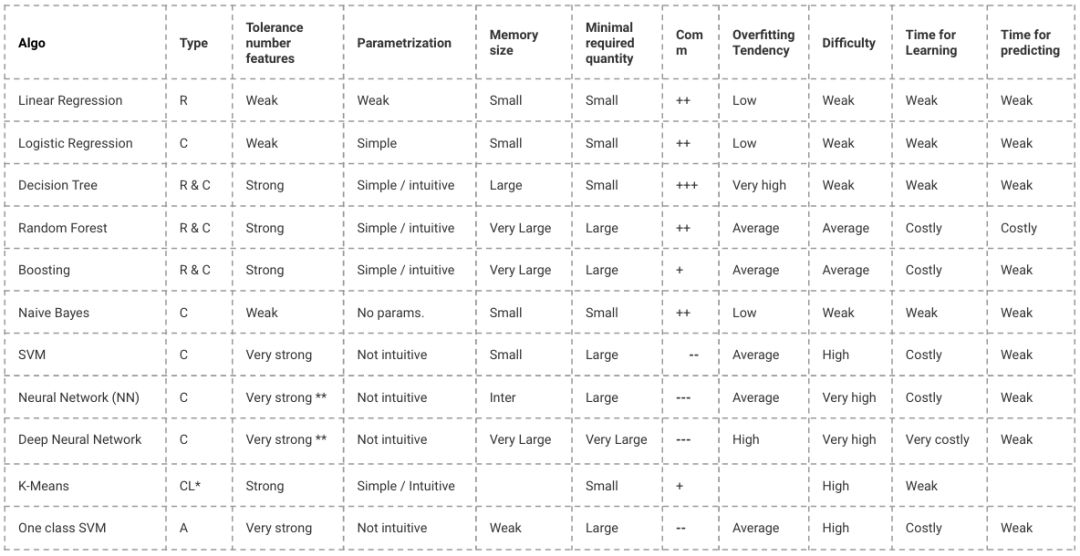
为什么我们对图像使用卷积而不仅仅是FC层?
这个很有趣,因为公司通常不会问这个问题。正如你所料,我是从一家专注于计算机视觉的公司那里得到这个问题的。这个答案有两部分。首先,卷积保存、编码和实际使用来自图像的空间信息。如果我们只使用FC层,我们将没有相对的空间信息。其次,卷积神经网络( CNNs )具有部分内建的平移不变性,因为每个卷积核充当其自身的滤波器/特征检测器。
什么使CNNs具有平移不变性(translation invariant)?
如上所述,每个卷积核充当它自己的滤波器/特征检测器。假设您正在进行目标检测,目标在图像中的位置并不重要,因为无论如何,我们将在整个图像中以滑动窗口的方式应用卷积。
为什么分类CNNs模型中需要max-pooling?
正如你所期望的那样,这是计算机视觉中的一个角色。CNN中的最大池化允许您减少计算量,因为池化后feature maps变小了。您不会丢失太多的语义信息,因为您正在进行最大程度的激活。还有一种理论认为,最大池化对CNNs的平移不变性有一定的贡献。看看吴恩达关于最大池化好处的视频。
https://www.coursera.org/learn/convolutional-neural-networks/lecture/hELHk/pooling-layers
为什么在图像分割中CNNs通常具有编码器-解码器结构?
编码器CNN基本上可以被认为是特征提取网络,而解码器使用该信息通过“解码”特征并放大到原始图像大小来预测图像分割区域。
残差网络(Residual Network)的意义是什么?
残差连接的主要作用是允许当前层的输入特征能够利用来自之前多个层的信息。这使得信息在整个网络中的传播更加容易。关于这一点的一篇非常有趣的论文展示了如何使用local跳跃连接为网络提供一种集成多路径结构,从而为特征提供多条路径以在整个网络中传播。《Residual Networks Behave Like Ensembles of Relatively ShallowNetworks》
https://arxiv.org/abs/1605.06431
什么是批标准化(Batch Normalization)?它为什么起作用?
训练深层神经网络是复杂的,因为每一层的输入分布在训练期间随着前一层的参数改变而改变。然后,其思想是以这样一种方式对每一层的输入进行归一化,即它们具有零的平均输出激活和1的标准偏差。这是针对每一层处的每一个单独的微批次进行的,即,单独计算该微批次的平均值和方差,然后归一化。这类似于网络输入的标准化。这有什么帮助?我们知道,对网络输入进行规范化有助于网络学习。但是网络只是一系列层,其中一层的输出成为下一层的输入。这意味着我们可以把神经网络中的任何层看作是较小的后续网络的第一层。我们把它看作是一系列相互馈入的神经网络,在应用激活函数之前,先对一个层的输出进行归一化,然后再将其馈入下一层(子网络)。
如何处理不平衡的数据集(imbalanced dataset)?
我有一篇关于这个的文章的第三条!《7 Practical Deep Learning Tips》 https://towardsdatascience.com/7-practical-deep-learning-tips-97a9f514100e
专知翻译:你可能不知道的7个深度学习实用技巧
为什么要使用许多小卷积核(如3x 3 )而不是几个大卷积核?
这在VGGNet的原始论文中得到了很好的解释。原因有二:首先,您可以使用几个较小的核而不是几个较大的核来获得相同的感受野并捕获更多的空间上下文,但是使用较小的内核时,您使用的参数和计算量较少。其次,因为使用更小的核,您将使用更多的滤波器,您将能够使用更多的激活函数,从而使您的CNN学习到更具区分性的映射函数。
https://arxiv.org/pdf/1409.1556.pdf
你还做过其他与你申请职位相关的项目吗?
您将真正在您的研究和他们的业务之间建立联系。您所做的任何事情或学到的任何技能是否可能与他们的业务或您申请的角色相关联?它不一定是100 %准确的,只是某种程度上相关,这样你就可以表明你将能够直接增加很多价值。
解释你现在的硕士研究内容?什么有效?什么没有效果?未来方向?
和上一个问题一样!
总结
看吧!这就是我申请数据科学和机器学习岗位时遇到的所有面试问题。希望你能喜欢并有所收获。别忘了点赞。
原文链接:
https://towardsdatascience.com/why-go-large-with-data-for-deep-learning-12eee16f708
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




