【论文推荐】最新7篇变分自编码器(VAE)相关论文—汉语诗歌、生成模型、跨模态、MR图像重建、机器翻译、推断、合成人脸
【导读】专知内容组整理了最近七篇变分自编码器(Variational Autoencoders)相关文章,为大家进行介绍,欢迎查看!
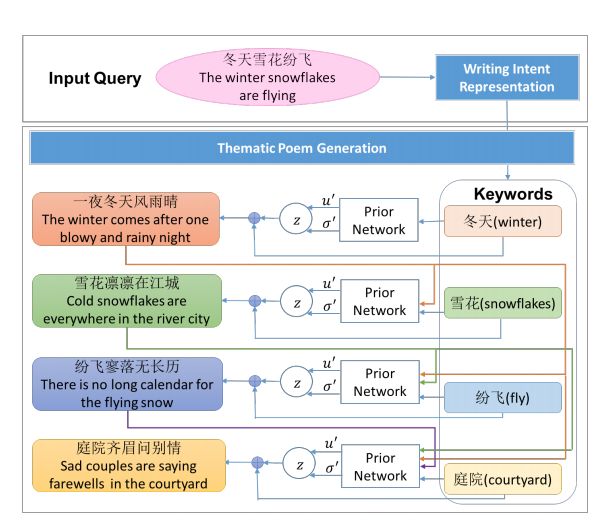
1. Generating Thematic Chinese Poetry using Conditional Variational Autoencoders with Hybrid Decoders(利用带混合解码器的条件变分自编码器生成主题汉语诗歌)
作者:Xiaopeng Yang,Xiaowen Lin,Shunda Suo,Ming Li
摘要:Computer poetry generation is our first step towards computer writing. Writing must have a theme. The current approaches of using sequence-to-sequence models with attention often produce non-thematic poems. We present a novel conditional variational autoencoder with a hybrid decoder adding the deconvolutional neural networks to the general recurrent neural networks to fully learn topic information via latent variables. This approach significantly improves the relevance of the generated poems by representing each line of the poem not only in a context-sensitive manner but also in a holistic way that is highly related to the given keyword and the learned topic. A proposed augmented word2vec model further improves the rhythm and symmetry. Tests show that the generated poems by our approach are mostly satisfying with regulated rules and consistent themes, and 73.42% of them receive an Overall score no less than 3 (the highest score is 5).
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/4f97e2a4680a8cce4ed16ac617a3eefa
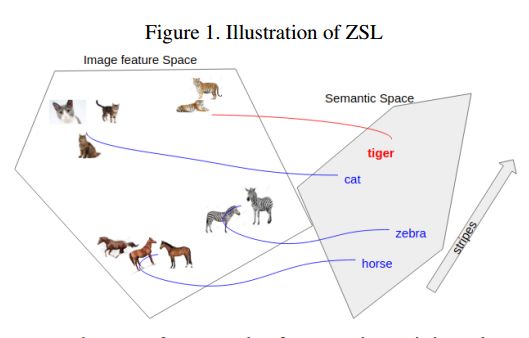
2. A Generative Model For Zero Shot Learning Using Conditional Variational Autoencoders(一种使用条件变分自编码器的Zero Shot Learning的生成模型)
作者:Ashish Mishra,M Shiva Krishna Reddy,Anurag Mittal,Hema A Murthy
摘要:Zero shot learning in Image Classification refers to the setting where images from some novel classes are absent in the training data but other information such as natural language descriptions or attribute vectors of the classes are available. This setting is important in the real world since one may not be able to obtain images of all the possible classes at training. While previous approaches have tried to model the relationship between the class attribute space and the image space via some kind of a transfer function in order to model the image space correspondingly to an unseen class, we take a different approach and try to generate the samples from the given attributes, using a conditional variational autoencoder, and use the generated samples for classification of the unseen classes. By extensive testing on four benchmark datasets, we show that our model outperforms the state of the art, particularly in the more realistic generalized setting, where the training classes can also appear at the test time along with the novel classes.
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/a25c46cfa3472ccf95cd19b16fdbb0a3
3. Improving Bi-directional Generation between Different Modalities with Variational Autoencoders(变分自编码器在不同模态之间的双向生成)
作者:Masahiro Suzuki,Kotaro Nakayama,Yutaka Matsuo
摘要:We investigate deep generative models that can exchange multiple modalities bi-directionally, e.g., generating images from corresponding texts and vice versa. A major approach to achieve this objective is to train a model that integrates all the information of different modalities into a joint representation and then to generate one modality from the corresponding other modality via this joint representation. We simply applied this approach to variational autoencoders (VAEs), which we call a joint multimodal variational autoencoder (JMVAE). However, we found that when this model attempts to generate a large dimensional modality missing at the input, the joint representation collapses and this modality cannot be generated successfully. Furthermore, we confirmed that this difficulty cannot be resolved even using a known solution. Therefore, in this study, we propose two models to prevent this difficulty: JMVAE-kl and JMVAE-h. Results of our experiments demonstrate that these methods can prevent the difficulty above and that they generate modalities bi-directionally with equal or higher likelihood than conventional VAE methods, which generate in only one direction. Moreover, we confirm that these methods can obtain the joint representation appropriately, so that they can generate various variations of modality by moving over the joint representation or changing the value of another modality.

期刊:arXiv, 2018年1月26日
网址:
http://www.zhuanzhi.ai/document/7ee0563dbe428d5eed3c571c5050a45a
4. MR image reconstruction using deep density priors(使用深度密度先验的MR图像重建)
作者:Kerem C. Tezcan,Christian F. Baumgartner,Ender Konukoglu
摘要:Purpose: MR image reconstruction exploits regularization to compensate for missing k-space data. In this work, we propose to learn the probability distribution of MR image patches with neural networks and use this distribution as prior information constraining images during reconstruction, effectively employing it as regularization. Methods: We use variational autoencoders (VAE) to learn the distribution of MR image patches, which models the high-dimensional distribution by a latent parameter model of lower dimensions in a non-linear fashion. The proposed algorithm uses the learned prior in a Maximum-A-Posteriori estimation formulation. We evaluate the proposed reconstruction method with T1 weighted images and also apply our method on images with white matter lesions. Results: Visual evaluation of the samples showed that the VAE algorithm can approximate the distribution of MR patches well. The proposed reconstruction algorithm using the VAE prior produced high quality reconstructions. The algorithm achieved normalized RMSE, CNR and CN values of 2.77\%, 0.43, 0.11; 4.29\%, 0.43, 0.11, 6.36\%, 0.47, 0.11 and 10.00\%, 0.42, 0.10 for undersampling ratios of 2, 3, 4 and 5, respectively, where it outperformed most of the alternative methods. In the experiments on images with white matter lesions, the method faithfully reconstructed the lesions. Conclusion: We introduced a novel method for MR reconstruction, which takes a new perspective on regularization by using priors learned by neural networks. Results suggest the method compares favorably against the other evaluated methods and can reconstruct lesions as well. Keywords: Reconstruction, MRI, prior probability, MAP estimation, machine learning, variational inference, deep learning

期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/f13cbc7729d40c963c78c2d7f69e3f6b
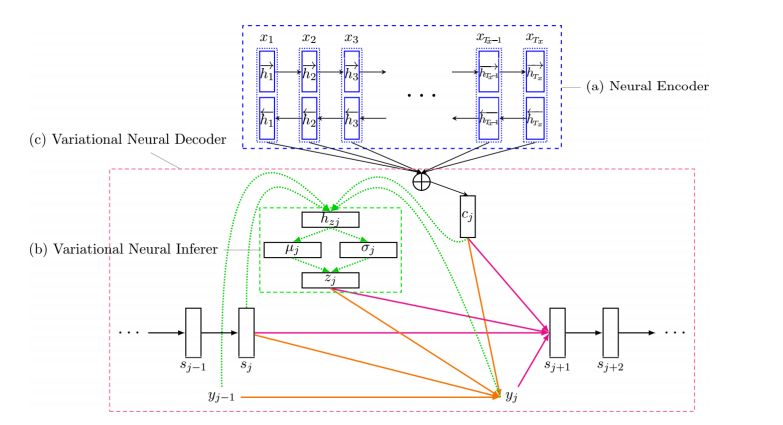
5. Variational Recurrent Neural Machine Translation(变分递归神经机器翻译)
作者:Jinsong Su,Shan Wu,Deyi Xiong,Yaojie Lu,Xianpei Han,Biao Zhang
摘要:Partially inspired by successful applications of variational recurrent neural networks, we propose a novel variational recurrent neural machine translation (VRNMT) model in this paper. Different from the variational NMT, VRNMT introduces a series of latent random variables to model the translation procedure of a sentence in a generative way, instead of a single latent variable. Specifically, the latent random variables are included into the hidden states of the NMT decoder with elements from the variational autoencoder. In this way, these variables are recurrently generated, which enables them to further capture strong and complex dependencies among the output translations at different timesteps. In order to deal with the challenges in performing efficient posterior inference and large-scale training during the incorporation of latent variables, we build a neural posterior approximator, and equip it with a reparameterization technique to estimate the variational lower bound. Experiments on Chinese-English and English-German translation tasks demonstrate that the proposed model achieves significant improvements over both the conventional and variational NMT models.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/134ec3e6bca0ee744054d5a7c3f3b01f
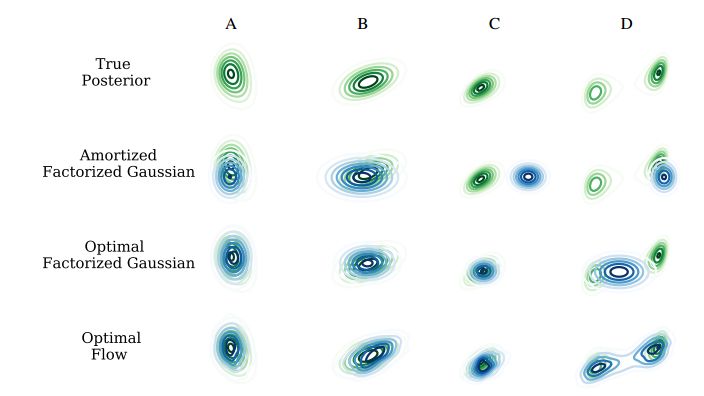
6. Inference Suboptimality in Variational Autoencoders(变分自编码器的推断次优性)
作者:Chris Cremer,Xuechen Li,David Duvenaud
摘要:Amortized inference has led to efficient approximate inference for large datasets. The quality of posterior inference is largely determined by two factors: a) the ability of the variational distribution to model the true posterior and b) the capacity of the recognition network to generalize inference over all datapoints. We analyze approximate inference in variational autoencoders in terms of these factors. We find that suboptimal inference is often due to amortizing inference rather than the limited complexity of the approximating distribution. We show that this is due partly to the generator learning to accommodate the choice of approximation. Furthermore, we show that the parameters used to increase the expressiveness of the approximation play a role in generalizing inference rather than simply improving the complexity of the approximation.
期刊:arXiv, 2018年1月11日
网址:
http://www.zhuanzhi.ai/document/da794e449274c8774ef42d545cf621ef
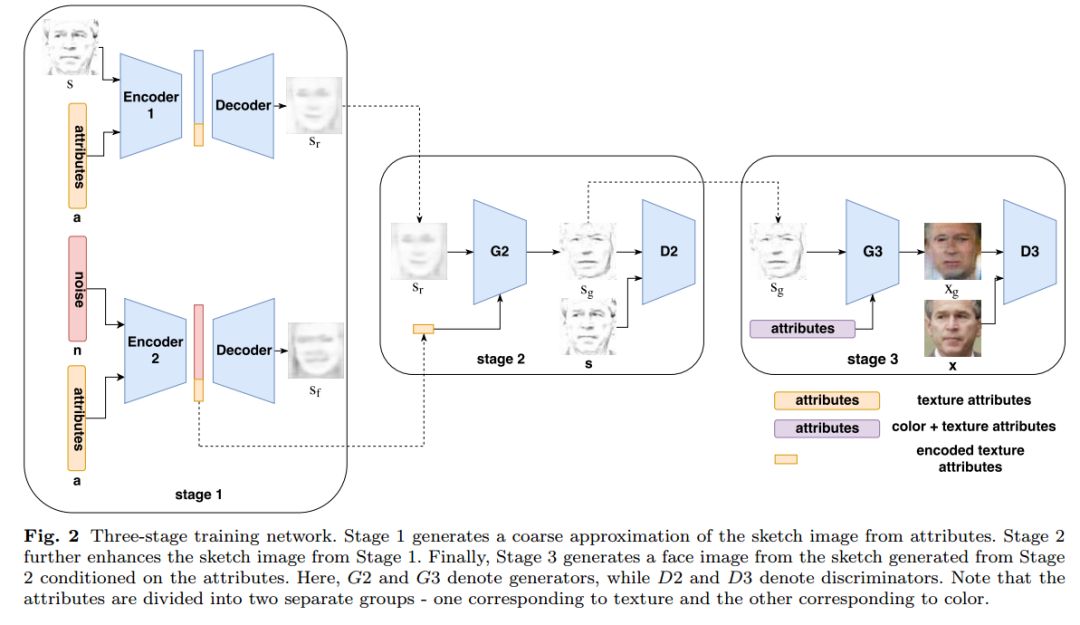
7. Face Synthesis from Visual Attributes via Sketch using Conditional VAEs and GANs(使用条件VAEs和GANs从视觉属性中合成人脸)
作者:Xing Di,Vishal M. Patel
摘要:Automatic synthesis of faces from visual attributes is an important problem in computer vision and has wide applications in law enforcement and entertainment. With the advent of deep generative convolutional neural networks (CNNs), attempts have been made to synthesize face images from attributes and text descriptions. In this paper, we take a different approach, where we formulate the original problem as a stage-wise learning problem. We first synthesize the facial sketch corresponding to the visual attributes and then we reconstruct the face image based on the synthesized sketch. The proposed Attribute2Sketch2Face framework, which is based on a combination of deep Conditional Variational Autoencoder (CVAE) and Generative Adversarial Networks (GANs), consists of three stages: (1) Synthesis of facial sketch from attributes using a CVAE architecture, (2) Enhancement of coarse sketches to produce sharper sketches using a GAN-based framework, and (3) Synthesis of face from sketch using another GAN-based network. Extensive experiments and comparison with recent methods are performed to verify the effectiveness of the proposed attribute-based three stage face synthesis method.
期刊:arXiv, 2017年12月30日
网址:
http://www.zhuanzhi.ai/document/e5a19f16bf52d978e5b62b3cb16aad7b
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



