![]()
作者:Anil Ananthaswamy
编译:梦佳
来源:智源社区
「有一天晚上,我回家吃饭,激动地说『我终于想明白大脑是怎么工作的了!』我15岁的女儿对我说,怎么又来了,老爸。」 —— Geoffery Hinton
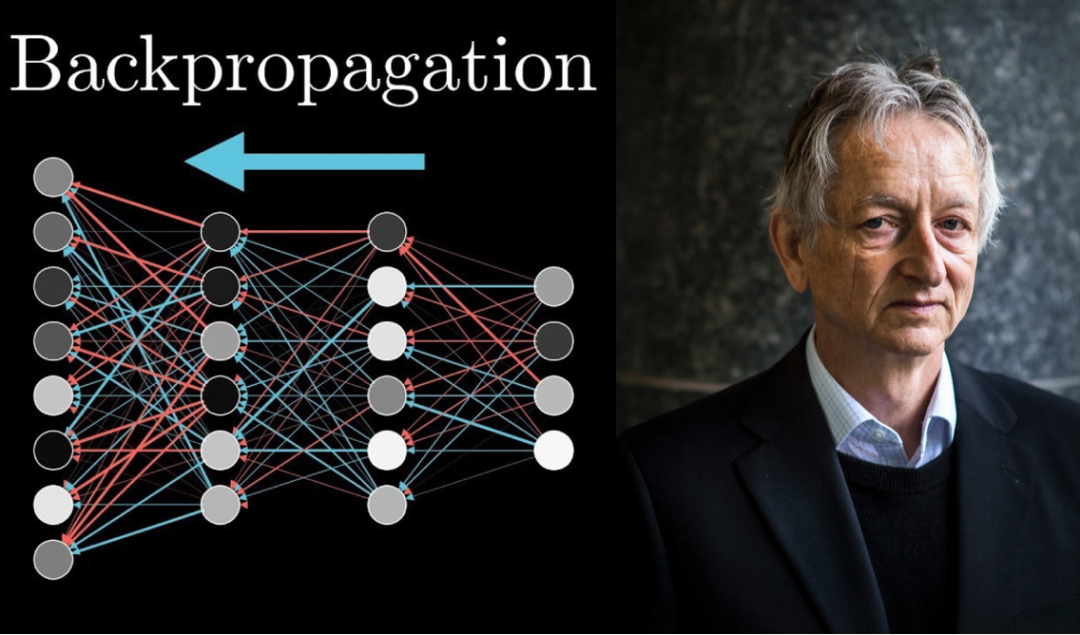
若干年来,大脑的工作原理让AI研究者们前赴后继,而横亘在人工智能网络和大脑工作原理之间的,就是反向传播算法。
Geoffrey Hinton 从年少时起就深深着迷于大脑的奥秘,为了真正理解大脑如何工作,并在大学期间横跨了心理学、化学、物理、生物学和哲学等学科的研究。
在过去的三十多年里,神经科学家Terrence J. Sejnowski 几乎每隔一段时间都会接到 Hinton 的电话,
「我终于知道大脑是如何工作了!」
。
反向传播是深度学习不可或缺的一部分。正是因为反向传播算法,神经网络才能得到复兴并被大量应用。
该算法使深度网络能够从数据中学习,赋予它们分类图像、识别语音、翻译语言、理解无人驾驶路况以及完成大量其他任务的能力。
反向传播算法也遭到了诸多质疑,很多研究者认为真正的大脑不太可能依赖同样的算法。Yoshua Bengio表示,这不仅仅因为「大脑能够比最先进的人工智能系统更好、更快地概括和学习」。
反向传播不符合大脑的解剖学构造和生理学,特别是在大脑皮层当中。
在Hinton的启发下,Bengio 和其他许多学者都一直在思考更具生物学意义的学习机制,希望发现可替代反向传播的机制。
在这些机制当中,反馈对比、平衡传播和预测编码理论具有独特的应用前景。
一些研究人员还将某些类型的皮层神经元和注意力等特性加入到他们的模型中。所有这些努力都使我们距离理解可能在大脑中起作用的算法更进了一步。
大脑是一个巨大的谜团。如果能够揭开它的一些原理,对人工智能有重大的价值。本文对现有的试图解释大脑工作机制的研究进行了梳理。
加拿大心理学家Donald Hebb在1949年曾提出一条指导规则,几十年来,神经科学家关于大脑如何学习的理论主要受到这条规则的影响。这条规则通常被解释为「两个神经元一起放电的时候,他们之间的突触连接会逐步建立或增强。」
(Neurons that fire together,wire together)
也就是说,相邻神经元的活动相连性越强,它们之间的突触联系就越强。这个原则,经过一些修正,成功地解释了某些有限类型的学习和视觉分类任务。
但是,对于需要从误差中学习的大型神经元网络来说,这种方法就没那么奏效了;神经网络深处的神经元并没有直接有针对性的方法来学习已发现的误差,来进行自我更新,以减少误差。
斯坦福大学计算神经学家和计算机科学家 Daniel Yamins说,「赫布规则是一种使用误差信息的非常狭窄、特殊和不敏感的方法。」
尽管如此,这仍然是神经科学家所能利用的最好的学习规则,20世纪50年代后期,这条规则启发了第一个人工神经网络的发展。和生物神经系统相似,这些网络中的每个人工神经元接收多个输入并产生一个输出。神经元将每个输入乘以一个所谓的「突触」权重,然后对加权后的输入进行加总。这个总和就是神经元的输出。
到了20世纪60年代,这些神经元可以被组织成一个有输入层和输出层的网络,人工神经网络可以被训练来解决一系列简单的问题。
在训练过程中,神经网络能够为其神经元确定最佳权重,以消除或减少误差。
然而,即使是在20世纪60年代,研究者们意识到,解决更复杂的问题需要在输入层和输出层之间加上一个或多个神经元的隐藏层。直到1986年,Hinton,已故的 David Rumelhart 和 Ronald Williams (现在在美国东北大学)发表反向传播算法之前,没有人知道如何有效地训练带有隐藏层的人工神经网络。
![]()
该算法分为两个阶段。
在「前向」传播阶段,当给网络一个输入时,它会推断出一个输出,这个输出可能是有误差的。第二个「反向」传播阶段更新突触的权重,使输出与目标值更加一致。
为了方便理解这个过程,可以比作一个「损失函数」,它将推断出的产出和预期的产出之间的差异描述为丘陵和山谷的景观。当一个网络通过一组给定的突触权重进行推断时,它最终会出现在损失区域的某个位置。为了学习,它需要沿着斜坡或梯度方向向下移动,在那里损失会尽可能地减少到最小。反向传播是一种更新突触权重以降低梯度的方法。
本质上,算法的反向阶段通过计算每个神经元的突触权重对错误的贡献程度,然后更新这些权重以提高网络的性能。这种计算顺序是从输出层反向进行到输入层,因此称为反向传播。对于输入和期望的输出反反复复这样操作,最终你会得到一组适合整个神经网络的权重。
反向传播对大脑来说是 mission impossible
反向传播的发布立即引起了一些神经科学家的强烈抗议,他们认为这种方法不可能真正在大脑中起作用。最著名的反对者是诺贝尔奖得主、 DNA 结构的共同发现者神经学家Francis Crick。1989年,Crick写道:
「就学习过程而言,大脑实际上不太可能使用反向传播。」
基于以下几个主要原因,反对者认为,反向传播算法在生物学上是不可信的。
-
首先,虽然计算机可以很容易地实现该算法的两个传播阶段,但是对于生物神经网络来说,这样做难上加难。
-
第二个问题是,计算神经科学家所说的权重传递问题
: backprop 算法复制或传递关于推理所涉及的所有突触权重的信息,并更新这些权重以获得更高的准确性。但是在生物网络中,神经元只能看到其他神经元的输出,而不能看到影响输出的突触权重或内部过程。从神经元的角度来看,「知道自己的突触权重是可以的,」Yamins 说。「你无法知道其他神经元的突触权重。」
Samuel Velasco/Quanta Magazine
任何生物学上可行的学习规则都需要遵守一个限制,即神经元只能从相邻神经元获取信息,而反向传播算法可能需要从更远的神经元处获取信息。因此,「如果你非常严格地来分析反向传播算法的话,大脑是不可能这样计算的,」Bengio 曾表示。
之后,Hinton 和其他一些研究者立即接受了挑战,研究反向传播的生物学上的可信变体。宾夕法尼亚大学计算神经科学家 Konrad Kording 表示: 「第一篇论文认为大脑会做类似反向传播的事情,其历史和反向传播这个概念的诞生一样久远。」
在过去十年左右的时间里,随着人工神经网络的成功,在人工智能研究中开始越来越占据主导地位,研究人员开始更加努力地寻找反向传播在生物系统中存在的证据。
2016年,伦敦谷歌 DeepMind 的 Timothy Lillirap 和他的同事提出了一个解决权重传递问题的方法。他们的算法,并非依赖从前向路径记录的权重矩阵,而是在反向传播过程中随机初始化矩阵。一旦指定权重,这些值永远不会改变,因此不需要为每个反向路径传输权重。
谷歌DeepMind,Timothy Lillicrap
让几乎每个人都感到惊讶的是,这个网络确实能够进行学习。由于用于推理的前向权重随着每次反向路径的更新而更新,因此梯度仍然会沿着不同的路径下降到损失最小的位置。前向的权重慢慢地与随机选择的反向的权重对齐,最终得到正确的答案,给这个算法命名为:
反馈比对
。
「实际上,这并没有你想象的那么糟糕,」Yamins表示,至少对于简单的问题来说是这样。
对于大规模的问题和具有更多隐藏层的更深层次的网络,反馈比对不如反向传播好
: 因为前向权重的更新在每次通过时都不如真正的反向传播信息准确,所以训练网络需要更多的数据。
按照经典的赫布学习法,神经元只对邻近神经元做出反应,研究人员探索了在保持这条经典规则不变的情况下,如何达到反向传播神经元的性能。可以将反向传播看成两组神经元,其中一组神经元进行推理,另一组神经元进行更新突触权重的计算。
Hinton的想法是研究出一种算法,使得其中的每个神经元都可以同时进行两组计算。
「这基本上就是Hinton 在2007年想实现的目标,」Bengio表示。
在 Hinton 研究的基础上,Bengio 团队在2017年提出了一个学习规则,要求神经网络具有循环连接
(也就是说,如果神经元 A 激活神经元 B,那么神经元 B 反过来激活神经元 A)
。如果给这样一个网络一些输入,它设置网络的反馈,如同每个神经元在推拉其邻近的神经元。
最终,神经网络会达到一个状态,在这个状态中神经元与输入和其他神经元之间处于平衡状态,它产生一个输出,这个输出可能是错误的。然后,该算法将输出神经元推向预期结果。这就设置了另一个反向传播的信号通过该网络,引发了类似的动态效应。网络便找到了新的平衡点。
Bengio 说: 「数学的美妙之处在于,如果你比较这两种配置,在推动之前和推动之后,你已经得到了发现梯度所需的所有信息。」。训练网络只需要迭代大量的标记数据,来简单地重复这个「平衡传播」的过程。
传统观点认为,大脑不断地接收新的感知信息,并在越来越复杂的信息中寻找规律,然后构建起大脑对环境的认知,这是一种以「由下对上」的控制为主的感知结构。
而预测编码理论恰恰与此相反,是以「由上对下」的控制为主的:我们的大脑用已有的模型制造出丰富的感官数据,形成一个预测性的内在世界,去匹配即将发生的真实世界。
在大脑感知理论方面,爱丁堡大学博士生Beren Millidge,和他的同事们一直在研究叫做「预测性编码」的大脑感知观点,并和反向传播做对比。「预测性编码,如果以某种方式设置,将给你一个在生物学上合理的学习规则,」Millidge表示。
预测性编码假定大脑不断地对感觉输入的原因进行预测。
这个过程包括神经处理的层次结构。为了产生特定的输出,每一层都必须预测下一层的神经活动。如果最高层期望看到一张脸,它就可以对下面层的活动进行预测,可以证明这种感知。
下一层对再下面的层做出类似的预测,以此类推。最低层能够预测实际的感觉输入,比如说,光子落在视网膜上。通过这种方式,预测从较高的层流向到较低的层。
但问题是,错误可能会发生在层次结构的每个级别: 每一层对它所期望的输入和实际输入的预测之间存在差异。最底层根据接收到的感觉信息调整突触的权重,以最大限度地减少错误。这种调整导致了最新更新的最低层和上面一层之间会产生误差,因此较高层必须重新调整它的突触权重,以尽量减少它的预测错误。这些错误信号向上传递。如此循环往复,直到每一层的预测误差都实现最小化。
Millidge的研究表明,通过适当的设置,预测性编码网络和反向传播相比,可以收敛到几乎相同的学习梯度。「你可以非常非常接近反向传播梯度,」他说。
然而,对于深度神经网络中传统的反向传播算法的每一个反向传播路径,预测性编码网络必须迭代多次。这在生物学上是否合理要取决于这个过程真正的大脑需要多长时间。至关重要的是,网络必须在来自外部世界的输入变化之前达成一个解决方案。
「不能像这样,比如说『有只老虎向我奔来,而我的大脑却需要来回重复传递信号100次才能做出反应,』」Millidge说。他认为,如果可以允许一些不准确出现,预测性编码可以快速得出有用的答案。
一些科学家已经开始着手基于单个神经元的已知特性建立类似反向传播的模型。标准神经元有树突,它们从其他神经元的轴突中收集信息。树突传递信号到神经元的细胞体,在那里信号被整合。这可能会导致神经元放电,从神经元的轴突到突触后神经元的树突上。
但并非所有的神经元都有这种结构。特别是皮层中最丰富的神经元类型——锥体神经元有着明显的不同。锥体神经元具有树状结构,有两套不同的树突。树干向上伸展,分杈形成所谓的顶端树突。根向下延伸,分杈形成基部树突。
Samuel Velasco/Quanta Magazine
2001年由德国神经科学家Kording 独立开发的模型,以及近期由麦吉尔大学和蒙特利尔神经研究所的 Blake Richards 及其同事开发的模型,已经表明,
锥体神经元可以通过同时进行前向和反向计算,而形成深度学习网络的基本单元。
![]()
模型的关键在于分离进入神经元的信号,进行前向推断和反向平滑误差,这些误差可以通过基树突和顶树突分别进行处理。这两种信号都可以在神经元作为输出的放电中进行编码。
Richards 团队的最新研究表明,「我们目前已经达到这样的水平: 通过相当真实的神经元模拟,我们可以训练锥体神经元网络来完成各种任务,」Richards表示。「然后使用这些模型的稍微抽象的版本,我们可以利用锥体神经元网络,来学习人们在机器学习中所做的那种困难的任务。」
对于使用反向传播的深度网络,一个隐含的要求就是要有「老师」的存在: 某种能够计算神经元网络误差的东西。荷兰阿姆斯特丹神经科学研究所(Netherlands Institute for Neuroscience)的Pieter Roelfsema表示,
「但是,大脑中没有一个『老师』会告诉运动皮层的每一个神经元,『你应该被打开,还是应该被关闭。』」
荷兰阿姆斯特丹神经科学研究所Pieter Roelfsema
就此,Roelfsema提出大脑解决问题的方法是通过注意力。
20世纪90年代后期,他和他的同事发现,当猴子盯着一个物体时,在大脑皮层内代表该物体的神经元会变得更加活跃。猴子集中注意力的这一行为会针对相应的神经元产生反馈信号。「这是一个高度选择性的反馈信号,」Roelfsema 表示。「这不是一个误差信号。它只是在告诉所有这些神经元: 你要为(一个行为)负责。」
Roelfsema 的观点是,当这种反馈信号与某些其他神经科学发现所揭示的过程结合起来时,可以实现类似反向传播的学习过程。例如,剑桥大学的 Wolfram Schultz 和其他研究人员已经证明,当动物执行一个行动,产生比预期更好的结果时,大脑的多巴胺系统就会被激活。
「它让整个大脑充满了神经调节器,」Roelfsema 说。多巴胺水平就好比一个全局强化信号。
从理论上讲,注意力反馈信号只能通过更新它们的突触权重,来启动那些负责对全局强化信号做出反应的神经元,Roelfsema 说。他和他的同事利用这个想法构建了一个深层的神经网络,并对其数学特性进行研究。
该团队在去年12月的NIPS 2020 在线会议上展示了这项工作。团队提出的Attention-Gated Brain Propagation (BrainProp) 机制,在数学上等效于误差反向传播,相比于反向传播算法要慢2到3倍。Roelfsema表示,
「它打败了所有其他在生物学上合理的算法。」
尽管如此,仍然无法证明人类大脑真地在使用这些似是而非的机制。斯坦福的
Yamins 和他的同事提出了一些方法,来判断哪些学习规则是正确的。通过分析1,056个实现不同学习模型的人工神经网络,他们发现,通过在一段时间内识别一组神经元的活动,可以鉴别出该神经网络的学习规则类型。这些神经元的活动可以从猴子的大脑记录中得到。
鉴于目前取得的这些进展,计算神经学家们对此十分乐观。「大脑可以通过很多不同的方式进行反向传播,」德国神经科学家Kording 表示。「进化论真的太棒了。反向传播真的有用。我认为,
进化在某种程度上会最终带领我们走上正确的道路。
」
https://www.quantamagazine.org/artificial-neural-nets-finally-yield-clues-to-how-brains-learn-20210218/
喜欢本篇内容,请分享、点赞、在看![]()