Geffory Hinton的“胶囊”里到底装的什么“药”?

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
30 年前的 1986 年,Geffrey Hinton 联合同事 David Rumelhart、Ronald Williams 发表了一篇突破性论文《Learning representations by back-propagating errors》[2], 在论文中首次将反向传播算法( backpropagation,简称 backprop、BP )引入了多层神经网络训练。由此开启了人工智能的新纪元,确立了 Hinton 在 AI 界崇高的地位,被誉为“深度学习之父”。正是这个技术让人工智能发展到今天如此炙手可热的地步。事实上,最近十年人工智能领域的每一个成就,如语音识别、图像识别、博弈等,在某种程度上都可追溯到 Hinton 30 年前所做的工作。
普林斯顿计算心理学家 Jon Cohen 因此将反向传播定义为“所有深度学习技术的基础”。

反向传播(Backpropagation,缩写为 BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值想得到的已知输出,来计算损失函数梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的 Delta 规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
但是就在上个月(AI 前线注:2017 年 10 月), Hinton 却以壮士断腕的气魄,在多伦多举行的 AI 会议 [3] 上,对他亲手建立的反向传播理论,表示“深深的质疑”。在此次会议上,Hinton 引用了 Max Planck 的名言:“科学之道,不破不立。未来取决于对我所说的一切持怀疑态度的那些研究生。”(‘Science progresses one funeral at a time. The future depends on some graduate student who is deeply suspicious of everything I have said.’)他进一步宣扬:要让深度神经网络变得更聪明,就要向无监督学习过渡,反向传播是时候该放弃了!
此言一出,引起了轩然大波,Fei-fei Li、Pedro Domingos、Gary Marcus 等机器学习专家在 Twitter 纷纷转发、表态。
Fei-fei Li,斯坦福大学计算机科学的副教授,ImageNet 创建者。她任职于斯坦福大学人工智能实验室(SAIL)、斯坦福视觉实验室、丰田汽车 - 斯坦福人工智能研究中心负责人。她的专业领域是计算机视觉和认知神经科学。现职为 Google 云端人工智能暨机器学习首席科学家。
Pedro Domingos,华盛顿大学计算机科学的教授,著名的机器学习专家,《终极算法》(Master Algorithm)畅销书作者。在抛弃反向传播上他也提出了自己的方法:离散优化。
反向传播算法在生物学上很难成立,很难相信神经系统能够自动形成与正向传播对应的反向传播结构(这需要精准地求导数,对矩阵转置,利用链式法则,并且解剖学上从来也没有发现这样的系统存在的证据)。反向传播算法更像是仅仅为了训练多层 NN 而发展的算法。其次,反向传播算法需要 SGD 等方式进行优化,这是个高度非凸的问题,其数学性质是堪忧的,而且依赖精细调参。
目前反向传播存在一些问题:计算出来的梯度是否真的是学习的正确方向?从直觉上来看,这是有问题的。人们总能找到某些看上去可行的方向,但这并不总是意味着它最终通向问题的解。所以,忽略梯度或许也可以让我们找到解决方案(当然,我们也不能永远忽略梯度)。适应性方法和优化方法之间存在着很多不同。反向传播是相对于目标函数计算的,没有目标函数就无法进行反向传播。如果你无法评估预测值和标签(实际或训练数据)的 value 值,你就没有目标函数。因此,为了实现“无监督学习”,就需要抛弃计算梯度的能力。
到目前为止,CNN 一直是图像分类最先进的方法。CNN 是通过积累各层的特征集进行工作的。它的工作方式是首先从寻找边缘开始,然后是形状,继而是实际对象。但这种工作方式,把所有这些特征的空间关键信息都丢失了。
卷积神经网路( Convolutional Neural Network,CNN )是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,[4] 对于大型图像处理有出色表现。卷积神经网路由一个或多个卷积层和顶端的全连通层(对应经典的神经网路)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网路能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网路在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网路,卷积神经网路需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
下面是一个简化的例子,可以让你理解 CNN 是如何工作的:

你可能觉得看上去挺有道理的,事实也确实是那么回事儿。但是我们可能会遇到一些问题,比如这张 Kim Kardashian 的照片:

你看,这种照片里,确实有两只眼睛,一个鼻子和一个嘴巴,可是哪里不对劲呢,你有发现么?我们可以很轻易指出这个人的眼睛和鼻子是错的,这不是人类应有的样子。然而,即使训练有素的 CNN 也难以理解这个概念:
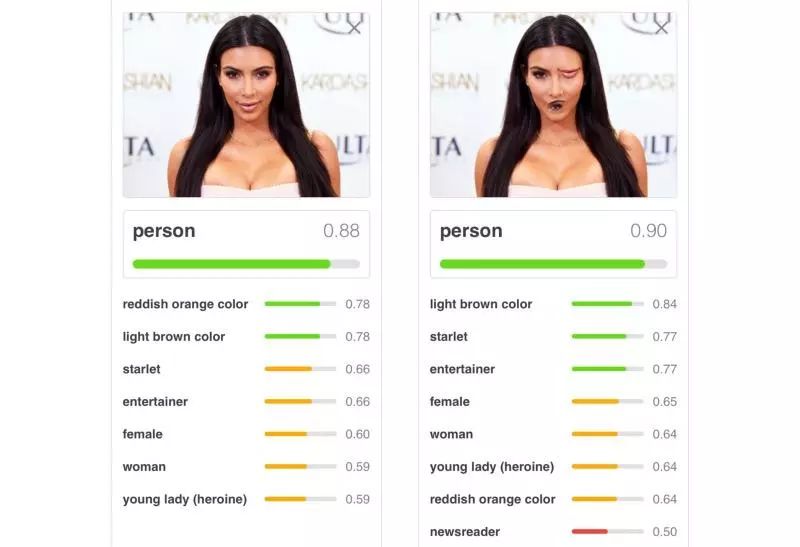
除去容易被错误位置的图像所迷惑外,CNN 在以不同的方向查看图像时,也很容易混淆。要解决这个问题,其中的一个方法就是对所有可能的角度进行过度训练,但这需要耗费大量时间,而且看上去也有悖直觉。
我们倒转这张照片后,可以看到 CNN 的表现就大幅下降了:
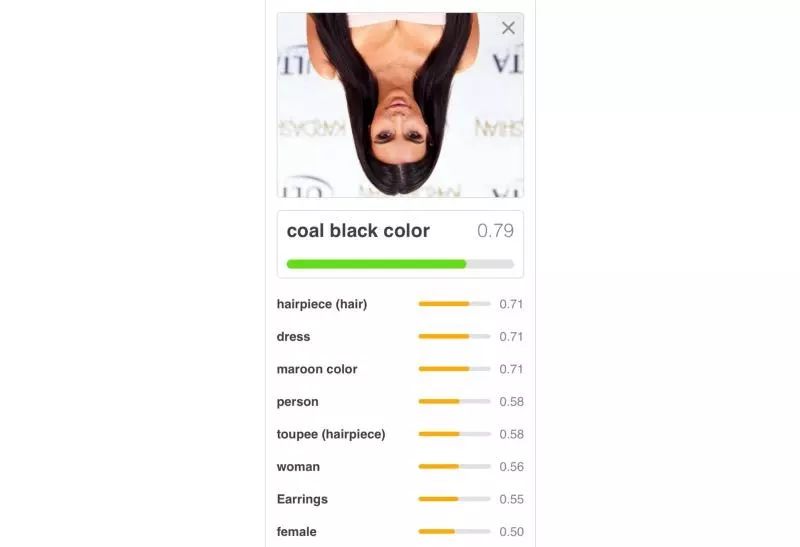
最后,有个很大的问题就是,CNN 很容易受到白盒攻击。
AI 前线注:白盒攻击,是指攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统交互。而黑盒攻击,攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。
基于以上的事实,Hinton 断言:CNN 注定要失败
Hinton 认为,当前标准 CNN 结构的层次太少,只有神经元、神经网络层、整个神经网络。跟真实的人类大脑神经网络相比,存在以下几个问题:
池化过程并没有很好地模仿大脑中形状知觉的心理过程:它不能解释为什么人类能将内在的坐标系映射到物体上,以及为什么这些坐标系这么重要;
池化解决的问题是错误的:我们想要的是信息的同变性而非不变性,是理清信息而非丢弃信息;
池化没有利用底层线性结构:它没有利用在图形中能很好地处理方差最大来源的自然线形流形;
池化在处理动态路由时很差劲:我们需要将输入信息的每一部分路由到知道如何处理它的神经元中,找到最佳的路径就是解析图像。
因此,需要把每一层的神经元组合起来,形成一个组,并装到“胶囊”( Capsule )中去,这样一来就能完成大量的内部计算,最终输出一个经过压缩的结果。
2017 年 10 月 26 日,Hinton 和 Sara Sabour 、 Nicholas Frosst 共同完成的论文《胶囊间动态路由》[6]( Dynamic Routing Between Capsules ),被 NIPS 2017 大会接受。这篇论文正式提出了胶囊( Capsules )的概念,这是一种神经网络的扭曲,旨在让机器通过图像或视频更好地了解世界。其目的在于弥补目前机器学习系统中限制有效性的缺陷。Google 和其他公司目前使用的图像识别软件都需大量的示例照片才能“习得”在各种情况下准确地识别对象的能力。造成这一状况是因为该软件不擅长将学到的东西在新的场景中泛化。比如,同一个物体从新视角观察也可以得出相同的结论。

Capsule 是一组神经元,其活动向量的矢量方向及方向分别代表实体化程度及实例参数,相同水平下的活跃 Capsule 可通过矩阵变换对更高级别的 Capsule 实体化参数进行预测。当多个预测一致时,高级别的 Capsule 将会更加活跃。
换句话说,Capsule 试图在神经网络内形成、抽象创建子网络。一个标准的神经网络,层与层之间是完全连接的(也就是说,层 1 中的每个神经元都可以访问层 0 中的每个神经元,并且本身被第 2 层中的每个神经元访问,以此类推),这种更复杂的图形拓扑似乎可以更有效地提高生成网络的有效性和可解释性。论文中提到的 Dynamic Routing,就是希望能够形成一种机制,让网络能够将适合某一层 Capsule 处理的内容,路由到对应的 Capsule 让其处理,从而形成了某种推断链。
胶囊网络能够充分利用空间关系,我们得以看到更多的东西,胶囊网络工作形式是类似以下简化代码所示:
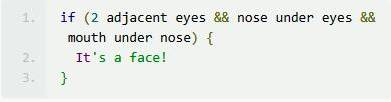
你应该能够看到,用胶囊网络来定义神经网络的话,就不会被 Kardashian 那张照片所愚弄了。
这种新架构在以下数据集上,也可以得到更高的精度。这个经过精心设计的数据集,是一个纯粹的形状识别任务,即使从不同的角度观察也能识别物体。胶囊网络击败了最先进的 CNN,将错误率降低了 45%。

CapsNet 识别同一类别(动物、人类、飞机、轿车、卡车等)的底部视图匹配对应顶部视图的能力远好于 CNN。除此之外,最近的论文表明,Capsule 在抵御白盒攻击的表现要比 CNN 强。
其实早在 2011 年,Hinton 就第一次提出了 Capsule[7],但那次没有成功,直至最近重新提出才引起广泛的关注。Capsule 的提出,得益于这三个相关领域的研究:神经解剖学、认知神经科学、计算机图形学。
Hinton 注意到目前大多数神经解剖学研究都支持(大部分哺乳类,特别是灵长类)大脑皮层中大量存在称为 Cortical minicolumn 的柱状结构(皮层柱),其内部含有上百个神经元,并存在内部分层。这意味着人脑中的一层并不是类似现在 NN 的一层,而是有复杂的内部结构。为什么大脑皮层中普遍存在 mini-column?这显然是一个重要的统计学证据,让 Hinton 愿意相信 mini-column 肯定起了什么作用。于是 Hinton 也提出了一个对应的结构,称为 Capsule(胶囊,和微皮层柱对应)。这就是 Capsule 的由来。
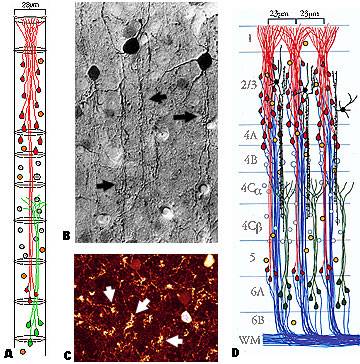
皮层柱(Cortical column,亦称 hypercolumn、macrocolumn、cortical module),是大脑皮层中可以被垂直表面的探针成功穿入的一群神经元,他们拥有几乎相同的感受野。微皮层柱(cortical minicolumn)中的神经元只能记录相同特征的信号,而皮层柱则是一个可以记录其相应感受野中全体有效信号的单元。
Hinton 从一些认知神经科学实验中,提出了猜想:物体和观察者之间的关系(比如物体的姿态),应该由一整套激活的神经元表示,而不是由单个神经元,或者一组粗编码( coarse-coded,此处意指类似一层中,并没有经过精细组织)的神经元表示。这样的表示比较适合实现类似“坐标框架”的原理。而这一整套神经元,Hinton 认为就是 Capsule。
教一台电脑从多角度识别一只猫,可能需要千万种不同的照片;但是让小孩学会识别,只需养一只宠物猫即可。对于如何缩小人工智能系统和普通幼儿之间的鸿沟,Hinton 的想法是在计算机视觉软件中储备更多的知识。
Capsule 就是一个虚拟神经元小组,被用来追踪物体的不同部位,比如猫的鼻子和耳朵,以及它们在空间中的相对位置。一个由许多 Capsule 组成的网络可以利用这一意识来理解新的场景实际上只是不同的视角观察的结果。
一个典型的 Capsule 将从多个低层次的 Capsule 中获得信息(多维预测向量),然后寻找一个预测的紧致束( tight cluster of predication )。如果它能够找到这个紧致束,那么它就会输出实体在这个域内类型存在的较高的概率,以及生成状态的重心(状态平均值)。这种方式可以很好地过滤掉噪声,因为较高维度的巧合发生的概率很小,所以 Capsule 的方法比“标准的神经网络”要好很多。
从某些方面来讲,胶囊网络与人工智能研究领域最近的趋势有所不同。神经网络的成功在于要把尽可能少的知识编码到人工智能软件,让机器自己从头开始计算。
Capsule 做出了一个很强大且具有代表性的假设:在图像的每一个位置,一个 Capsule 只表示实体类型的至多一个实例。这个假设受被称为“拥挤”(crowding,Pelli et al. [2004])的知觉现象的启发,能消除“绑定”(binding,Hinton[1981])问题,并允许一个 Capsule 使用一个分布表示(它的活动向量)在给定的位置编码该类型的实体的实例化参数。这种分布表示的有效性比通过在高维网格上激活一个点(并使用正确的分布表示)编码实例化参数呈指数增长。然后 Capsule 可以充分利用这样的事实,即空间关系可以通过矩阵乘法建模。
Capsule 利用和视角变化一致的神经活动,而不是尽可能地消除活动中的视角变化。这给了它们超越“归一化”方法如空间转换器网络(spatial transformer network)的优势(Jaderberg et al. [2015]):它们能同时处理多个不同目标(或目标部分)的多种仿射变换(AI 前线注:仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间)。
Capsule 也很擅长分割任务(这是计算机视觉中的另一个难题),因为实例化参数的向量允许它们使用路由协议机制(routing-by-agreement),正如研究者在论文中所证明的。
CapsNet 是 Hinton 在论文中提出的一个胶囊网络最简单的结构,用于解决这个问题:传统 CNN 在对图片信息提取的信息遗漏问题和深度学习模型对物体形状记忆的问题。简而言之,CapsNet 统一了计算机视觉里面的分类、检测、分割所有的任务。
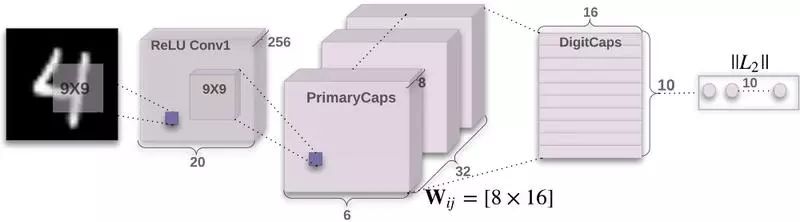
这里有一段在 IBM Watson 工作的 Nick Bourdakos 根据 Hinton 的论文进行训练的过程。完整代码见 GitHub:
https://github.com/naturomics/CapsNet-Tensorflow
为了使用胶囊网络模型,首先需要从 Git 仓库克隆远程库:
git clone https://github.com/bourdakos1/capsule-networks.git
然后安装需求文件 requirements.txt:
pip install -r requirements.txt
键入如下命令开始训练:
python main.py
MNIST 数据集拥有六万张训练图像。默认情况下,模型将以批处理大小为 128 作为一个单位 ,训练 50 轮(epochs)。每个轮数是一个训练集完整的训练过程。因为批处理大小为 128,因此每轮进行大约 468 个批处理。
需要注意的是,如果没有 GPU 的话,训练可能会非常耗时。如何加快训练速度,可以参阅这篇文章《用 TensorFlow 追踪千年隼号》[8](Tracking the Millennium Falcon with Tensorflow)。
如果模型经过充分的训练后,可以通过键入以下命令来测试:
python main.py --is_training False
Roland Memisevic,是蒙特利尔大学的教授、图像识别公司 Twenty Billion Neurons 创始人,他表示 Hinton 的基本设计应该能够从定量的数据中提取出比现有系统更多的信息。如果能够在规模上得到证实,那么将会对医疗保健等领域有所帮助。在这些领域,用于培训人工智能系统的图像数据远比互联网上的自拍照少得多。

Gary Marcus,纽约大学心理学教授,他曾向 Uber 出售一家人工智能初创公司,日前表示,Hinton 的最新作品展现了新气象。Marcus 认为人工智能研究应该多做一些事情,比如模拟大脑的内在机制,让机器学习视觉和语言等关键技能。
Marcus 说:“现在判断这项研究能走多远还为时过早,但是看到 Hinton 打破了这个领域的专有的惯例还是很好的。”(‘It’s too early to tell how far this particular architecture will go, but it’s great to see Hinton out of the rut that the field has seemed fixated on.’)
Hinton 的目标也很大,从他对 Capsule 的介绍中可以看到有冲击动态视觉内容、3D 视觉、无监督学习、NN 健壮性等几个疑难问题的意图。
Hinton 尚未成功,眼下, Capsule 并没有显著地提升神经网络的表现。但是,要知道,他研究反向传播的时候,也遇到了同样的情况,而且持续了近 30 年。Hinton 对《麻省理工科技评论》说:“胶囊理论一定是正确的,不成功只是暂时的。”[9](‘This thing just has to be right, and the fact that it doesn’t work is just a temporary annoyance.’)
就算 Capsule 真的会成为以后的趋势,Hinton 也未必这么快找到正确的训练算法;就算 Hinton 找到了正确的训练算法,也没有人能够保证,Capsules 的数量不及人脑中 mini-columns 数量的时候,就能够达到人类的识别率(何况现在 CNN 尽管问题多多,但其识别率在很多方面已远超人类了)。
从目前已经披露的信息看,Capsule 的概念会更仿生一些,能够更好地模拟人类大脑神经元之间的复杂连接结构,但对这个框架具体的数学描述仍有待于进一步研究。
现在,对 Capsule 的研究处于和本世纪初用 RNN 研究语音识别类似的阶段。有许多基本的具有代表性的理由使我们相信这是一个更好的方法,但在 Capsule 超越当前正高度发展的技术之前,还有很多细节需要考证。一个简单的 Capsule 系统已经能在分割重叠数字任务中表现出空前强大的性能,这种迹象提醒我们: Capsule 是一个值得探索的方向。
不可否认的是,在无监督学习的道路上,我们还有很长的一段路要走。强人工智能早晚会到来,只是我们还不知道是哪一天。
[1] 2007 NIPS Tutorial on:Deep Belief Networks:
https://www.cs.toronto.edu/~hinton/nipstutorial/nipstut3.pdf
[2] Learning representations by back-propagating errors:
https://www.nature.com/articles/323533a0
[3] Artificial intelligence pioneer says we need to start over:
https://www.axios.com/ai-pioneer-advocates-starting-over-2485537027.html
[4] Convolutional Neural Networks (LeNet):
http://deeplearning.net/tutorial/lenet.html
[5] CSC2535:2013, Advanced Machine Learning, Taking Inverse Graphics Seriously:
https://www.cs.toronto.edu/~hinton/csc2535/notes/lec6b.pdf
[6] Learning representations by back-propagating errors:
https://www.nature.com/articles/323533a0
[7] Transforming Auto-encoders:
http://www.cs.toronto.edu/~fritz/absps/transauto6.pdf
[8] Artificial intelligence pioneer says we need to start over:
https://www.axios.com/ai-pioneer-advocates-starting-over-2485537027.html
[9] Is AI Riding a One-Trick Pony?:
https://www.technologyreview.com/s/608911/is-ai-riding-a-one-trick-pony/
点击下方图片即可阅读

所有人都在评论新发布的智能音箱时,我们挖出了百度背后的这家瑞典小公司

人工智能已不再停留在大家的想象之中,各路大牛也都纷纷抓住这波风口,投入 AI 创业大潮。那么,2017 年,到底都有哪些 AI 落地案例呢?机器学习、深度学习、NLP、图像识别等技术又该如何用来解决业务问题?
2018 年 1 月 11-14 日,AICon 全球人工智能技术大会上,一些大牛将首次分享 AI 在金融、电商、教育、外卖、搜索推荐、人脸识别、自动驾驶、语音交互等领域的最新落地案例,应该能学到不少东西。目前大会 8 折报名倒计时,更多精彩可点击阅读原文详细了解。



