人大魏哲巍:图神经网络的理论基础


01
图的基本定义

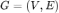 中,我们将节点集合定义为 V,其节点个数为 n;边集为 E,其节点个数为 m。若节点 i 和节点 j 之间存在连接关系(边),则邻接矩阵 A 中对应的元素
中,我们将节点集合定义为 V,其节点个数为 n;边集为 E,其节点个数为 m。若节点 i 和节点 j 之间存在连接关系(边),则邻接矩阵 A 中对应的元素
 值为 1,否则该元素的值为 0, A 为一个对称矩阵。ji矩阵 D 为一个对角矩阵,第 i 行对角线上的元素
值为 1,否则该元素的值为 0, A 为一个对称矩阵。ji矩阵 D 为一个对角矩阵,第 i 行对角线上的元素
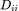 为节点 i 的邻居节点的数量。归一化后的邻接矩阵 P 为邻接矩阵 A 分别左乘、右乘
为节点 i 的邻居节点的数量。归一化后的邻接矩阵 P 为邻接矩阵 A 分别左乘、右乘
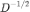 ,其中对角矩阵
对角线上的元素为度矩阵 D 对角线上每个对应元素开根号、取倒数后的结果。归一化后的拉普拉斯矩阵为单位矩阵 I 与归一化后的邻接矩阵 P 之差。
,其中对角矩阵
对角线上的元素为度矩阵 D 对角线上每个对应元素开根号、取倒数后的结果。归一化后的拉普拉斯矩阵为单位矩阵 I 与归一化后的邻接矩阵 P 之差。
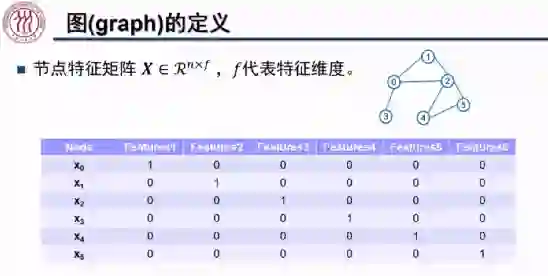
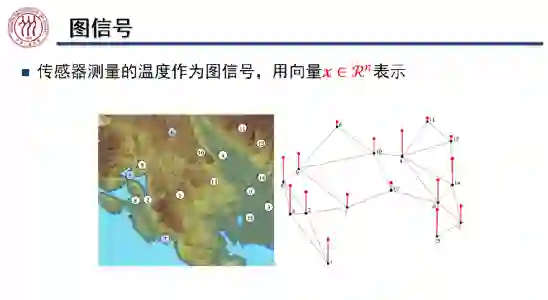
 ,其中 n 为节点个数,f 为特征维度。例如,上图中六个节点的特征分别为一个维数为六的 one-hot 向量。
,其中 n 为节点个数,f 为特征维度。例如,上图中六个节点的特征分别为一个维数为六的 one-hot 向量。
02
图神经网络概述
图卷积神经网络(GCN)
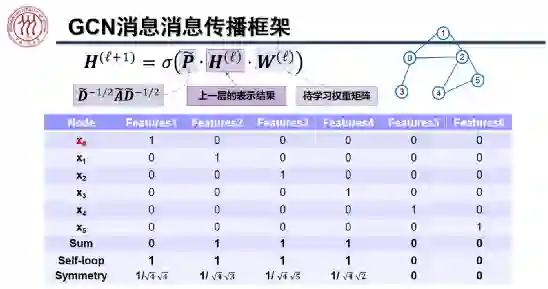
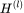 为第 l 层的表示结果,
为第 l 层的表示结果,
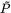 为每个节点带有自环的正则化之后的邻接矩阵,
为每个节点带有自环的正则化之后的邻接矩阵,
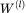 为待学习的权重矩阵,
为待学习的权重矩阵,
 为非线性激活函数。上图中从上往下数最后三行为计算节点 0 表示的过程。
为非线性激活函数。上图中从上往下数最后三行为计算节点 0 表示的过程。
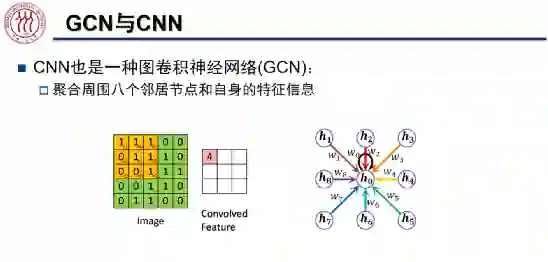
 周围的八个邻居节点及其自身的信息聚合起来,得到了新的表征。值得注意的是,在 CNN 中,每个节点与中心节点在信息聚合时的权值 w 是可以通过学习得到的,而 GCN 中节点之间的聚合权值仅由每个节点的度决定。
周围的八个邻居节点及其自身的信息聚合起来,得到了新的表征。值得注意的是,在 CNN 中,每个节点与中心节点在信息聚合时的权值 w 是可以通过学习得到的,而 GCN 中节点之间的聚合权值仅由每个节点的度决定。
03
图神经网络的三个视角
滤波器:GNN 的谱域解释

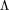 为对角矩阵,对角线上的值为特征值,特征值的取值范围为 [0,2]。
为对角矩阵,对角线上的值为特征值,特征值的取值范围为 [0,2]。
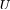 和
和
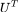 为正交矩阵,
的每一个分量为拉普拉斯矩阵 L 的特征向量,其二范数为 1。由于 L 为对称矩阵,所以
的任意两个特征向量正交,即点积为零。由于
和
为正交矩阵,则二者乘积为单位矩阵,因此图信号的傅里叶变换和傅里叶逆变换的关系成立。
为正交矩阵,
的每一个分量为拉普拉斯矩阵 L 的特征向量,其二范数为 1。由于 L 为对称矩阵,所以
的任意两个特征向量正交,即点积为零。由于
和
为正交矩阵,则二者乘积为单位矩阵,因此图信号的傅里叶变换和傅里叶逆变换的关系成立。
 ,相当于对笛卡尔坐标系下的图信号
,相当于对笛卡尔坐标系下的图信号
 旋转,将其变换到由
中特征向量组成的正交基坐标下。
旋转,将其变换到由
中特征向量组成的正交基坐标下。

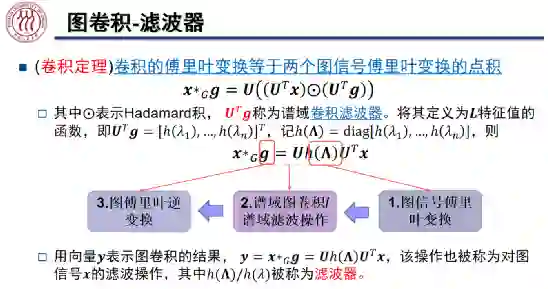 进行滤波的过程中,我们首先对图信号进行傅里叶变换,接着我们对频谱域中的特征值做滤波操作,过滤掉某些频率的信息,进而将滤波后的信号通过图傅里叶逆变换转换到原始空间中。其中,
进行滤波的过程中,我们首先对图信号进行傅里叶变换,接着我们对频谱域中的特征值做滤波操作,过滤掉某些频率的信息,进而将滤波后的信号通过图傅里叶逆变换转换到原始空间中。其中,
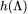 /
/
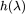 为滤波器,当
都等于 1 时,该滤波器相当于一个全通滤波器。
为滤波器,当
都等于 1 时,该滤波器相当于一个全通滤波器。
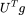 为谱域的卷积滤波器,它是 L 特征值的函数。如上图所示,图上的卷操作可以写作图傅里叶变换的形式。
为谱域的卷积滤波器,它是 L 特征值的函数。如上图所示,图上的卷操作可以写作图傅里叶变换的形式。
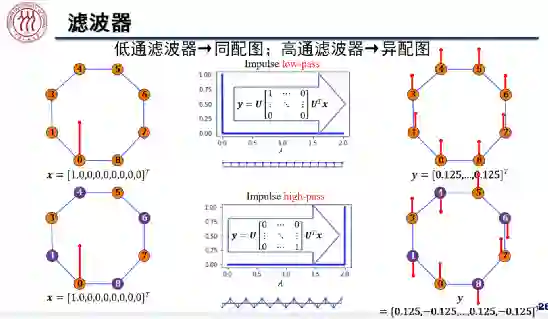 的规模过大,特征值分解的复杂度太高。为此,目前主流的图卷积神经网络算法采用多项式近似滤波器,从而降低计算复杂度。
的规模过大,特征值分解的复杂度太高。为此,目前主流的图卷积神经网络算法采用多项式近似滤波器,从而降低计算复杂度。

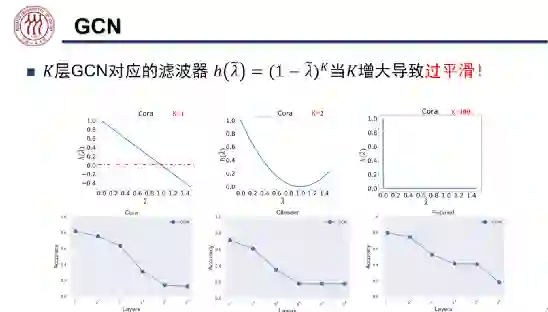

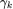 。
大于等于零时,该网络相当于低通滤波器;
。
大于等于零时,该网络相当于低通滤波器;
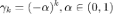 时,该网络相当于高通滤波器。然而,该架构缺乏可解释性,不能解释学到的任意滤波器。
时,该网络相当于高通滤波器。然而,该架构缺乏可解释性,不能解释学到的任意滤波器。
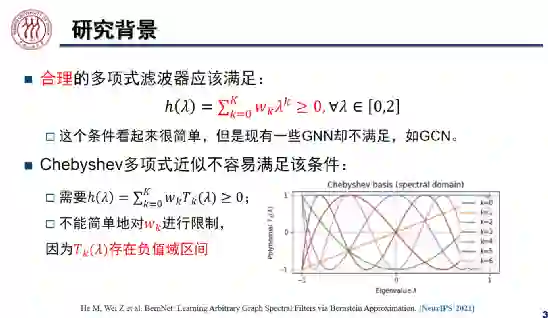
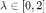 ,合理的多项式滤波器
,合理的多项式滤波器
 。若
小于零,图神经网络的滤波结果会随着层数的奇偶变化震荡。然而,GCN 等图神经网络并不满足上述条件。
。若
小于零,图神经网络的滤波结果会随着层数的奇偶变化震荡。然而,GCN 等图神经网络并不满足上述条件。

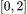 区间内非负的任意多项式可以写成 Bernstein 多项式的形式,该多项式的系数
区间内非负的任意多项式可以写成 Bernstein 多项式的形式,该多项式的系数
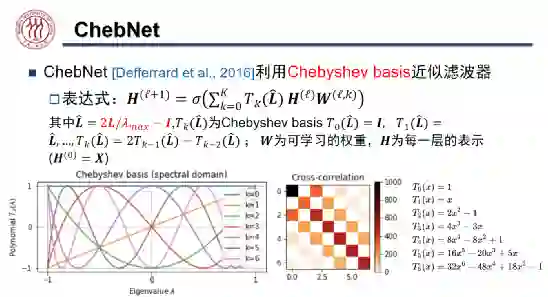
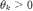 ,我们可以用一组 Bernstein 基线性近似任意多项式,从而学习任意的滤波器。受此启发,我们将 BernNet 模型定义为:
,我们可以用一组 Bernstein 基线性近似任意多项式,从而学习任意的滤波器。受此启发,我们将 BernNet 模型定义为:
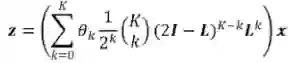
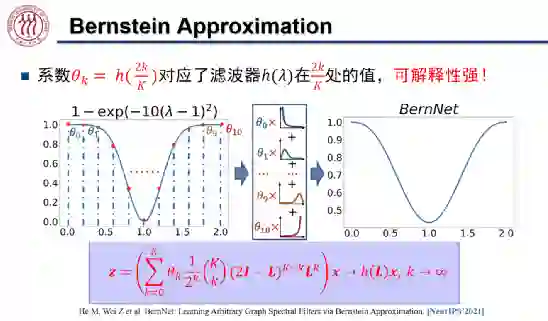
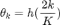 对应滤波器
在
对应滤波器
在
 处的函数值。如上图所示,假设滤波器函数为拒绝中频信号的
处的函数值。如上图所示,假设滤波器函数为拒绝中频信号的
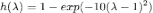 ,我们将[0,2]均匀分成 k 分,将「0」、「2」及每个分位数对应的
,我们将[0,2]均匀分成 k 分,将「0」、「2」及每个分位数对应的
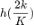 定义为系数
定义为系数
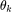 。我们将这组系数与对应的伯恩斯坦多项式线性组合起来就得到了右侧 BernNet 的曲线。为了保证
,我们只需将
重参数化为
。我们将这组系数与对应的伯恩斯坦多项式线性组合起来就得到了右侧 BernNet 的曲线。为了保证
,我们只需将
重参数化为
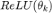 ,从而保证该滤波器的值恒大于等于零。这样一来,我们就可以学习任意的滤波器,且拟合精度随着 k 的增加而提升。
,从而保证该滤波器的值恒大于等于零。这样一来,我们就可以学习任意的滤波器,且拟合精度随着 k 的增加而提升。
随机游走:GNN 的空域解释
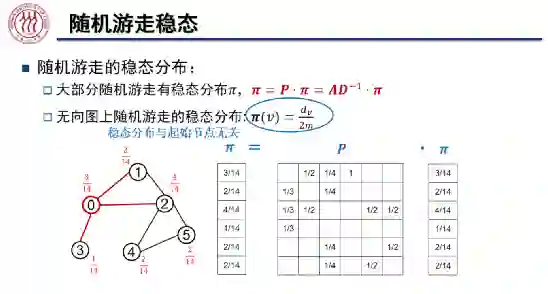
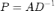 。大部分随机游走过程会收敛到某个稳态上,即
。大部分随机游走过程会收敛到某个稳态上,即
 。在无向图上,节点 v 处的稳态为
。在无向图上,节点 v 处的稳态为
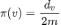 ,即 v 点的度除以两倍的图中边总数。可见,稳态分布与随机游走的起始节点无关。我们可以通过 Cheeger 不等式刻画在随机游走中收敛的速度,该不等式也可以被用于社区发现:
,即 v 点的度除以两倍的图中边总数。可见,稳态分布与随机游走的起始节点无关。我们可以通过 Cheeger 不等式刻画在随机游走中收敛的速度,该不等式也可以被用于社区发现:
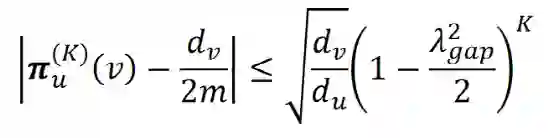
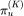 为从节点 u 开始的第 K 步随机游走,
为从节点 u 开始的第 K 步随机游走,
 为拉普拉斯矩阵最小的非零特征值。
为拉普拉斯矩阵最小的非零特征值。

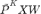 ,将归一化后的邻接矩阵展开后,可得
,将归一化后的邻接矩阵展开后,可得
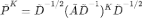 。其中
。其中
 为 K 步随机游走后的概率分布,随着 K 的增大会收敛到稳态。也就是说,最终的图表示只与图的结构相关,与随机游走初始节点无关。随着图卷积网络层数加深,网络会逐渐「忘记」初始特征,出现过平滑现象,导致节点分类效果较差。
为 K 步随机游走后的概率分布,随着 K 的增大会收敛到稳态。也就是说,最终的图表示只与图的结构相关,与随机游走初始节点无关。随着图卷积网络层数加深,网络会逐渐「忘记」初始特征,出现过平滑现象,导致节点分类效果较差。


 的概率返回初始状态,有
的概率返回初始状态,有
 的概率随机走向当前节点的任一邻居,此时稳态的分布就与起始节点有关了。这种随机游走与 PageRank 算法使用的方法类似。
的概率随机走向当前节点的任一邻居,此时稳态的分布就与起始节点有关了。这种随机游走与 PageRank 算法使用的方法类似。
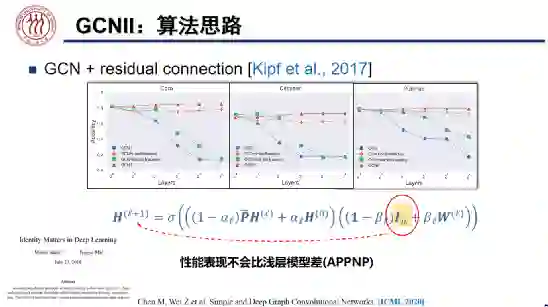
优化函数:GNN Deep Unfolding

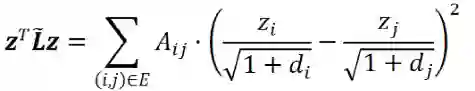
 ),此时会失去初始特征,出现过平滑现象。
),此时会失去初始特征,出现过平滑现象。
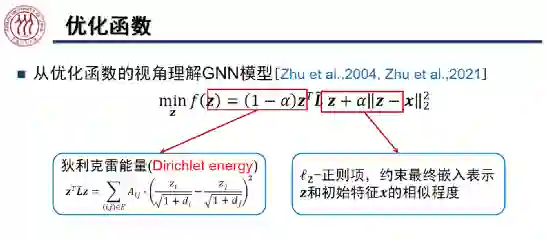


 为拉普拉斯矩阵的函数,其特征值
为拉普拉斯矩阵的函数,其特征值
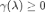 ,从而保证了上述优化函数为凸函数。该框架非常灵活,当
,从而保证了上述优化函数为凸函数。该框架非常灵活,当
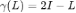 时,狄利克雷能量函数变为了:
时,狄利克雷能量函数变为了:
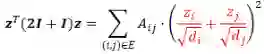
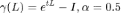 时,节点的表征为热核形式,可以用来解释 GDC、GraphHeat 的设计,优化函数的最优解为:
时,节点的表征为热核形式,可以用来解释 GDC、GraphHeat 的设计,优化函数的最优解为:
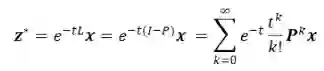

 ,我们可以给 z 中小于 0 的项施加正无穷的惩罚。此时,近端算子对应于激活函数 ReLU。
,我们可以给 z 中小于 0 的项施加正无穷的惩罚。此时,近端算子对应于激活函数 ReLU。
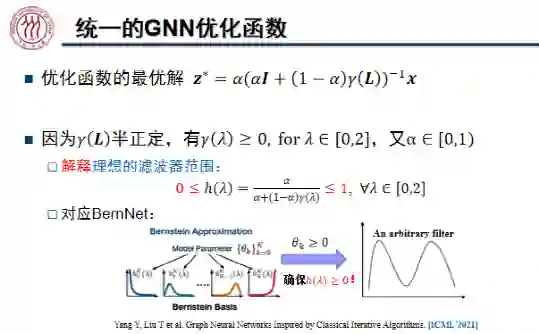 对拉普拉斯矩阵进行特征值分解,相当于进行了滤波操作。当
半正定时,图神经网络即为 BernNet。
对拉普拉斯矩阵进行特征值分解,相当于进行了滤波操作。当
半正定时,图神经网络即为 BernNet。

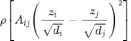 定义图中边的平滑程度,则该函数的切线斜率决定了 GAT 的注意力权重。基于上述思想,魏哲巍教授团队设计了新的 GNN 模型 TWIRLS,使用迭代重加权最小二乘法解该优化问题。
定义图中边的平滑程度,则该函数的切线斜率决定了 GAT 的注意力权重。基于上述思想,魏哲巍教授团队设计了新的 GNN 模型 TWIRLS,使用迭代重加权最小二乘法解该优化问题。
04
结语
登录查看更多
相关内容

魏哲巍,教授,博导。研究方向为大数据算法理论、图机器学习。2008年本科毕业于北京大学数学科学学院,2012年博士毕业于香港科技大学计算机系;2012-2014年于丹麦奥胡斯大学担任博士后研究员,2014年9月加入中国人民大学信息学院担任副教授,2019年8月破格晋升教授,2020年9月加入中国人民大学高瓴人工智能学院。在数据库、理论计算机、数据挖掘、机器学习等领域的顶级会议及期刊上(如SIGMOD、VLDB、ICML、NeurIPS、KDD、SODA等)发表论文50余篇。担任PODS、ICDT等大数据理论会议论文集主席以及VLDB、KDD、ICDE、ICML、NeurIPS等顶级会议程序委员会委员。主持自然科学基金青年项目、面上项目及重点项目子课题,担任人工智能与数字经济广东省实验室(广州)(简称琶洲实验室)青年科学家。



相关VIP内容
相关资讯
相关论文