CVPR2020 | CARS: 华为提出基于进化算法和权值共享的神经网络结构搜索,CIFAR-10上仅需单卡半天
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

为了优化进化算法在神经网络结构搜索时候选网络训练过长的问题,参考ENAS和NSGA-III,论文提出连续进化结构搜索方法(continuous evolution architecture search, CARS),最大化利用学习到的知识,如上一轮进化的结构和参数。首先构造用于参数共享的超网,从超网中产生子网,然后使用None-dominated排序策略来选择不同大小的优秀网络,整体耗时仅需要0.5 GPU day
论文: CARS: Continuous Evolution for Efficient Neural Architecture Search

-
论文地址:https://arxiv.org/abs/1909.04977
Introduction
目前神经网络结构搜索的网络性能已经超越了人类设计的网络,搜索方法大致可以分为强化学习、进化算法以及梯度三种,有研究表明进化算法能比强化学习搜索到更好的模型,但其搜索耗时较多,主要在于对个体的训练验证环节费事。可以借鉴ENSA的权重共享策略进行验证加速,但如果直接应用于进化算法,超网会受到较差的搜索结构的影响,因此需要修改目前神经网络搜索算法中用到的进化算法。为了最大化上一次进化过程学习到的知识的价值,论文提出了连续进化结构搜索方法(continuous evolution architecture search, CARS)
首先初始化一个有大量cells和blocks的超网(supernet),超网通过几个基准操作(交叉、变异等)产生进化算法中的个体(子网),使用Non-dominated 排序策略来选取几个不同大小和准确率的优秀模型,然后训练子网并更新子网对应的超网中的cells,在下一轮的进化过程会继续基于更新后的超网以及non-dominated排序的解集进行。另外,论文提出一个保护机制来避免小模型陷阱问题
Approach
论文使用基因算法(GA)来进行结构进化,GA能提供很大的搜索空间,对于结构集 , 为种群大小。在结构优化阶段,种群内的结构根据论文提出的pNSGA-III方法逐步更新。为了加速,使用一个超网 用来为不同的结构共享权重 ,能够极大地降低个体训练的计算量
Supernet of CARS
从超网
中采样不同的网络,每个网络
可以表示为浮点参数集合
以及二值连接参数集合
,其中0值表示网络不包含此连接,1值则表示使用该连接,即每个网络
可表示为
对
完整的浮点参数集合
是在网络集合中共享,如果这些网络结构是固定的,最优的
可通过标准反向传播进行优化,优化的参数
适用于所有网络
以提高识别性能。在参数收敛后,通过基因算法优化二值连接
,参数优化阶段和结构优化阶段是CARS的主要核心
Parameter Optimization
参数 为网络中的所有参数,参数 , 为mask操作,只保留 对应位置的参数。对于输入 ,网络的结果为 , 为 -th个网络, 为其参数
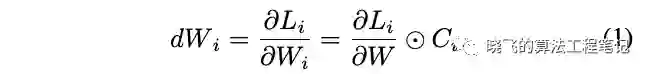
给定GT ,预测的损失为 ,则 的梯度计算如公式1
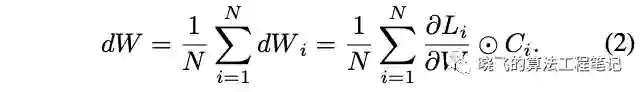
由于参数 应该适用于所有个体,因此使用所有个体的梯度来计算 的梯度,计算如公式2,最终配合SGD进行更新
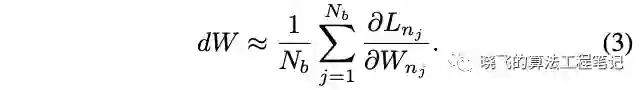
由于已经得到大量带超网共享参数的结构,每次都集合所有网络梯度进行更新会相当耗时,可以借鉴SGD的思想进行min-batch更新。使用 个不同的网络进行参数更新,编号为 。计算如公式3,使用小批量网络来接近所有网络的梯度,能够极大地减少优化时间,做到效果和性能间的平衡
Architecture Optimization
对于结构的优化过程,使用NSGA-III算法的non-dominated排序策略进行。标记 为 个不同的网络, 为希望优化的 个指标,一般这些指标都是有冲突的,例如参数量、浮点运算量、推理时延和准确率,导致同时优化这些指标会比较难

首先定义支配(dominate)的概念,假设网络
的准确率大于等于网络
,并且有一个其它指标优于网络
,则称网络
支配网络
,在进化过程网络
可被网络
代替。利用这个方法,可以在种群中挑选到一系列优秀的结构,然后使用这些网络来优化超网对应部分的参数
尽管non-dominated排序能帮助选择的更好网络,但搜索过程仍可能会存在小模型陷阱现象。由于超网的参数仍在训练,所以当前轮次的模型不一定为其最优表现,如果存在一些参数少的小模型但有比较高的准确率,则会统治了整个搜索过程。因此,论文基于NSGA-III提出pNSGA-III,加入准确率提升速度作为考虑
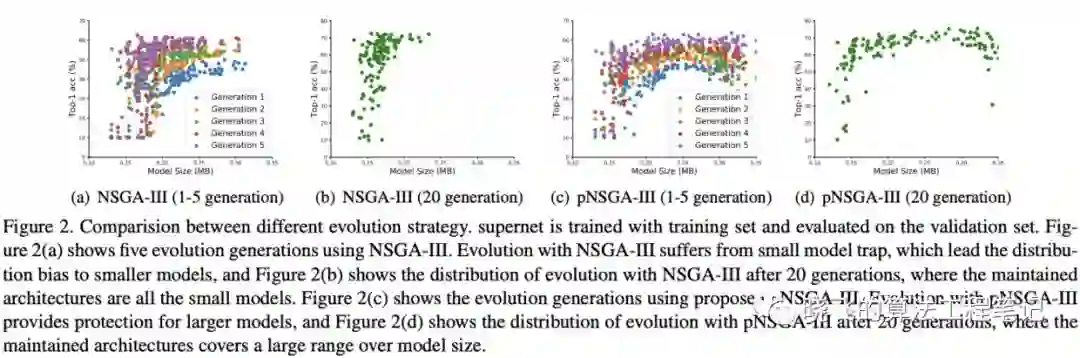
假设优化目标为模型参数和准确率,对于NSGA-III,会根据两个不同的指标进行non-dominated排序,然后根据帕累托图进行选择。而对于pNSGA-III,额外添加考虑准确率的增长速度的non-dominated排序,最后结合两种排序进行选择。这样,准确率增长较慢的大模型也能得到保留。如图2所示,pNSGA-III很明显保留的模型大小更广,且准确率与NSGA-III相当
Continuous Evolution for CARS

CARS算法的优化包含两个步骤,分别是网络结构优化和参数优化,另外,在初期也会使用参数warmup
-
Parameter Warmup,由于超网的共享权重是随机初始化的,如果结构集合也是随机初始化,那么出现最多的block的训练次数会多于其它block。因此,使用均分抽样策略来初始化超网的参数,公平地覆盖所有可能的网络,每条路径都有平等地出现概率,每种层操作也是平等概率,在最初几轮使用这种策略来初始化超网的权重 -
Architecture Optimization,在完成超网初始化后,随机采样 个不同的结构作为父代, 为超参数,后面pNSGA-III的筛选也使用。在进化过程中生成 个子代, 是用于控制子代数的超参,最后使用pNSGA-III从 中选取 个网络用于参数更新 -
Parameter Optimization,给予网络结构合集,使用公式3进行小批量梯度更新
Search Time Analysis
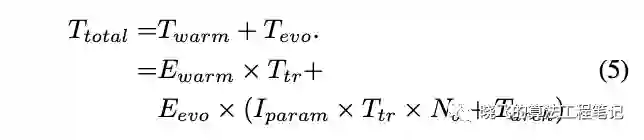
CARS搜索时,将数据集分为数据集和验证集,假设单个网络的训练耗时为 ,验证耗时 ,warmup共 周期,共需要 时间来初始化超网 的参数。假设进化共 轮,每轮参数优化阶段对超网训练 周期,所以每轮进化的参数优化耗时, 为mini-batch大小。结构优化阶段,所有个体是并行的,所以搜索耗时为 。CARS的总耗时如公式5
Experiments
Experimental Settings
-
supernet Backbones
超网主干基于DARTS的设置,DARTS搜索空间包含8个不同的操作,包含4种卷积、2种池化、skip连接和无连接,搜索normal cell和reduction cell,分别用于特征提取以及下采样,搜索结束后,根据预设将cell堆叠起来
-
Evolution Details
在DARTS中,每个中间节点与之前的两个节点连接,因此每个节点有其独立的搜索空间,而交叉和变异在搜索空间相对应的节点中进行,占总数的比例均为0.25,其余0.5为随机生成的新结构。对于交叉操作,每个节点有0.5的概率交叉其连接,而对于变异,每个节点有0.5的概率随机赋予新操作
Experiments on CIFAR-10
-
Small Model Trap
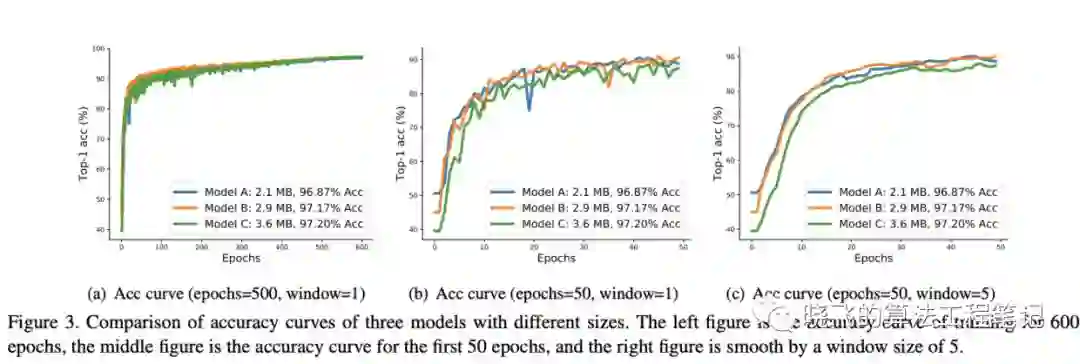
图3训练了3个不同大小的模型,在训练600轮后,模型的准确率与其大小相关,从前50轮的曲线可以看出小模型陷阱的原因:
-
小模型准确率上升速度较快 -
小模型准确率的波动较大
在前50轮模型C一直处于下风,若使用NSGA算法,模型C会直接去掉了,这是需要使用pNSGA-III的第一个原因。对于模型B和C,准确率增长类似,但由于训练导致准确率波动,一旦模型A的准确率高于B,B就会被去掉,这是需要使用pNSGA-III的第二个原因
-
NSGA-III vs. pNSGA-III
如图2所示,使用pNSGA-III能避免小模型陷阱,保留较大的有潜力的网络
-
Search on CIFAR-10
将CIFAR分为25000张训练图和25000张测试图,共搜索500轮,参数warmup共50轮,之后初始化包含128个不同网络的种群,然后使用pNSGA-III逐渐进化,参数优化阶段每轮进化训练10周期,结构优化阶段根据pNSGA-III使用测试集进行结构更新
-
Search Time analysis
对于考量模型大小和准确率的实验,训练时间 为1分钟,测试时间 为5秒,warmup阶段共50轮,大约耗费1小时。而连续进化算法共 轮,对于每轮结构优化阶段,并行测试时间为 ,对于每轮的参数优化阶段,设定 , 大约为10分钟, 大约为9小时,所以 为0.4 GPU day,考虑结构优化同时要计算时延,最终时间大约为0.5 GPU day
-
Evaluate on CIFAR-10
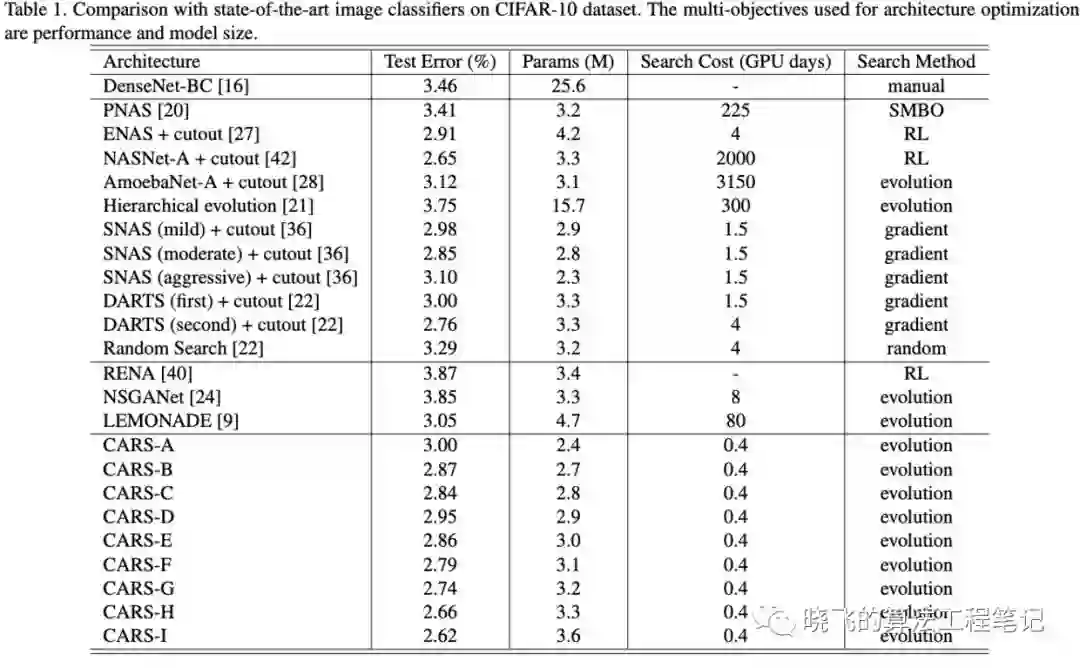
在完成CARS算法搜索后,保留128个不同的网络,进行更长时间的训练,然后测试准确率
-
Comparison on Searched Block
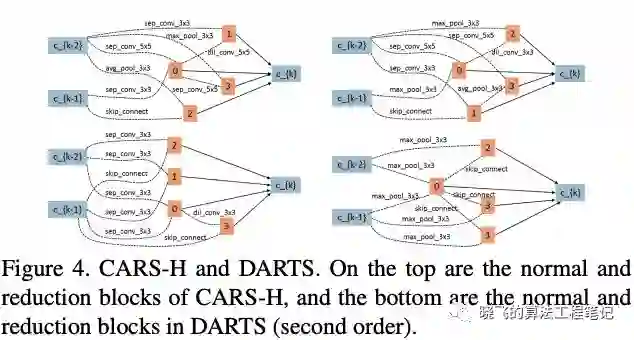
CARS-H与DARTS参数相似,但准确率更高,CARS-H的reduction block包含更多的参数,而normal block包含更少的参数,大概由于EA有更大的搜索空间,而基因操作能更有效地跳出局部最优解,这是EA的优势
Evaluate on ILSVRC2012
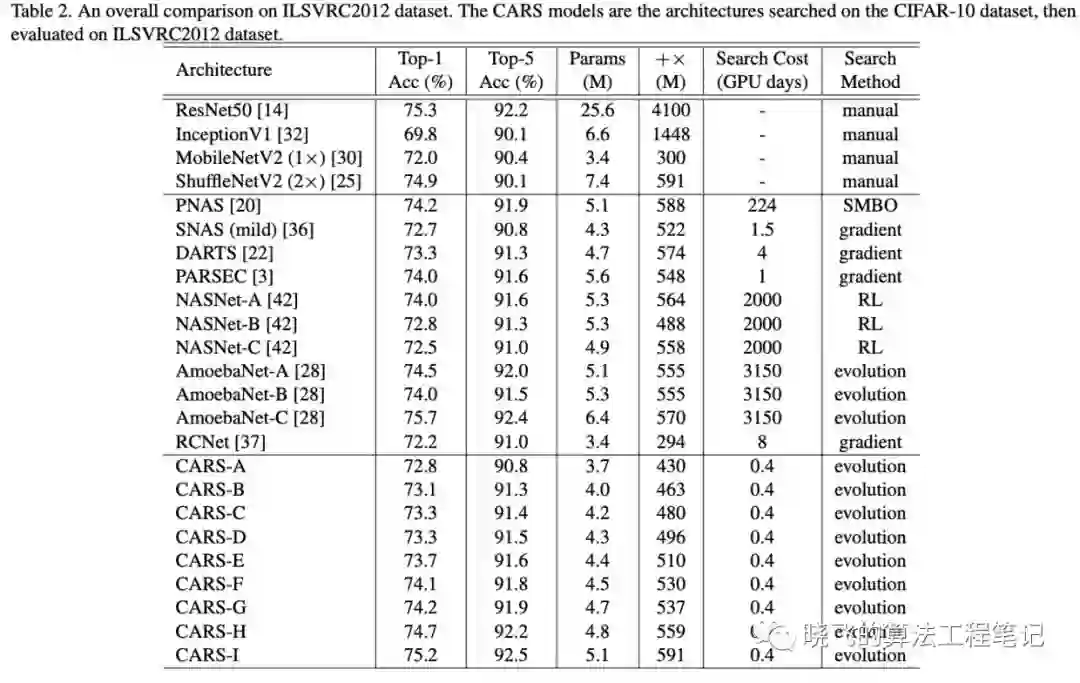
将在CIFAR-10上搜索到网络迁移到ILSVRC22012数据集,结果表明搜索到的结构具备迁移能力
CONCLUSION
为了优化进化算法在神经网络结构搜索时候选网络训练过长的问题,参考ENAS和NSGA-III,论文提出连续进化结构搜索方法(continuous evolution architecture search, CARS),最大化利用学习到的知识,如上一轮进化的结构和参数。首先构造用于参数共享的超网,从超网中产生子网,然后使用None-dominated排序策略来选择不同大小的优秀网络,整体耗时仅需要0.5 GPU day
参考内容
-
Pareto相关理论 (https://blog.csdn.net/qq_34662278/article/details/91489077)
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-NAS交流群已成立
扫码添加CVer助手,可申请加入CVer-NAS微信交流群,旨在交流AutoML(NAS)等的学习、科研、工程项目等内容。
一定要备注:研究方向+地点+学校/公司+昵称(如NAS+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!