NAS发展史:从放弃到入门
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:梦里风林
https://zhuanlan.zhihu.com/p/71547478
本文已获作者授权,未经允许,不得二次转载
NAS曾经需要庞大的GPU开销,使得许多人望而却步,但得益于学者们的努力,如今的NAS已经到了普通实验室也能尝试的水平,故曰,从放弃到入门。
本文以Quoc V. Le的研究为脉络,梳理一波NAS领域的重要论文(持续完善中)。
NIPS2016 Learning to learn by gradient descent by gradient descent
重要性:※
arxiv.org/pdf/1606.0447
简述:可能是最早提出网络结构自动学习的文章,也是Google的,作者里边没有QVL,但思路和后面的几篇很一致,用RNN做Teacher,搜索空间仅限学习率。
ICLR2017 Neural Architecture Search with Reinforcement Learning
arxiv.org/abs/1611.0157
重要性:※ ※ ※ ※ ※
简述:第一篇提出NAS概念的论文,将网络的结构表达为一个可变长的字符串,用一个RNN来生成这个字符串,这个字符串对应的子网络训练后可以得到一个accuracy作为reward,求这个reward对RNN参数的梯度,优化RNN,从而使得RNN输出更好的string。非常之黑箱和暴力。最巧妙的地方在于这个string的设计。效果还行。
RNN是一个两层LSTM,每层的隐含层大小为35.
这个字符串描述的就是每层卷积的参数值,当然,卷积后面都是跟一个BN和Relu的,实操中,为了减小搜索空间,filter height和width限定在[1,3,5,7]搜索,filter限定在[24,36,48,64]s搜索;stride有两种策略,一种是只能为1,一种是在[1,2,3]之间搜;RNN预测的就是每一层的某个参数在这些限定取值上的概率。
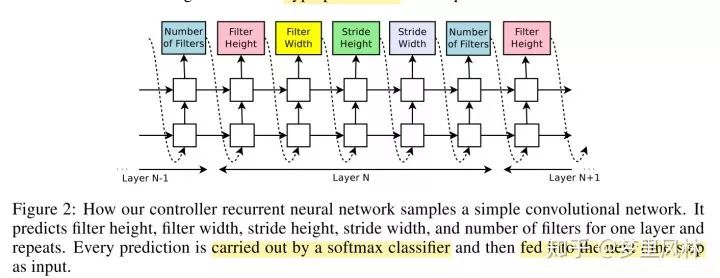
为了在layer之间增加skip connection,这篇论文还另外为第N层输出一个N-1的向量,这个向量的值代表是否要将前一层连进来作为input;连接prev层的概率如下计算:
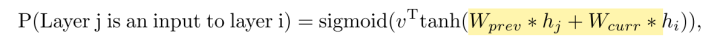
为了避免一些兼容问题,如果某一层预测出来没有input,则用原图做为input,如果某一层的output没有被人作为input,则concat到最后一层的output中,如果某一层的几个input大小不同,则为小的input填0,然后在depth维度concat;
资源:800个GPU同时各train一个网络;共28天
效果还行(CIFAR):
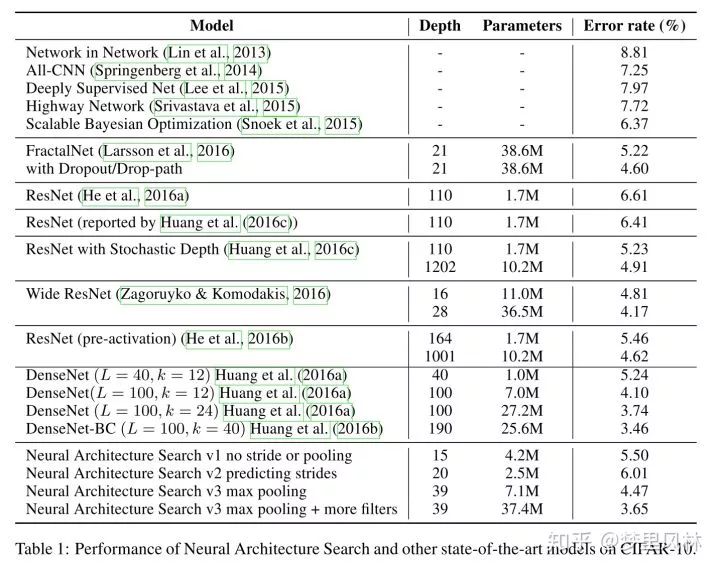
more filters版本是在搜出来的基础上,每层的增加了40个filter。。。
CVPR2018: Learning Transferable Architectures for Scalable Image Recognition
arxiv.org/abs/1707.0701
重要性:※ ※ ※ ※ ※
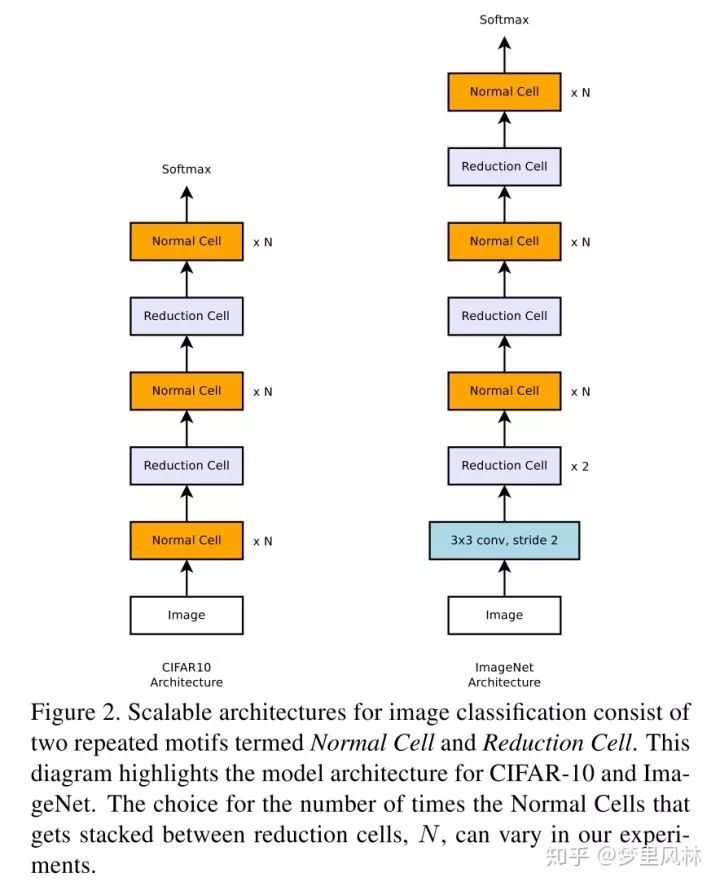
简述:改进了搜索空间,从搜超参到搜block cell结构,准确性达到SOTA(人称NASNet),而且提出在proxy dataset,一个小数据集(比如CIFAR10)上搜索,然后迁移到大数据集(ImageNet)上,并且在大数据集上也有比较好的表现,所以说这个架构是transferable的。
整个网络的框架是人工决定的,不同layer的cell是一样的结构,不同的权重,但这样会有size不变的问题,因此搞了一种normal cell,输出和输入hw相同,还有一种reduction cell,stride为2,达到减size的目的,并且filter会加倍。框架如图:
cell怎么搜
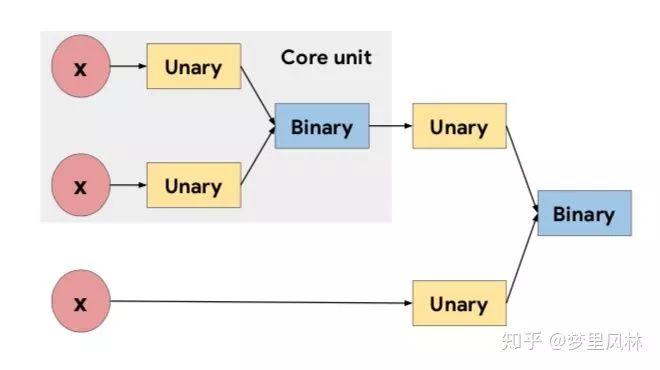
论文说的非常绕,我来一句话总结一下:在每个cell里,搜 y = g(f1(x1), f2(x2)) B次;
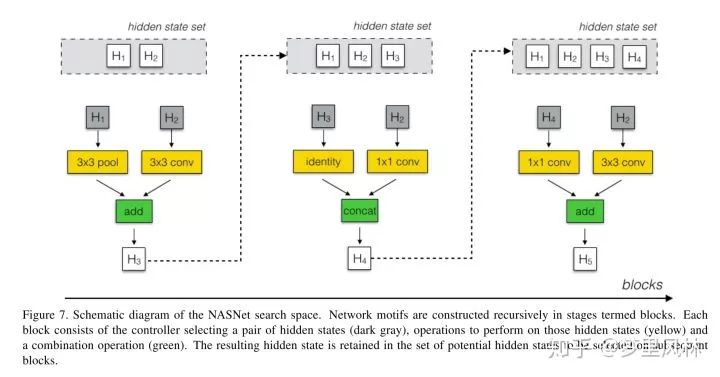
首先,决定哪些东西作为输入(x1, x2),可选的输入即前几次搜索的输出;(这样就可能造成skip connection)
然后决定对每个输入各做什么操作,f1和f2,可选的操作有:

然后选择怎么组合两个操作的结果g,可选的组合有add和concat;
最后,对于B次搜索的所有没有被作为输入的结果(当然包含了最后一次搜索的输出),concat起来作为cell最后的输出;
g的组合还可以包含LN和IN,NASNet-A是不包含的,NASNet-B和NASNet-C是包含的,NASNet-B更骚一点,整个cell最后组合的时候,把所有搜索的输出都concat进来了;
为了同时搜Normal Cell和Reduction Cell,一个cell里会搜2B次,前B次作为Normal Cell,后B次作为Reduction Cell;
资源:500个GPU,7天
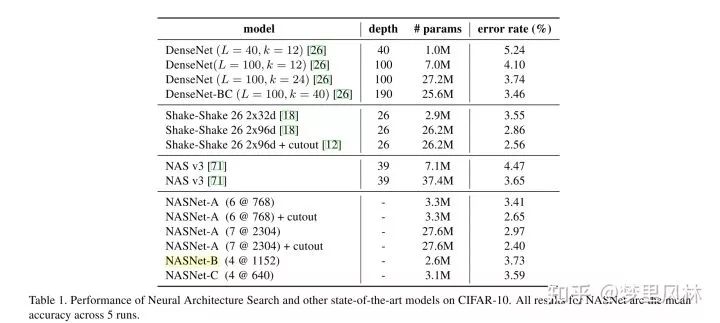
效果:(6@768表示block重复6次,最后一个CNN有768个filter)
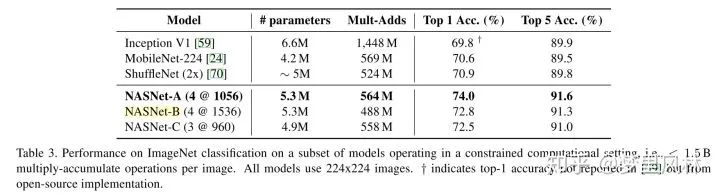
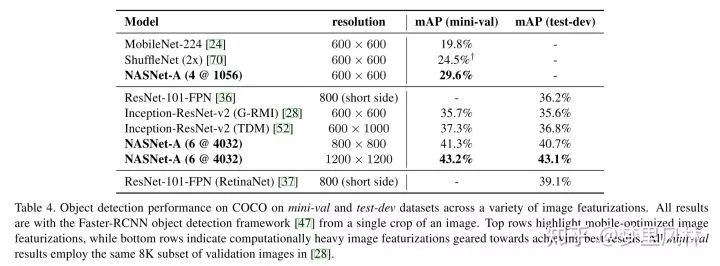
甚至开始在COCO上跑
ICML2017 Neural Optimizer Search with Reinforcement Learning
arxiv.org/abs/1709.0741
重要性:※ ※
简述:自动改造Optimizer,比传统Optimizer效果好
资源:全部训完需要100GPU*1天
搜索空间:Optimizer的各种因素的组合,如moving average, decay rate的变化方式等;
训练Trick: 用第1个epoch来选学习率,整个模型只训5个epoch(因为batch size128),所以能在10分钟训完一个模型
ICLR2017 workshop Searching for Activation Functions
arxiv.org/abs/1710.0594
重要性:※ ※
简述:搜激活函数,又水了一篇,推荐了一个x*sigmoid(x)的激活函数(称为swish),直接换激活函数就能涨点;
搜索空间:各种激活函数的组合
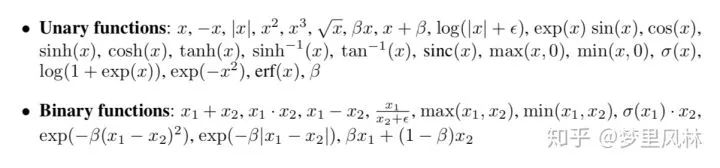
资源:实验主要是讲swish这个激活函数的效果的,所以没有提到资源占用情况,目测跟搜optimizer差不多;
ECCV2018 Progressive Neural Architecture Search(是李飞飞团队另外搞的一篇)
arxiv.org/abs/1712.0055
重要性:※ ※ ※
简介:训了一个eval模型,可以直接根据模型结构估计模型的准确率;在搜索cell的结构时,对于某个block_size结构的多种候选方案,分别扩展成block_size+1的方案,用eval模型选出topK个进行真正的训练,然后再对这K个进行扩展,重复上面的过程,因为只对topK做扩展,所以减少了搜索耗时;
搜索空间:cell的结构
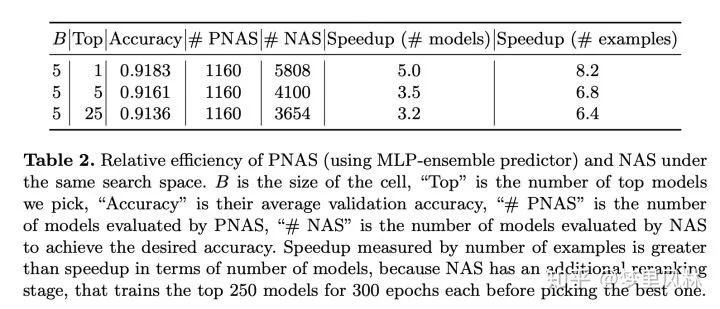
资源占用:在选择top1的条件下,搜索模型的速度是NASNet的五倍;也就是可以100个GPU,7天;
CIFAR实验:
ImageNet实验:
mobile模型用了50张P100搜,large模型用了100张P100搜,并且搜出来的模型效果都还不错,虽然没有说训练了多久:
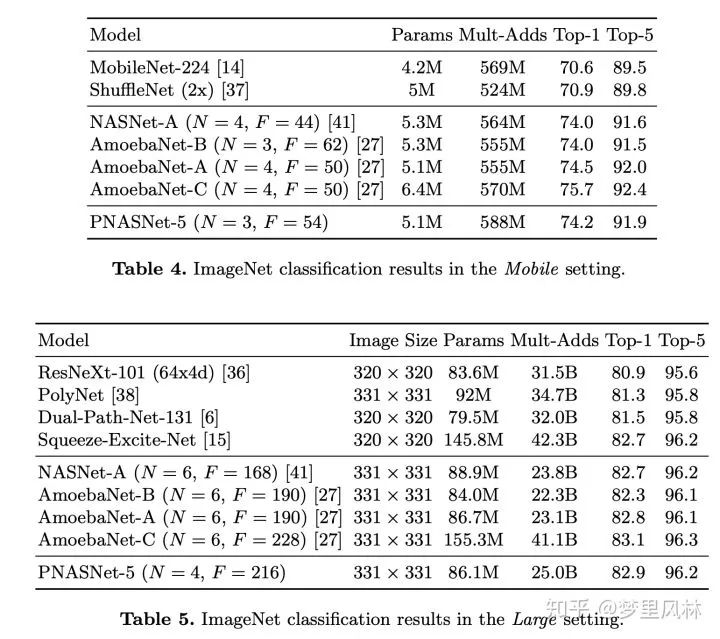
N是cell重复次数,为了保证不同N的相同的输出大小,中间的stride可能有区别,F是filter个数;
ICML2018: Efficient Neural Architecture Search via Parameter Sharing
arxiv.org/abs/1802.0326
重要性:※ ※ ※ ※ ※
简述:通过共享各个网络中共同单元的权重,来加快训练速度
搜索空间:用有向图表示各个单元的组合和连接,找到reward最高的子图;计算reward时,不同的模型用的是一开始train出来的同一套权重,不会专门重新优化,直接在验证集上跑一个batch计算reward,比较简单粗暴,搜出来其实不一定是最优的。
资源占用:
CIFAR上,一张卡,半天就能训练好;
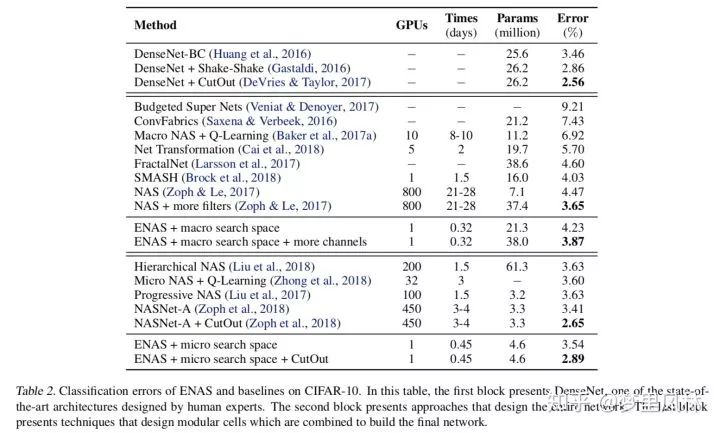
AAAI2019 Regularized Evolution for Image Classifier Architecture Search
arxiv.org/abs/1802.0154
重要性:※ ※ ※ ※
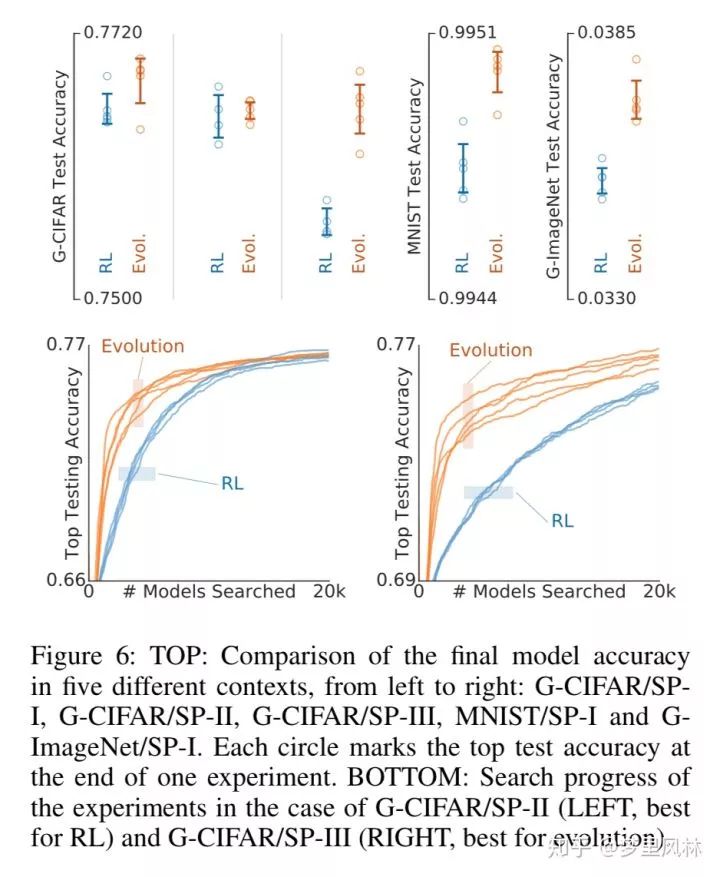
简介:第一个使用演化算法做NAS并达到SOTA的算法(之前的演化算法都没达到);改进点在于,为每个架构添加一个年龄属性,并倾向于搜索年轻的模型;提出了一个最简单的演化算法参数组,并通过这个参数组的变动来覆盖整个NAS搜索空间。效果比RL要好,做法比RL简单,但整体速度没有RL快(虽然claim的计算量更少,但是实现起来速度就是不如RL的方法)。
搜索空间:把搜索空间表示成有向图,节点是feature map,边是运算,边有类型和方向两个属性,方向决定了要连接哪些节点,类型决定了要做哪种运算。
资源:与基于RL的NASNet方法相同;
ECCV2018 NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
arxiv.org/abs/1804.0323
重要性:※ ※ ※ ※
简介:这其实更像一个压缩算法。以一个pretrain模型(其实是MobileNetV1和V2)为起点,采用移动设备的真实inference时间作为latency指标,同时权衡acc和延迟进行每一层的超参选择,从而达到移动端适配的效果。当然由于每次都去真实设备跑不太现实,难以并行,受限于设备数量,因此先跑了一下,整了一个每层参数数量和inference时间的对照表。
搜索空间:每层的filter数量N,以及要从原始模型里边挑选哪N个filter保留;
资源开销:没讲
效果:同样acc的模型,速度超越MobileNetV2。
CVPR2019 AutoAugment: Learning Augmentation Policies from Data
重要性:※ ※
arxiv.org/abs/1805.0950 (no published)
简介:将数据增强策略表示为各种子策略的组合进行搜索
资源:
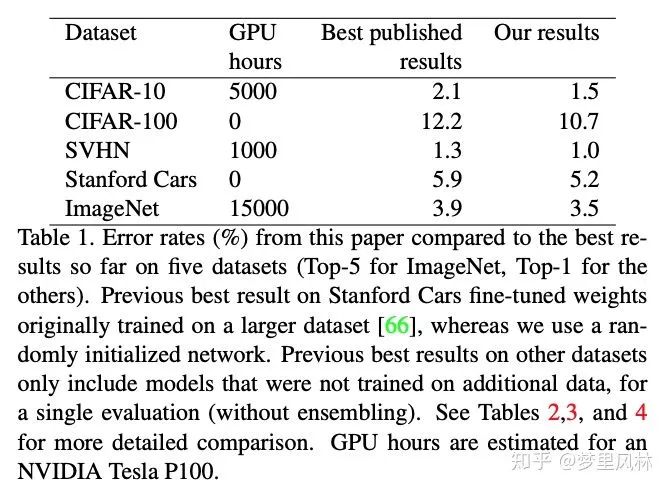
ICLR2019 DARTS: Differentiable Architecture Search
arxiv.org/abs/1806.0905
重要性:※ ※ ※ ※ ※
简介:将架构搜索表达为一个可微过程,用梯度下降来优化,搜索速度很快,效果很好,并且是开源的。
搜索空间:block cell结构,将cell表达为一个图,节点表示feature map,边表示operation,一个cell里有N=7个节点(含input和output),每个节点有两个input,一个是上一个节点的输出,一个是上上个节点的输出,每个节点对输入做|O|=8组运算,加权求和得到一个输出,权重用softmax归一化,整个cell的输出为所有中间节点的组合(b);架构搜索就是,优化这些操作的权重(c),最后每个节点保留K个(这里K取2)最大概率的操作(d)。如图:
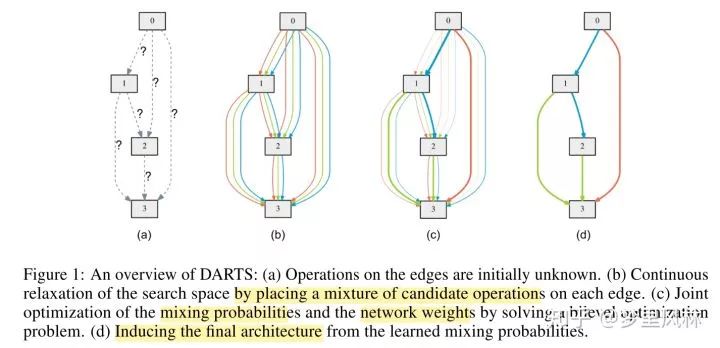
所以这是一个模型权重w和架构权重的α的双重优化问题,通过交替迭代优化来求解:

其中,架构权重的优化看的是val的loss,模型权重的优化看的是训练集的loss,架构权重优化时理论上应该是在最优的w上优化,但这样耗时太大,因此用一步SGD后的w-lr*grad(w)来代替最优w;论文中对这个梯度还做了一些运算上的优化;
这其实也是一种参数共享,不同的架构超参数在调整时共享了一份权重参数,避免每次都从头训练,之所以不同参数能够共享,是因为搜索时放在内存里的参数足够完备。这种共享比ENAS更高明,ENAS的参数共享太粗暴了,直接将上一个模型里的参数拿过来,不考虑架构上是否适合;而这里共享的参数正是此时最好的参数,因为超参的调整是连续的。
资源占用与效果(只看CNN):
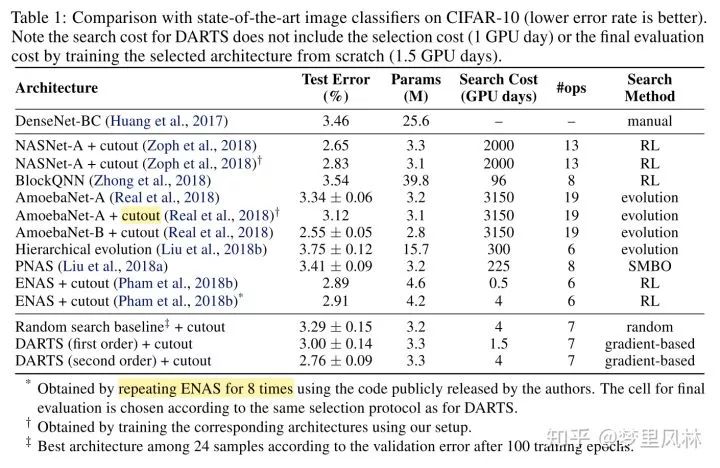
速度是略逊于ENAS的,但搜出来的模型参数数量更少,准确率更高。
把CIFAR上搜的这个模型在ImageNet上重新train,效果还不错,说明这个架构非常transferable
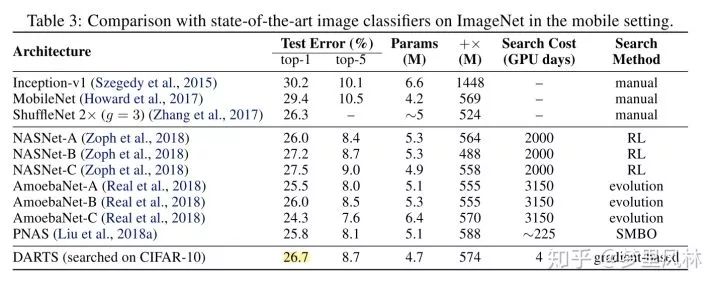
CVPR2019 MnasNet: Platform-Aware Neural Architecture Search for Mobile
arxiv.org/abs/1807.1162
重要性:※ ※ ※ ※ ※
简介:兼顾了模型轻量化目标的NAS,测推断速度时是直接在手机上测的,而非使用FLOPS等指标,暗含了模型实现时带来的延迟。(detailed knowledge of the platform and toolchain is not required.)
资源:由于CIFAR太小,模型容易拟合,模型的轻量化指标对模型的结构影响不大,因此只做了ImageNet的实验;在NASNet配置上搜索,占用64张TPUv2*4.5天,由于只是改了搜索目标,所以延时跟NASNet应该是差不多的
这是ImageNet上当时的benchmark
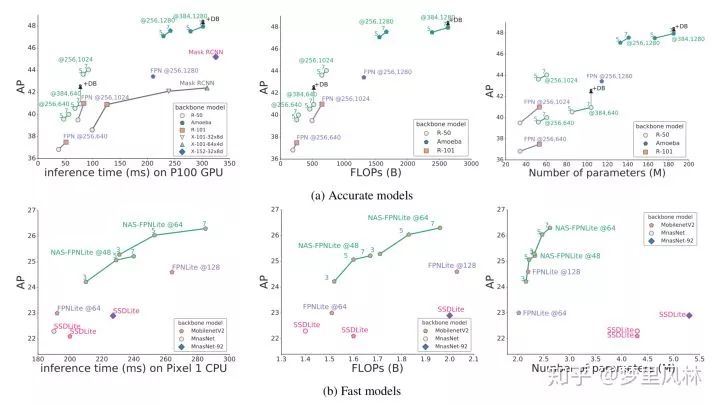
arxiv NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
arxiv.org/abs/1904.0739
重要性:※ ※ ※
简介:第一个正式把NAS魔爪伸向Object detection的paper,虽然MNasNet也做了coco的实验,但那只是分类网络的试水,没有改detection的结构,这篇focus在backbone提取不同layer的feature后,用FPN进行跨尺度融合。
搜索空间:跨尺度连接;
资源:别问,问就是TPU
效果:两个版本,一个准一个快;
ICML2019 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
arxiv.org/abs/1905.1194
重要性:※
简介:claim了这样一个思想:平衡好depth/width/resolution的关系可以有更好的效果(感觉是废话),并在mobilenet和resnet上做实验验证。然后用NAS同时以acc和flops搜了一个baseline网络出来,做了depth/width/resolution的平衡,然后就得到了一组比较好的模型EfficientNets。对NAS这个领域没啥贡献,暂时不细看。
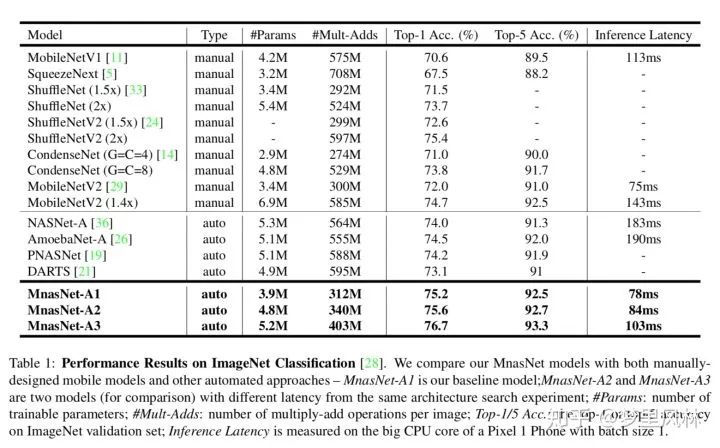
arxiv Searching for MobileNetV3
arxiv.org/abs/1905.0224
重要性:※ ※
简介:
结合NAS和人工网络设计来实现MobileNetV3,以前都是纯机器搜;
release准确和轻量两个版本。
在MNas基础上,改了一下不同目标的权重,搜了一下CNN block,再用NetAdapt搜了每一层的filter大小;
基于搜出来的结构人工优化,包括:把最后的1x1卷积移到global average pooling后面,并因为global average pooling这个操作实现了降维,所以可以移除一块3x3卷积;在网络首层,减少了filter数量并使用了不同的非线性激活;用Relu6(x+3)/6代替sigmoid以减少计算量;
资源开销:4x4个TPU容器
效果:在相同acc下,速度比mobilenetv2略快
Learning Data Augmentation Strategies for Object Detection
arxiv.org/abs/1906.1117
重要性:※ ※
code: https://github.com/tensorflow/tpu/tree/master/models/official/detection
简介:专为Object detection搜各种augmentation的组合,效果很强,idea比较简单。
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~






