更快更强!谷歌提出SWideRNet:全景分割新标杆!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

极市导读
本文是DeepLab系列作者“Liang-Chieh Chen”大神在全景分割领域的又一力作。它在Wide-ResNet的基础上引入SE与"Switchable Atrous Convolution,SAC"两种改进,嵌入到Panoptic-DeepLab框架中并在全景分割领域取得了SOTA性能(在更快、更大模型配置方面均取得了SOTA指标)。

paper: https://arxiv.org/abs/2011.11675
Abstract
Wide-ResNet是一种浅而宽的残差网络(通过堆叠少量的宽残差模块构建),并在多个稠密预测任务上证实了其优异性能。然而,自从Wide-ResNet提取之日鲜少改进。
研究者重新反思了其在全景分割(将语义分割、实例分割统一的一种新任务)任务上的设计,提出来一个基准模块:将SE模块与SAC集成入Wide-ResNet。所提网络的容量可以通过调整宽度、深度得到一类SWideRNets(Scaling Wide Residual Networks)。
作者通过实验证实:这样一种通过网格搜索的简单扩展机制可以使其在全景分割任务上取得SOTA性能,在更快模型配置与更强模型配置下均具有更好的性能。所提方法的性能-推理速度与其他SOTA方法的对比见下图。
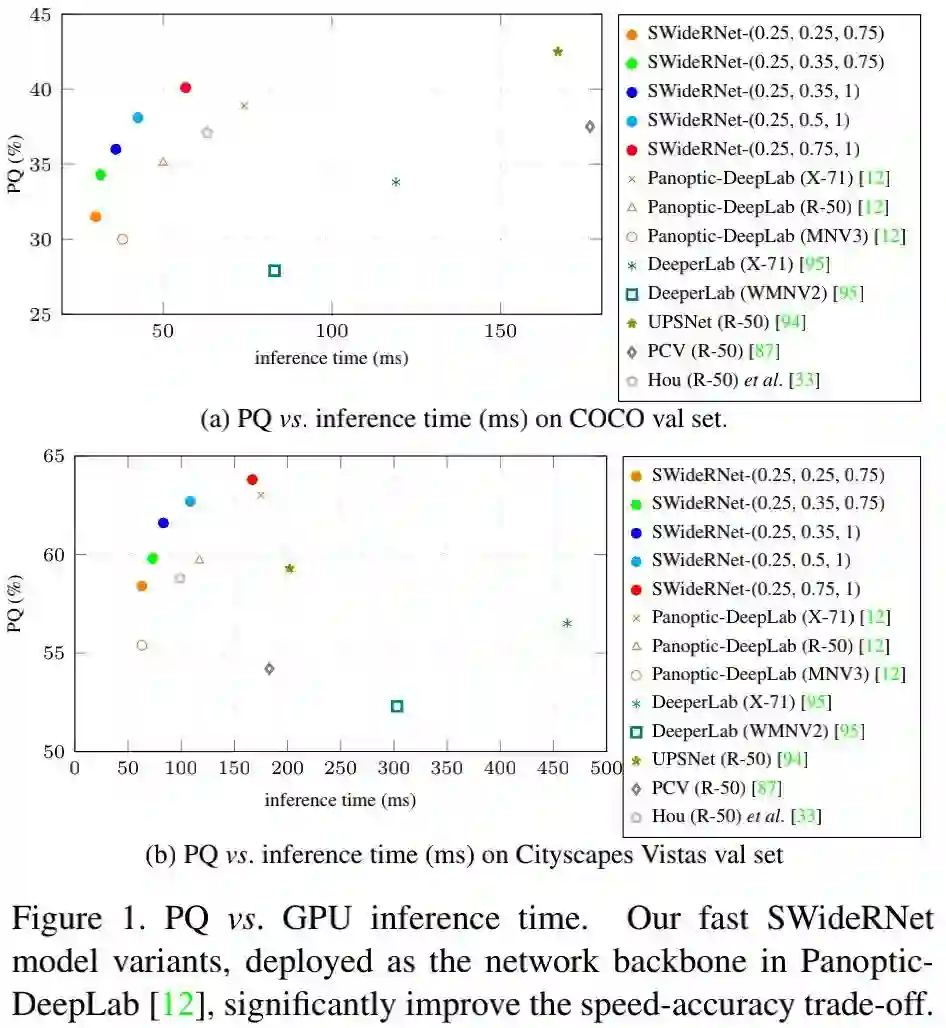
该文的主要贡献在于:找到了几个具有取得了SOTA速度-精度均衡的SWideRNet骨干网络,同时所找到的SWideRNet骨干网络进一步推动了全景分割任务的进展。
Method
接下来,我们将先介绍一下如何通过集成SE与SAC有效的扩展基准模型的容量;然后再来介绍一下如何通过调整所得模型的缩放因子构建更快与更强的模型。
The SWideRNet family
基准模型Wide-ResNet已证实了其在图像分类、目标检测以及语义分割方面的优秀性能。其中Wide-ResNet38已成为Cityscape语义分割、实例分割方面的优异骨干网络。Panoptic-DeepLab中采用的Wide-ResNet41取得优于WR38的性能与速度,它进行了两个方面的改进:(1)移除最后的残差模块;(2)重复倒数第二个残差模块更多次。
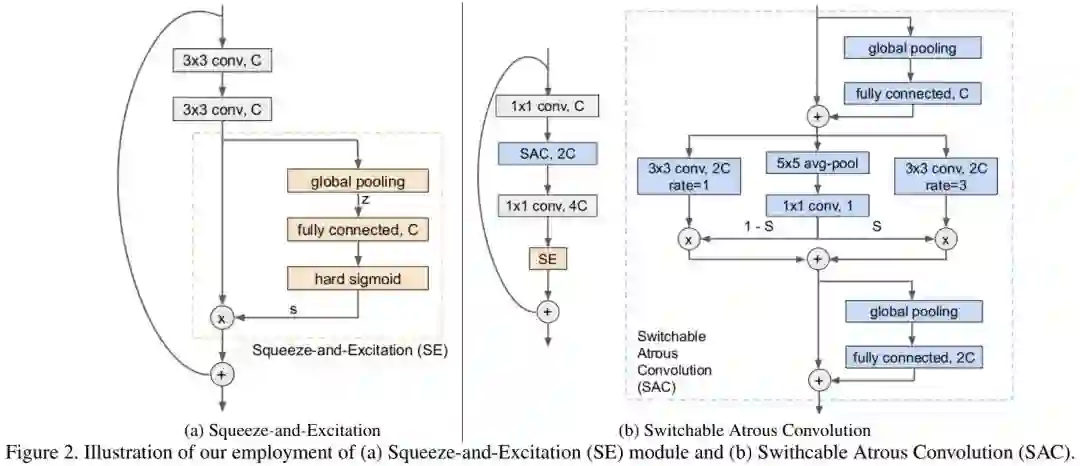
在WR41的基础上,作者进一步引入了SE模块(注:这里的SE仅包含一个全连接层)与SAC构建了该文的基准模型,见上图。具体来说,SE中的通道注意力图计算方式如下:
其中,z表示全局均值池化特征。参考MobileNetV3,这里采用了HardSigmoid激活函数 。
SAC操作旨在集成不同扩张比例的特征,具体的讲,我们采用 表示扩张因子为r的卷积,SAC则定义如下:
其中 表示开关函数,它由 GAP与 卷积构成。延续了DetectoRS的配置,作者同样在SAC主操作前与后添加了两个轻量型全局上下文模块(GAP+FC构成),同时要注意到:SAC中不涉及deform-conv。
类似Wide-ResNet、EfficientNet、MobileNet,作者采用尺度因子 对基准网络进行缩放并提升基准网络的容量,其中 用于缩放前两个阶段的通道数, 用于缩放其他阶段的通道数与层数。下图给出了本文所提SWideRNet的配置信息,可以看到骨干网络的层数为 ,需要额外注意的是这里不包含了SE与SAC的额外操作。
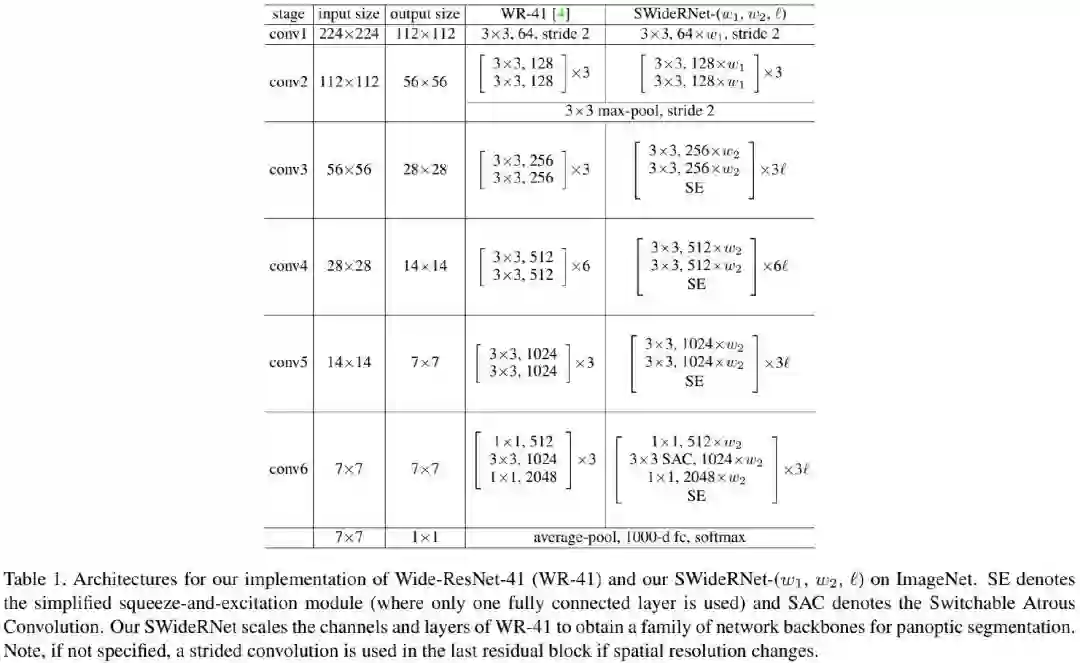
Exploring SWideRNet
从上面的配置可以看到:SWideRNet-( )定义了大量的网络架构,可以得到不同的SWideRNet架构用于不同的任务与应用。在该文中,作者采用SWideRNet用于全景分割的两个场景:(1) 端侧全景分割,旨在设计更快的SWideRNet以获得更好的速度(GPU推理)-精度均衡;(2) 云端/服务器端全景分割,旨在设计更高的精度而不考虑模型参数、速度等。
Grid Search SWideRNet-( )的搜索空间是离散的,这使得我们可以采用最简单而有效的网格搜索方法。
Fast Model Regime 作者通过缩小网络的容量在搜索空间 内约束SWideRNet-( )并获得更快的推理速度。此时搜索空间的定义如下,它包含45个候选架构
Strong Model Regime 作者通过在搜索空间 内放大网络提升容量并获得更好的预测精度,该搜索空间总计包含21个候选网络,但考虑到GPU/TPU内存问题,作者仅仅对其中11个候选进行了实验。
Experiments
基于所提SWideRNet-( ),作者在多个数据集(COCO,Cityscapes, Mapillary Vistas, ADE20K等)上进行了实验分析。在评价方面,作者选用了mIoUP, AP, PQ等评价语义分割、实例分割以及全景分割的性能。
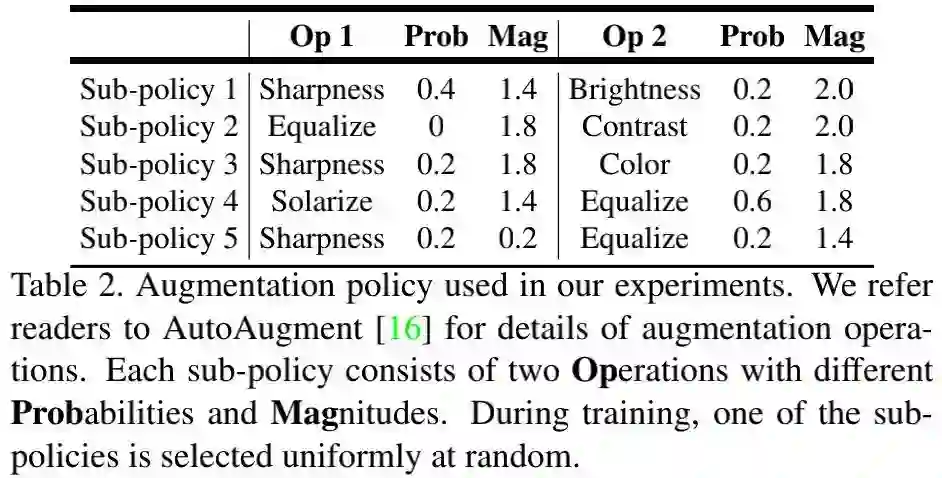
在网络结构方面,作者选用Panoptic-DeepLab作为骨干并延续了其实验配置,采用Tensorflow实现,在32TPU上训练,学习率衰减方式为"poly",初始学习率为0.0001,数据增广选用了随机尺度曾广,优化器为Adam无weight decay。COCO,Cityscapes,Mapillary Vistas以及ADE20K的训练迭代次数分别为500K,60K,300K,180K。损失函数方面与Panoptic-DeepLab相同。在大模型训练方面,作者选用了AutoAugment曾广方式,见下表。
Ablation Studies
作者在COCO全景分割验证集上进行了消融研究。
Design Choices 作者在Panoptic-DeepLab的基础上采用不同的骨干架构,见下表,对比了引入不同模块时的性能对比。可以看到:(1)SAC可以取得1.2%的性能提升;(2)SE可以取得额外的0.6%性能提升;(3)在decoder部分采用Sep-Conv可以取得更快的推理速度,精度仅下降0.2%。
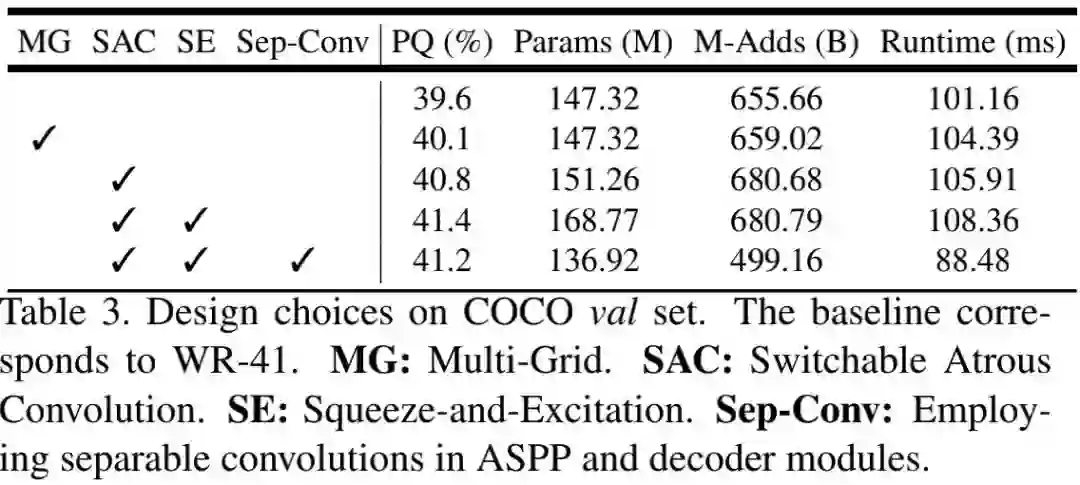
Training Tricks 在训练过程中,采用drop-path与AutoAugment可以分别提升0.2%和0.3%PQ指标。
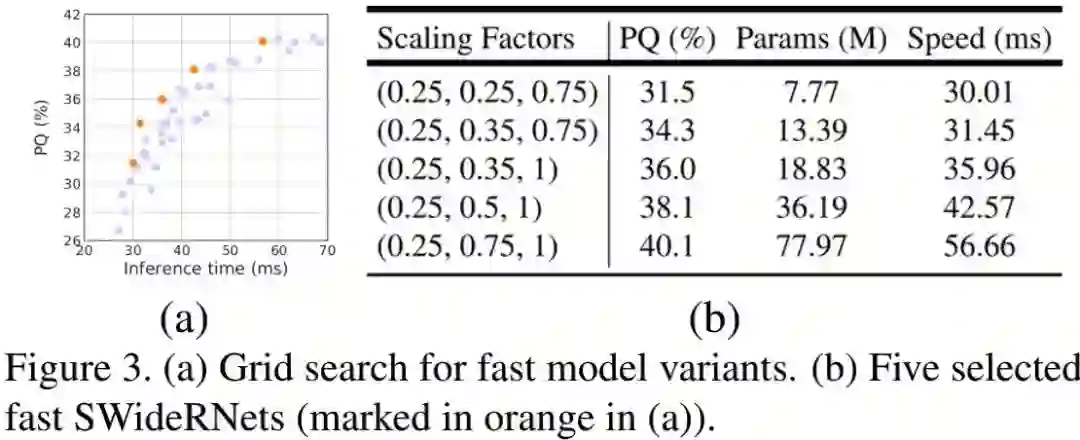
Fast Model Regime 作者还对更快的模型进行试验分析,结果见下图。下图a给出了PQ与GPU推理耗时的关系图,下图b给出了不同缩放因子下的模型性能、参数量以及推理速度的对比表。可以看到:所有的快速模型的配置参数 均为0.25,这也就意味着conv1与conv2是速度瓶颈。
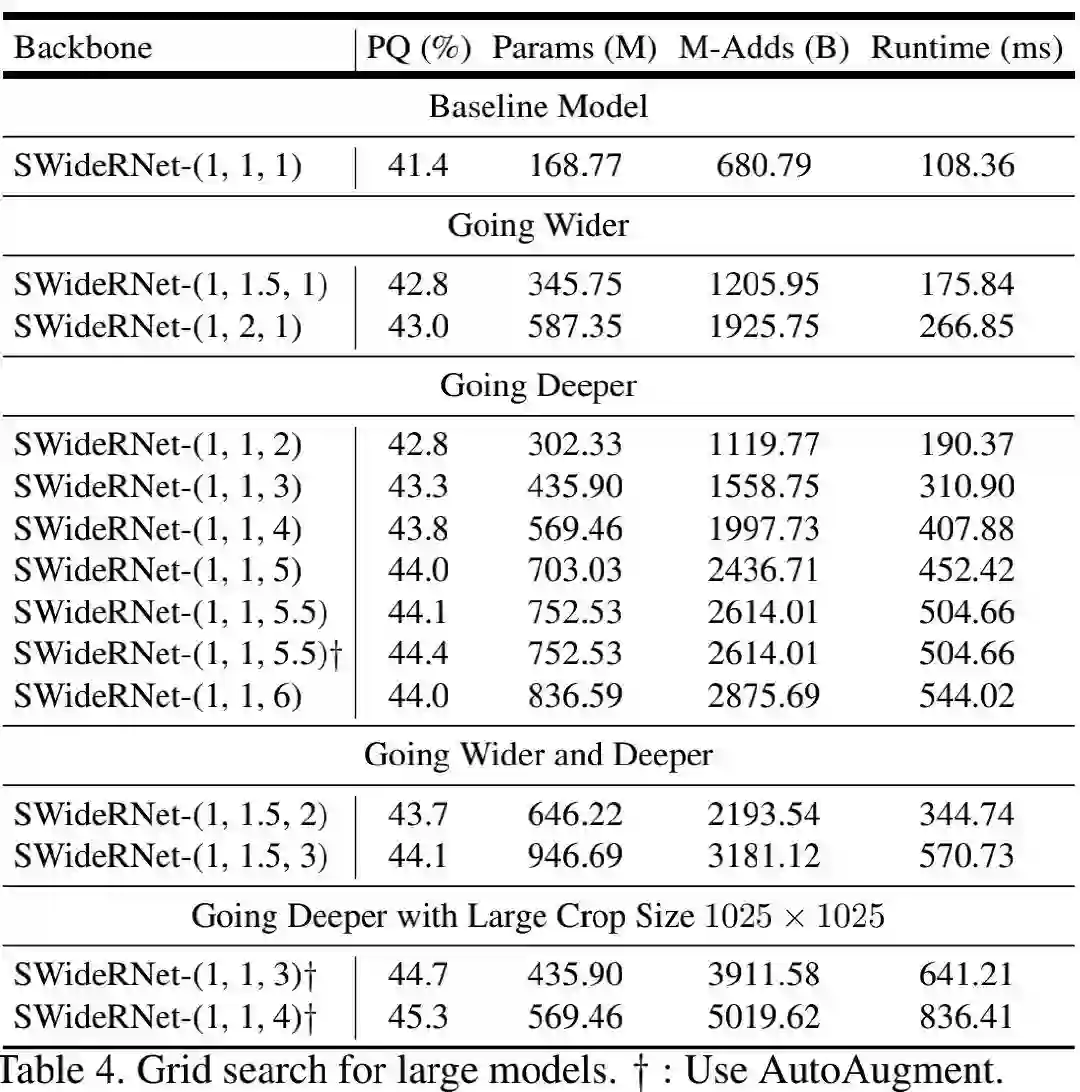
Strong Model Regime 作者对更高精度的模型进行了实验分析,结果见下表。从中可以看到:提升深度比提升宽度、同时提升宽度和提升两种方式更有效。这也就意味着:Wide-ResNet对于当前任务而言已经够宽。
Fast Model Regime
下表给出了作者所得到的的5个快速SWideRNet模型与其他SOTA模型在COCO与Cityscapes上的性能、速度以及计算量方面的对比。注:表中的推理速度是在Tesla V100-SXM2GPU上以batch=1进行测试。
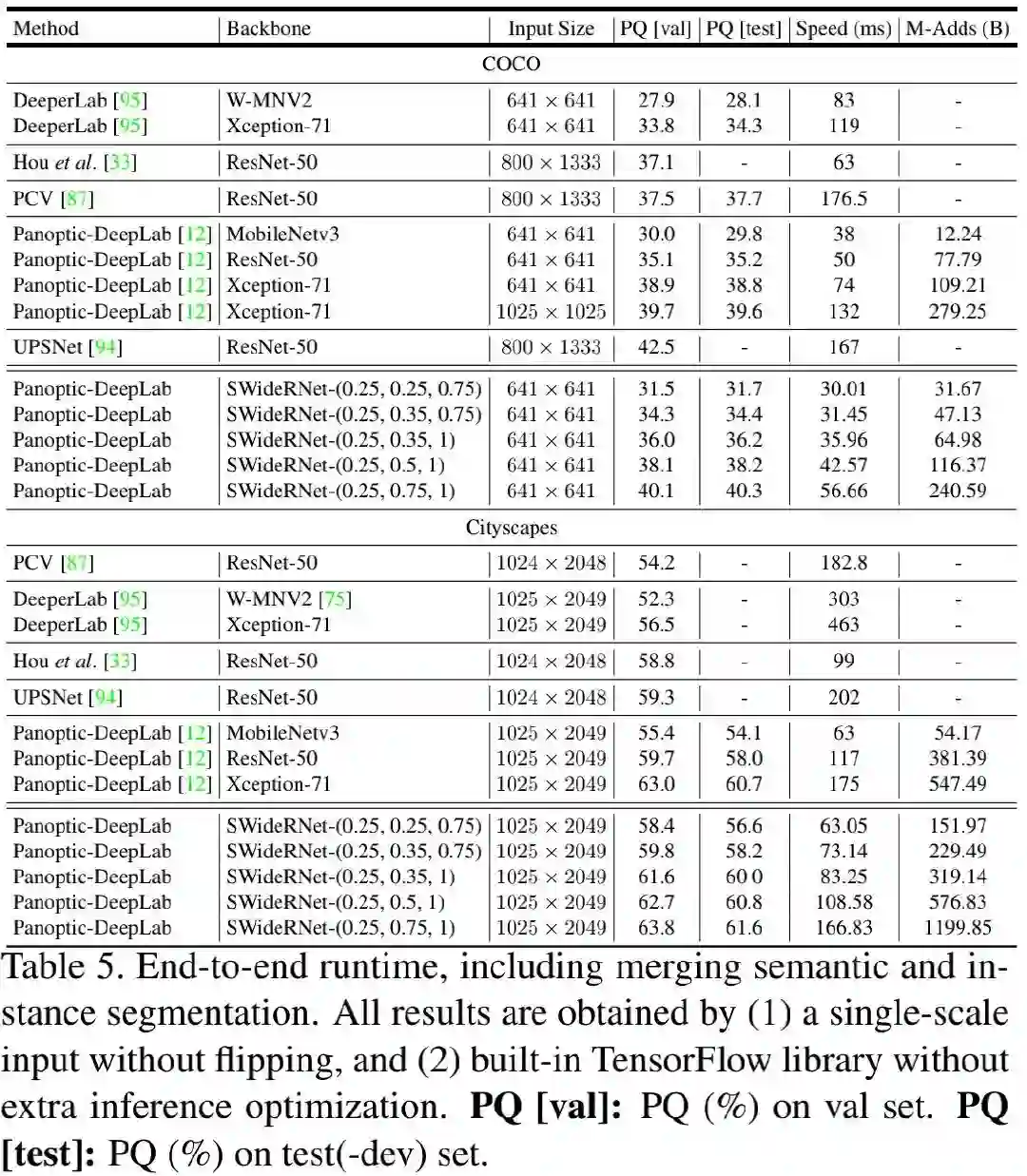
前面的Fig1给出了速度-精度的散点图,正如Fig1与Table5所示,该文所提方案取得了最佳的速度-精度均衡。更具体的来讲,
-
在COCO数据集上,相比MobileNetV3作为骨干网络,SWideRNet-(0.25,0.35,1)在val与test集上分别取得了6%和6.4%的性能提升,同时具有相近的推理速度。 -
在COCO数据集上,相比ResNet50作为骨干网络,SWideRNet-(0.25,0.5,1)取得了3%的性能提升,同时具有更快的推理速度。 -
在COCO数据集上,SWideRNet-(0.25,0.75,1)取得了与Xception71相似的性能,但推理速度快了2.3倍。 -
在Cityscapes数据集上,SWideRNet-(0.25,0.25,0.75)取得了比MobileNetV3高3%(val)和2.5%(test)的PQ,且具有相近的推理速度。 -
在Cityscapes数据集上,SWideRNet-(0.25,0.5,1)取得了比ResNet50高3%(val)和2.8%(test)的PQ。 -
在COCO数据集上,SWideRNet-(0.25,0.75,1)取得了比Xception71更高更快的的性能。
Strong Model Regime
在更强模型方面,作者采用”加深“策略,不同的数据及上的指标见下面的分析,分别从不同的数据集方面进行针对性的分析。
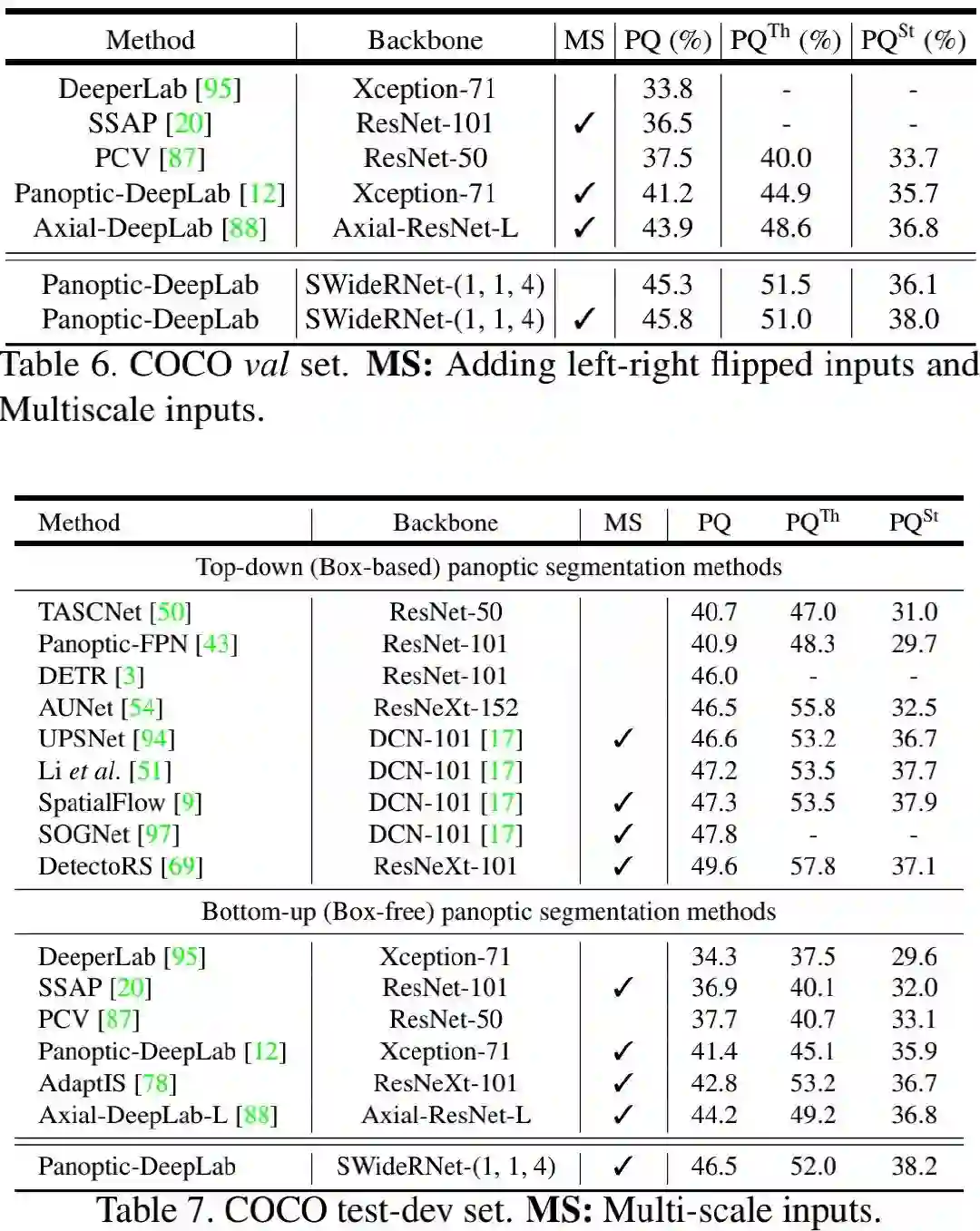
COCO 下面的Table6与Table7给出了val与test数据集上的结果。可以看到:(1) 在无多尺度推理下,SWideRNet-(1,1,4)已经取得了优于Axial-DeepLab的性能;(2) SWideRNet-(1,1,4)在test集上取得了46.5%的PQ指标,以2.3%指标优于Axial-DeepLab-L。
Cityscapes
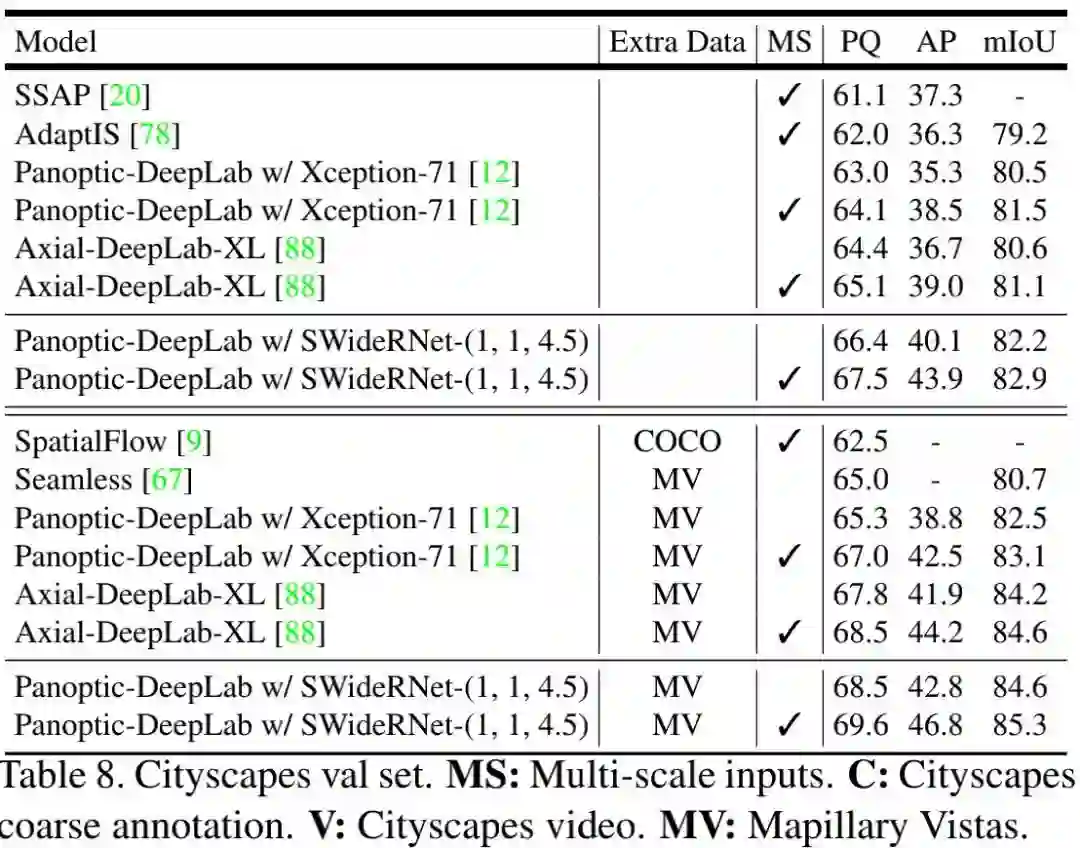
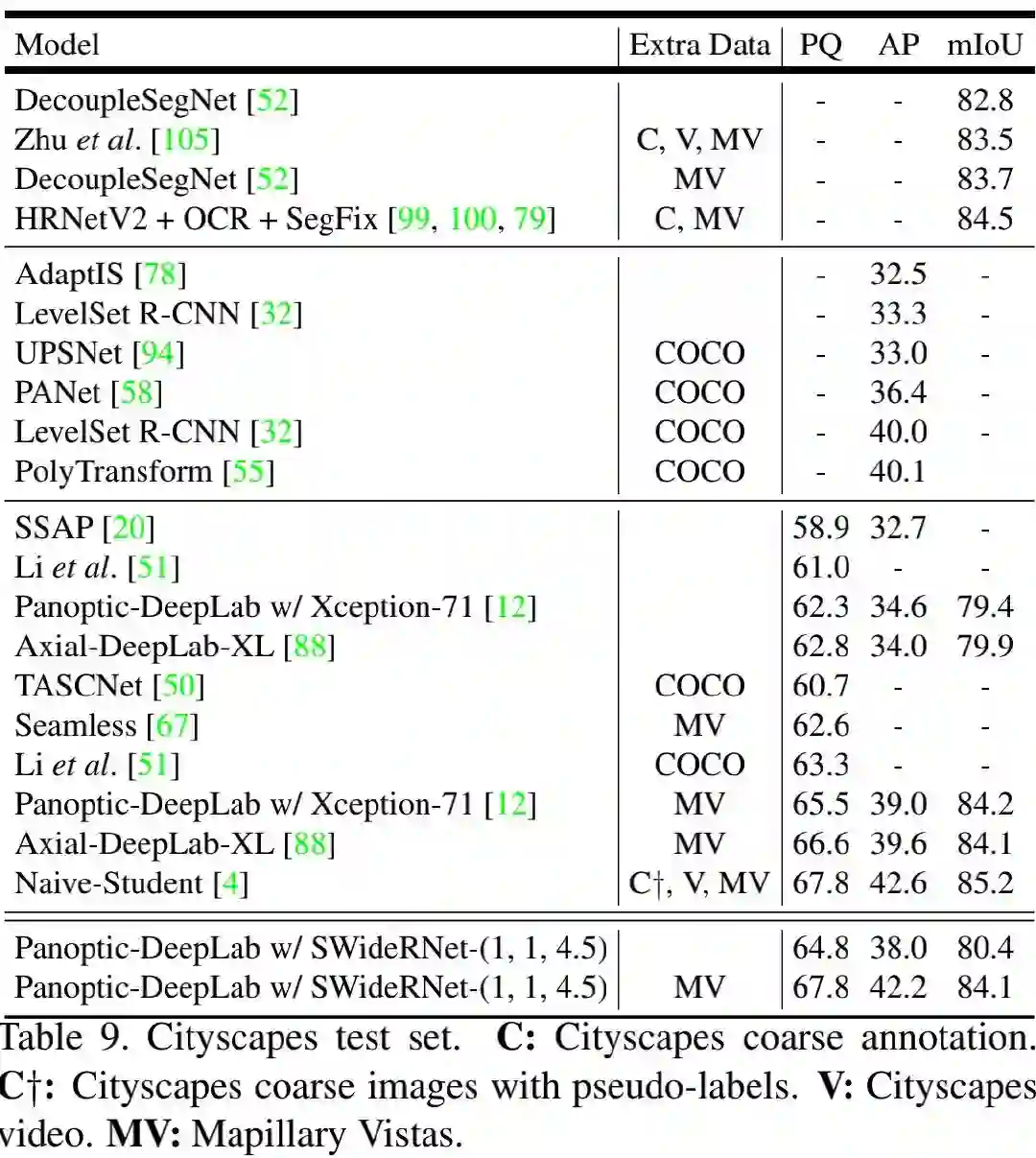
下表Table8与Table9给出了Cityscapes的val与test上的性能对比。从中可以看到:(1) 在多尺度推理下,SWideRNet-(1,1,4.5)取得了比Axial-DeepLab-XL高2.4%的指标(仅Cityscape 细粒度标注)和1.1%的指标(额外Mapillary Vistas预训练);(2) ** 当仅仅采用细粒度标注时,所提方案以2%PQ和4%AP指标优于Axial-DeepLab-XL;当采用额外数据时,所提方法取得了67.8%PQ、42.2%AP以及84.1%mIoU指标,分别以1.2%PQ,2.6%AP优于Axial-DeepLab-XL**,并得到了一个新的SOTA指标。
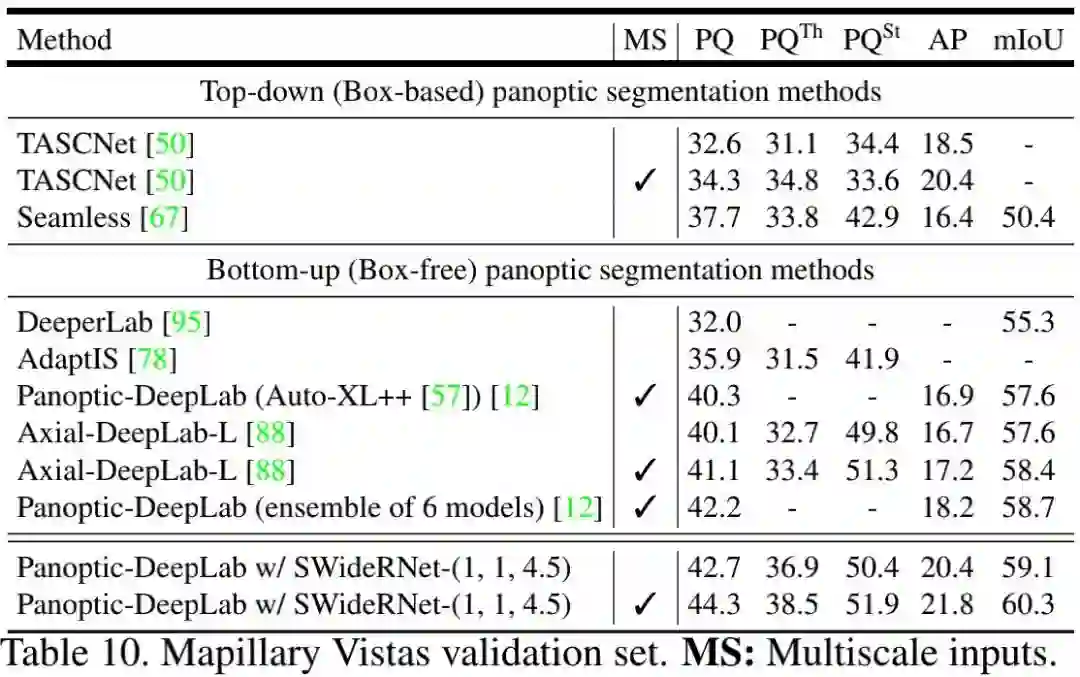
Mapillary Vistas 下表给出所提方法在Mapillary Vistas验证集上的结果。可以看到:在多尺度推理下,SWideRNet-(1,1,4.5)取得了44.3%PQ、21.8%AP以及60.3%mIoU指标,分别以3.2%PQ、4.6%AP、1.9%mIoU指标优于Axial-DeepLab-L。需要特别说明的是:所提单模型甚至取得了优于6个Panoptic-DeepLab集成的结果。
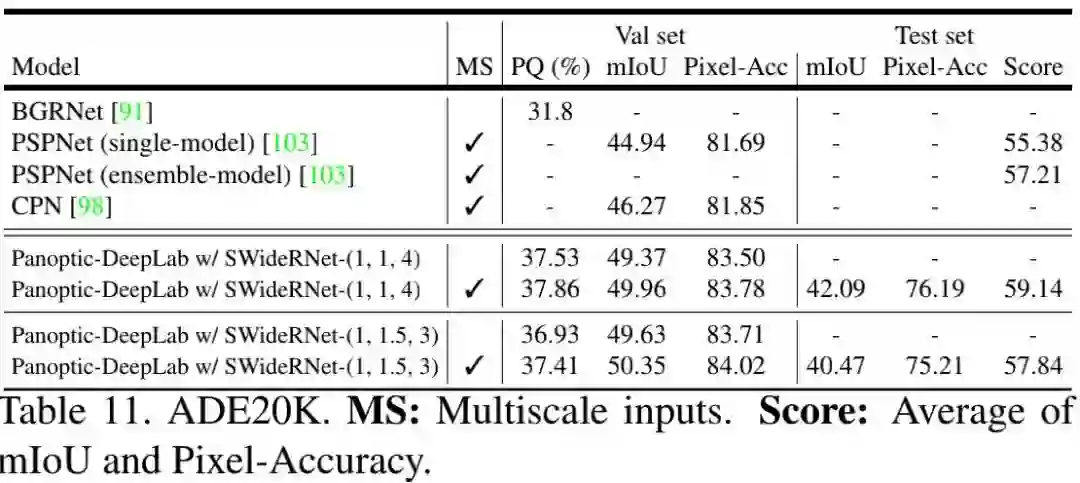
ADE20K 下表给出了所提方法在ADE20K数据集上的结果。从中可以看到:(1) 在验证集上,SWideRNet-(1,1,4)以6%PQ指标优于BGRNet,并取得了49.96%mIoU和83.78%PA指标;(2)在测试集上,单模型取得了59.14%的得分,以1.9%优于PSPNet的集成版,并得到了一个新的SOTA指标。
最后,我们再附上所提方法在不同数据集上的预测效果示意图。

全文到此结束,对此感兴趣的同学建议去查看一下原文。
上述论文PDF下载
后台回复:SWideRNet,即可下载上述论文
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集2000人!涵盖语义、实例、全景、医学图像分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!

