近年来,基于强化学习的计算工具在包括图像分类和机器人对象操作在内的众多任务中取得了显著成果。与此同时,计算机科学家也一直在训练强化学习模型来玩特定的人类游戏和电子游戏。
《Minecraft》是全球知名度最高的开放世界游戏。小朋友只需观看十分钟的教学视频,就能学会在游戏中寻找稀有的钻石,但这却是 AI 此前无法企及的高度。
![]()
为了让 AI 也能实现类似的能力,自 2019 年至今,机器学习顶会 NeurIPS 已联合 CMU、微软、DeepMind、OpenAI 等机构,组织了三届以强化学习为主题的竞赛 MineRL Diamond Competition。该竞赛旨在促进算法的开发,使算法可以有效地利用人类演示来大幅减少解决复杂、分层和稀疏环境所需的样本数量。
MineRL 2021 共有 59 支团队、近 500 名选手参赛,其中不乏世界顶级学府和研究机构的科研强队。赛事要参赛团队在 4 天时间内用一台计算机训练 AI 找到钻石。
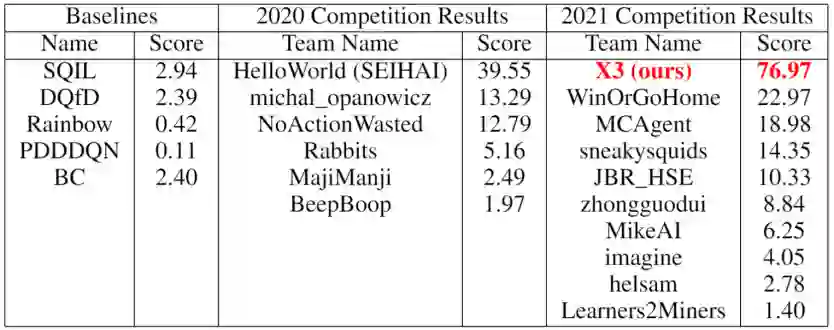
在刚刚开幕的 Neurips 2021 大会上,第三届 MineRL 竞赛成绩正式发布,腾讯 AI Lab 的「绝悟」以 76.970 分的绝对优势夺冠,让 AI 的「钻石之梦」踏进了一大步。
![]()
MineRL 2021 完整榜单:https://www.aicrowd.com/challenges/neurips-2021-minerl-diamond-competition/leaderboards
在 MineRL 竞赛中,与每个真人玩家一样,AI 会从《我的世界》游戏里一个随机世界的随机位置出生,从没有任何工具的初始状态开始,完成一系列任务,最终找到钻石。
这个任务听上去清晰明了,却难倒了无数挑战者。官方基于成熟算法的 baseline 只能获得 2 分——让 AI 徒手撸树并造出第一块木板,这离获得钻石还有非常远的距离。
首先,是极度多样的环境。
不同于绝悟先前学习的游戏,MineCraft 最大的难度就在于 3D 的开放世界。游戏没有固定的地图,完全靠随机种子生成;树木、铁矿、钻石等资源的刷新位置也没有固定的规律。因此,AI 见到的每一局游戏都是崭新的。它不能死记硬背,而是要从一张张 64×64 像素的「高糊截图」中真正理解这个无限开放的世界。
![]()
MineCraft 游戏截图,分辨率 64×64。
其次,是长决策序列与复杂的技能。
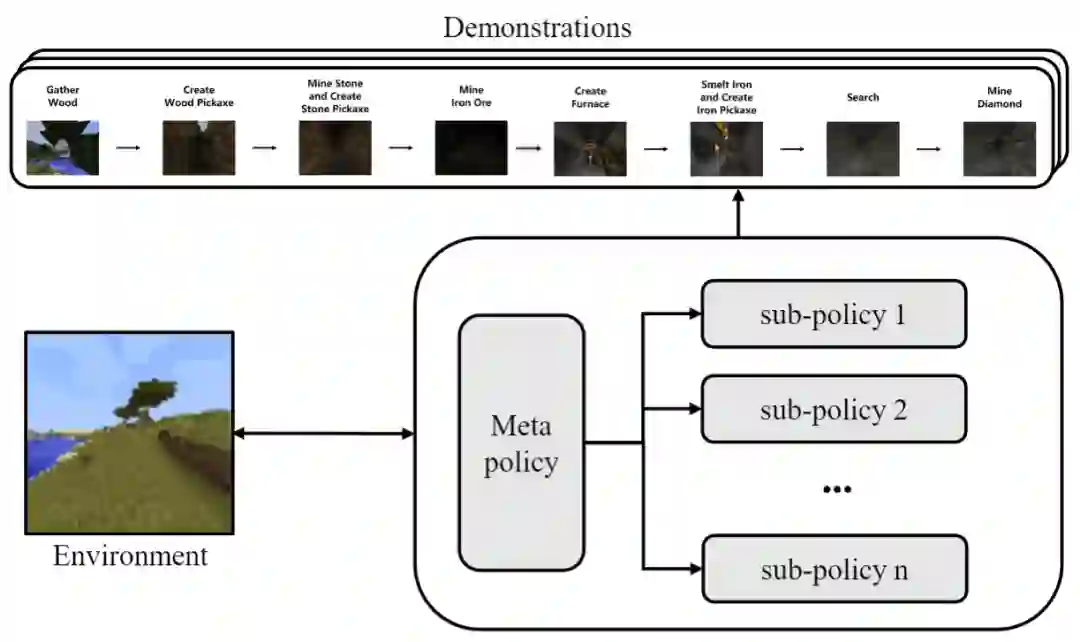
为了在 15 分钟的游戏时间内拿到钻石,AI 需要理清最高效的行动顺序,并抓紧时间掌握多个技能。从木头到钻石,一共要经过 12 道流程。
![]()
最后,是由高自由度玩法带来的海量策略偏好。
赛事主办方收集了玩家的近 6000 万个动作样本,提供了约 1000 小时的行为记录,供 AI 学习模仿。但这些样本来自不同玩家,策略差异极大。比如为了获取钻石,有人喜欢矿洞探险,有人选择向下掘地三尺...... 从复杂多样的数据中学习、并最终形成自己的一套策略,这对于 AI 无疑是极大的挑战。
除了以上难点,主办方还制定了严苛的规则,给 AI 的挑战又增加了一些难度。
为了将目光聚焦于算法本身,主办方禁止参赛者编写规则、也禁止 AI 利用任何游戏知识,并且不允许玩家自定义奖励函数,这也让从零开始完全采用强化学习的方式来训练 MineCraft AI 相当困难。
![]()
算力方面同样做了严格的规则限制。MineRL 比赛的初衷就是促进样本高效 (sample-efficient) 游戏 AI 算法的发展。目前流行的强化学习算法一般需要多达成百上千万次的试错来寻找最优流程,耗费大量的时间和计算资源。而纯靠人类数据的模仿学习算法虽然更快,但性能上往往不尽如人意。如何将两种方法的优势结合、又快又好地完成任务,也是主办方的另一个目标所在。
因此,赛事不允许使用预训练模型,只允许与环境最多交互八百万次,每个参赛队伍只能使用 6 核 CPU 与半张 NVIDIA K80 显卡训练 4 天——这个配置几乎是所有高校实验室与个人研究者都可以负担的。
近年,越来越多 AI 研究团队将目光投向电子游戏,利用高度复杂、高度定制化的游戏场景,为 AI 提供实验场景和成长驱动力。业界期望通过越来越复杂的游戏训练,AI 最终能够解决现实生活中的问题。
「绝悟」是腾讯 AI Lab 研发的 AI,2019 年达到王者荣耀职业电竞水平,于 2020 年获得 Kaggle 足球 AI 竞赛冠军,2021 年掌握王者荣耀全英雄,同时攻克 FPS、RTS 等类型游戏,并将其能力应用于游戏研发及运营环节。这次化身 MineCraft「矿工」,展现了「绝悟」在充满不确定性的复杂环境中游刃有余的能力。
![]()
论文地址:https://arxiv.org/abs/2112.04907
随着棋牌游戏 AI 绝艺从围棋棋盘走向象棋、麻将,策略协作型 AI 「绝悟」从 MOBA 走向 FPS、RTS、再到如今的 3D 开放世界 MineCraft,它们迈向全新挑战的每一步,都让 AI 离解决现实问题、科技向善的大目标更近了一步。随着虚实集成世界逐步变成现实,这些研究的经验、方法与结论,将在真实世界创造更大的实用价值。
具体而言,来自腾讯 AI Lab 的研究人员通过分层强化学习(HRL)、表示学习(Representation learning)、自模仿学习(Self-imitation learning)、集成行为克隆(Ensemble Behavior Cloning)等四项关键技术,实现了优于其他竞争队伍的效果。
Hierarchical Reinforcement Learning(HRL)
首先,为了尽可能提高样本利用率与训练效率,智能体的框架采用了分层强化学习 (Hierarchical RL)。由于数据处理阶段禁止引入 MineCraft 游戏的先验知识,研究人员实现了一套自动的数据切分算法,先使用 reward 与 entropy 切分子阶段,再利用统计数据确定各阶段边界。在游戏推进中,上层控制器会实时选定一个子策略,由该策略与环境交互。
![]()
数据分析表明,上层控制器的预测准确率可以达到 99.95%,也就是说,AI 从人类数据中学到了一套几乎永不出错的宏观策略,每时每刻都清晰地知道自己下一步的正确动向。
Action-aware Representation Learning
在特征设计上,MineCraft 游戏遇到的最大挑战在于如何表征复杂且多样的 3D 开放式地图。
首先被选中的是近年来热门的表示学习方法 (representation learning)。但研究人员很快发现,已有方法只适用于 2D 场景,在 MineCraft 游戏环境里效果很差。于是他们设计了一种「基于动作感知」的新颖算法,用来捕捉每个动作对环境产生的影响,形成注意力机制。这种方法可以显著减小状态空间,提升学习效率。
实验表明,这种算法可以显著提升智能体获得资源的能力与效率。
![]()
左图执行「攻击」动作后会变为右图,此时模型只会关注红框区域。
![]()
不同动作的可视化结果,AI 学会了关注当前图像中不确定的区域。
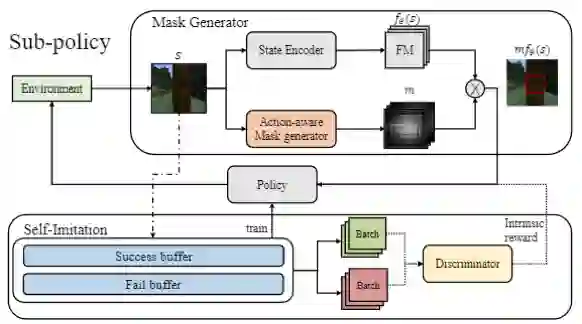
Discriminator-based Self-imitation Learning (DSIL)
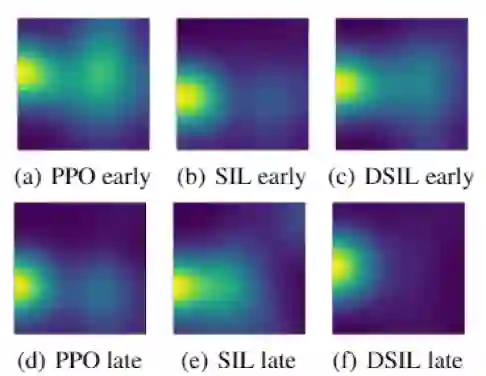
随着游戏进程推进,智能体与人类的策略出现了很大的分歧。此时,人类数据已经很难用于指导 AI。因此,如何从极有限的交互次数中学到一个优秀的策略成为了新的难题。为此,绝悟使用了自模仿学习 (self-imitation learning) 的思想。通过基于鉴别器的自模仿算法,智能体可以从自身过往的成功与失败中获得经验与教训,并在察觉到当前状况不妙的时候,主动往更好的方向修正。
对比实验证明,在加入自模仿策略后,智能体探索到的行为更加一致,也可以显著降低进入危险区域的概率。
![]()
相比于 PPO 和 SIL,DSIL 可以更高效地捕捉到历史的成功策略,从而降低不必要的探索。
![]()
Ensemble Behavior Cloning with Consistency Filtering
对于合成物品等需要长链条的动作序列,研究人员也做了细致的优化。通过动作序列一致性过滤 (consistency filtering) 与基于投票的集成学习 (ensemble learning),模型在合成物品阶段的成功率从 35% 提升到 96%,一举将最薄弱的链条扭转为了最稳定的制胜点。
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
完成对车辆车牌的检测和识别,并对行人以及车辆的品牌,颜色,种类进行检测。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com