干货 | 从手工提取特征到深度学习的三种图像检索方法

AI 科技评论按:本文为专栏作者兔子老大为 AI 科技评论撰写的独家稿件,未经许可不得转载。
前言
图片检索是计算机视觉,数字图像处理等领域常见的话题,在我学习相关知识的过程中,图像检索算是我第一个学习的 demo,该过程都记录在 利用python进行识别相似图片(一) 和 利用python进行识别相似图片(二) 两篇文章,分别记录了直方图匹配,phash/average hash/dhash 三种基于哈希的方法。
图片检索的的大体框架大致可以分成两步,抽取某种特征,计算相似度。其中像上述提及的几种方法,都是对应抽取特征这一步,而计算相似度,则常使用欧式距离/汉明距离/Triplet 等方法。显然的,上述方法都属于人工设计的方法来进行抽取特征,很自然的就想到使用当今很火热的深度学习来代替人工的设计的方法,所以这篇文章主要介绍的就是基于深度学习的图片检索。
本文主要介绍的文章有以下几篇:
Deep Learning of Binary Hash Codes for Fast Image Retrieval -- CVPR WORKSHOP 2015
DEEP SUPERVISED HASHING FOR FAST IMAGE RETRIEVAL -- CVPR 2016
Feature Learning based Deep Supervised Hashing with Pairwise Labels -- IJCAI 2016
提及到使用深度学习提取图像特征,业界一般认为现有的图像模型中,前面的卷积层负责提取相关特征,最后的全连接层或者 globel pooling 负责分类,因此一般的做法是直接取前几层卷积的输出,然后再计算相似度。
但这样涉及到一个问题,首先一个是数据精度问题,因为直接取特征输出多是浮点数,且维度高,这会导致储存这些图像的特征值会耗费大量空间,第二个因为纬度高,所以用欧式距离这种方式计算相似度,可能会触发维度灾难,令使用欧式距离代表相似度这种方法失效。
其中一种解决方法是使用 Triplet 函数构造一个能够学习如何计算相似度的神经网络。虽然 Triplet 这个方法并不在本文介绍范围,但为了读者可以横向对比相关方法,这里粗略的介绍以下基于 Triplet 的做法。
Triplet 的做法很简单,人工构建一个三元集合,该三元集合包括(图片 A,与 A 相似的图片 B,与 A 不相似的图片 C),期望该神经网络接受两个图片输入,若为相似,则输出一个较高的分数,若不相似则输出一个较低的分数。
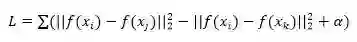
Triplet Loss 的构造如上式所示,其中 f(xi) 为原图在神经网络输出的分数,f(xj) 相似图在神经网络输出的分数,f(xk) 为不相似图片的输出分数,在这条表达式中,我们期待相似图片的分数之间,尽量接近,而不相似图片的分数尽量远离。在不考虑α时有个问题,显然,
在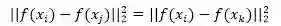
这样就没有达到我们希望相似图片和不相似图片的分数在空间上存在一定的间隔这个目标,而 α 的设定,就是这个间隔。
显然,α 设定太小,神经网络不太容易区分相似图片,而设定太大,则相当于对神经网络提出更高的要求,神经网络的收敛会更加不稳定。
Triplet 适合图片检索时每个类别的样本不大的情况下,比如人脸检测。但有研究指出,Triplet 集合的构建会影响训练的效果,也就是该如何人工的定义相似和不相似,所以也有相关工作在构建 Triplet 上展开,但本文主要说的是另一种方法,即基于哈希的三种方法。
Deep Learning of Binary Hash Codes for Fast Image Retrieval -- CVPR WORKSHOP 2015
之所以先选择这篇文章先作讨论,是因为这篇文章的工作的思想和上文提及的方法,和下文要提到的文章思想过度的比较自然,方便读者理解。
上文提及,最为简单的方式是使用神经网络特征层的输出用于计算空间距离来判断相似度,但这样会导致浮点型数据储存消耗和维度灾难。针对这两个问题,这篇文章提出的方法较为直接。
浮点数据怎么办?将他离散成二值型数据,也就是一串 0 和 1 的哈希,这样只需要几个 byte 就能储存一个数据了。
维度高怎么办?把他压缩成低维呗。
所以我才说这篇文章的思路是十分直接和易于理解的,十分适合放在第一篇用于过渡。
下面说说文章的具体做法:
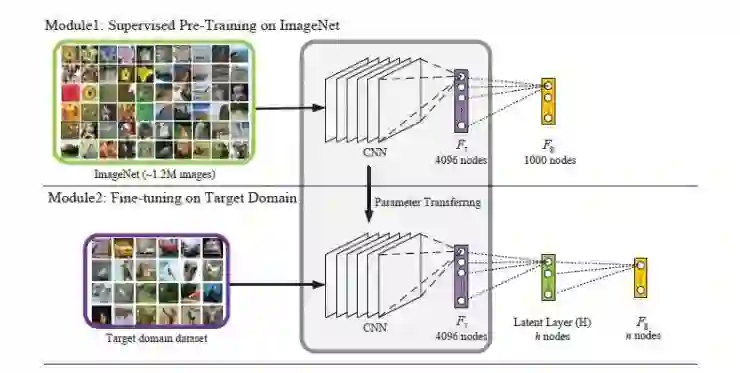
既然我们希望特征的输出可以离散化成 0 和 1,那就希望特征的分布是关于某个值对称的,然后只要根据该值作为阈值二值化即可,就这样一步步推导,自然想到使用 tanh 或 sigmoid 函数,因为其输出是关于 0 对称或关于 0.5 对称。该论文使用的 sigmoid 代替了预训练网络的倒数第二层的 ReLU 函数,且把输出的维度压缩至 12~48 之间,然后进行微调。
在微调的过程中,有几点:一般我们的微调方法是指将前面卷积的权重冻结,然后训练后面分类器的的权重。但在这里,一个是因为维度的减少,第二个是 sigmoid 做中间层的激活函数可能会造成梯度消失,神经网络的能力其实有了一定程度的衰减。因此做微调的时候,作者只是把 sigmoid 层的参数采用随机化,其余参数,包括分类器的大部分参数都保留下来,然后在训练期间,sigmoid 使用 1e-3 的学习率,其余层使用 1e-4 的学习率进行学习。对于 cifar10 来说,使用数据强化后,能达到 89% 左右的 Accuracy,图片检索的 map 能够达到 85%,可以说性能上十分可观。
论文链接:
http://www.iis.sinica.edu.tw/~kevinlin311.tw/cvprw15.pdf
参考实现:
https://github.com/flyingpot/pytorch_deephash
DEEP SUPERVISED HASHING FOR FAST IMAGE RETRIEVAL -- CVPR 2016
上文提及我们离散化时希望输出的特征的关于某个值对称,所以有文章用了 sigmoid 作为特征层的输出的激活函数,但直接引用 sigmoid 函数会导致一些问题,那有没有办法缓解这些问题?有,那就是使用正则的方法将输出约束到某一个范围内。
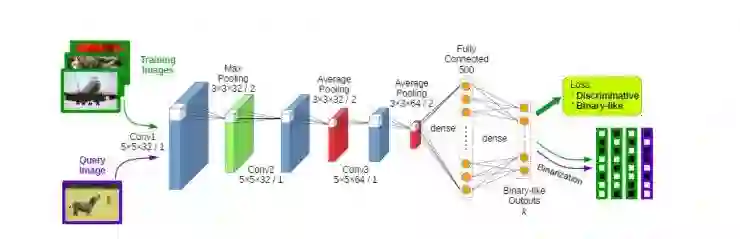
这篇 CVPR 2016 的论文做法就是如此,并没有像上述文章那样使用分类网络中间层来进行哈希,而是使用神经网络直接学习哈希编码,并用正则化方法将编码进行约束。
具体来说,就是让神经网络的输出通过正则的手法约束到 {-1,1} 之内(后续使用 0 作为阈值进行离散化),然后让网络的输出达到以下的要求,相似的时候向量距离应该较近,反之则远,下面通过其目标函数的表现形式来介绍具体过程
目标函数:
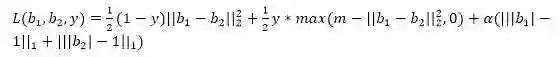
其中 b1,b2 是神经网络输出的向量,y 是一个标志,相似时记为 0,不相似时记作 1,其中超参数有两个,m 时用于控制 b1 和 b2 的最优间隔,和 α 是正则项的权重,可见当输入的是相似图片时,y=0,要使 L 最小,需要最小化两个向量的距离和正则项。而当图片不相似时,y=1,最少化 L 需要使得两个向量的距离分布在 m 的附近,以及最小化正则项。
最后的正则项使得输出的特征向量分布在 {-1,1}。
而下图是展示的是 m 和 α 对输出分布的影响。
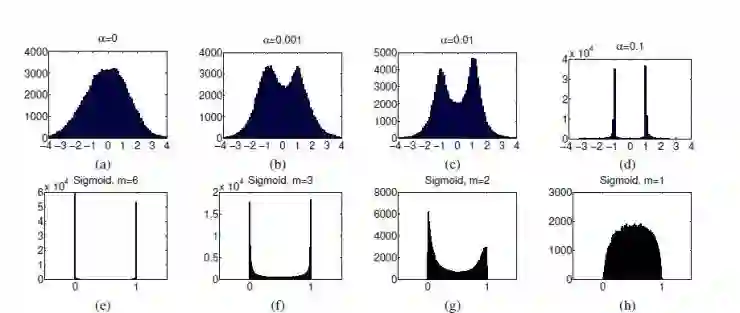
对于 CIFAR-10 来说,最终 map 只能 0.54~0.61,比上文提到的第一个方法要低,但实质这个方法要更灵活。
论文链接:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Liu_Deep_Supervised_Hashing_CVPR_2016_paper.pdf
参考实现:
https://github.com/yg33717/DSH_tensorflow
Feature Learning based Deep Supervised Hashing with Pairwise Labels——IJCAI 2016
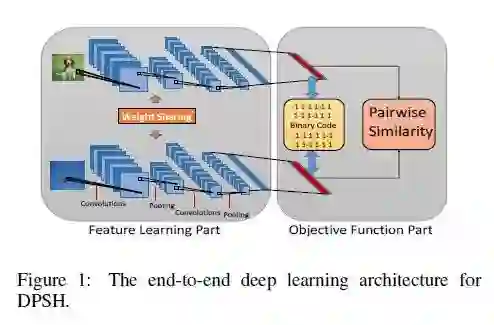
如图所示,这篇文章和上文提及的第二种方法大致相似。不采用分类网络的中间层作为特征,而是直接采取一个神经网络进行哈希函数的学习,并用正则方法将输出的特征的序列约束到一定范围内。
下面通过目标函数的形式来说明具体过程:
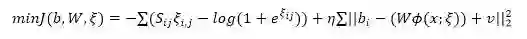
其中 b 为输出向量,Sij 是 label,相似为 1,否则为 0,ξij=bi*bjT,而 W,v 分别是最后一层的权重和偏置,而ϕ(x;ξ) 即是倒数第二层输出。
算法的更新步骤如下:

该方法在 CIFAR-10 数据集上取得 0.71~0.80 的 map 值。
论文链接:
https://cs.nju.edu.cn/lwj/paper/IJCAI16_DPSH.pdf
参考实现:
https://github.com/jiangqy/DPSH-pytorch
总结
本文分享了之前使用手工设计规则的方法来提取图片特征用于衡量相似度,随后介绍了深度学习在图片搜索的过程,并给出三篇文章介绍了图片检索任务的大体框架和思路流程。
┏(^0^)┛欢迎分享,明天见!





