qa_match:一款基于深度学习的层级问答匹配工具


文章作者:王勇、陈璐
内容来源:58技术
qa_match于2020年3月份开源,具备的Features如下:
支持快速搭建一套基于QABot的问答系统
基于 tensorflow 框架进行开发,灵活性高,可扩展性强
代码简洁,支持领域、意图的快速识别,领域意图模型融合,识别准确率高
模型训练输入格式简单
模型训练过程中支持基于测试集的最优效果model 保存
对信息含量少、语序不一致、语义相同但问法不同等难以识别的问题都能较好识别
为什么需要qa_match
基于QABot一问一答的业务咨询服务是智能客服系统的核心功能,依赖知识库进行自动问答,知识库一般是通过人工总结、标注、机器挖掘的方式进行构建,知识库中包含大量的标准问题,每个标准问题有一个标准答案和一些扩展问法,我们称这些扩展问法为扩展问题。在实际场景中,知识库一般具有两级结构,每个标准问题及其扩展问题都有一个类别,我们称为领域,同时我们把标准问题称为意图,一个领域包含多个意图。实现问答的思路是当用户输入一个query时,我们通过一定的策略(如分类、检索、匹配等)从知识库中找到与用户query语义最相近的问题,并把对应的答案回复给用户。具体流程如下图所示:
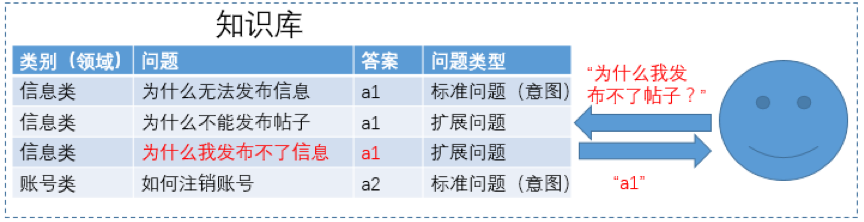
在QABot一问一答实际应用中,当用户提问一个问题时,系统一般会给予用户三种回答方式:当用户提问问题与知识库中标准问题语义匹配程度很高时,系统会直接回复标准答案答案(唯一回答)。当用户提问问题语义比较模糊时,系统会回复用户一个标准问题列表,让用户选择想问的问题(列表回答)。当用户提问问题与业务咨询无关时,系统会拒绝回答(拒识)。
在QABot一问一答实际场景下经常会遇到如下难点:
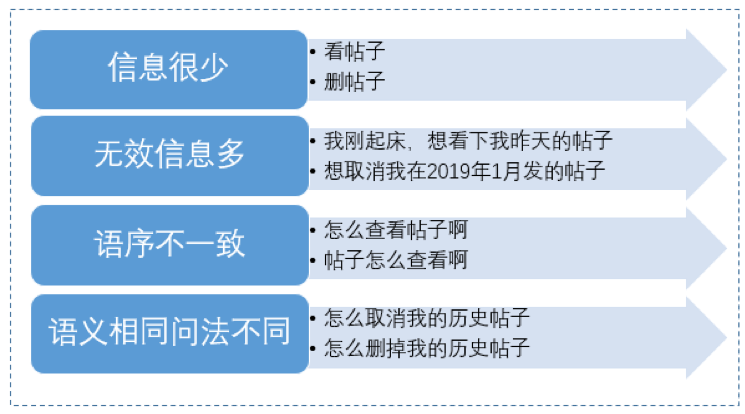
针对上述问题,现有技术方案通常采用单模型分类、匹配、检索的方式来直接识别用户意图,这样虽然能部分解决上述问题,但在我们的应用场景效果不是很理想。为了提升问答效果,我们实现了一种类似bagging方法的模型融合策略qa_match。qa_match用标准问题、扩展问题和它们对应的类别训练BiLSTM领域分类模型,用标准问题当做意图,标准问和扩展问题当做语料训练DSSM意图匹配模型,对用户问题先进行BiLSTM领域分类,然后进行DSSM意图匹配,最后对分类结果和匹配结果进行融合。qa_match于2018年9月份上线,并在我们的应用场景取得了最佳效果。qa_match虽然实现逻辑简单,但高效、问答效果不错,后续我们考虑在qa_match中开源预训练模型和知识库半自动挖掘流程。
算法架构
qa_match主要包含的三个体模块,架构如下图所示:
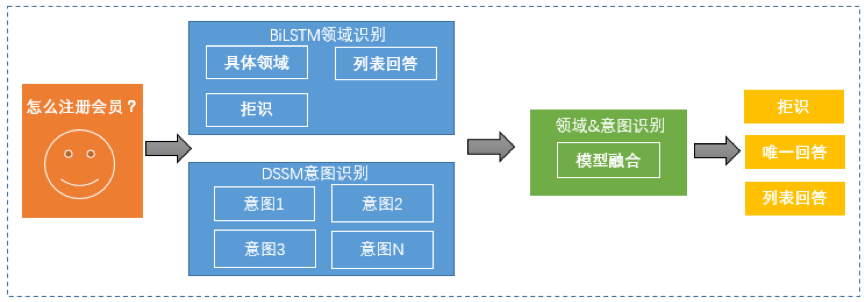
为了更准确理解用户问题属于哪个意图,可以先对用户问题进行领域识别,用识别出的领域来约束后续的意图识别,使整体的问答匹配更准确。qa_match领域包括三大类:“拒识”,“列表回答”和“具体领域”,具体领域是指账号类,信息类等具体的类别。“拒识”和“列表回答”是两个抽象的领域,“拒识”指的是应该拒绝回答用户的问题,“列表回答”指的是用问题列表询问用户想问哪个问题。
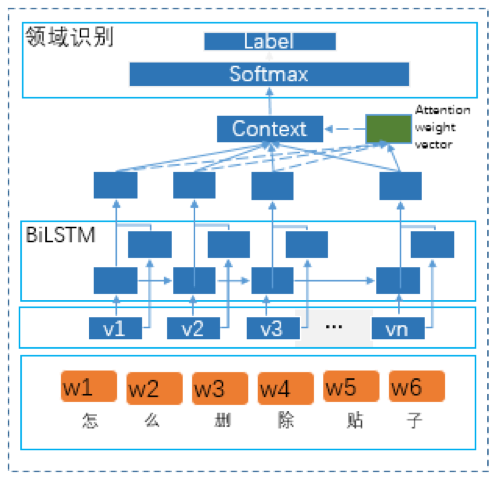
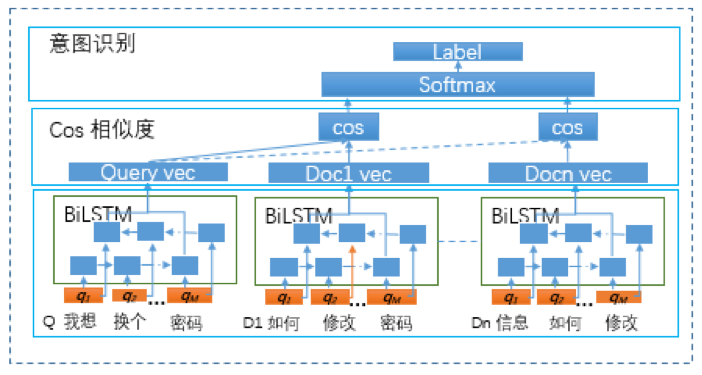
qa_match中采用BiLSTM+attention的方式进行领域识别(如下图),一方面考虑到领域类别较少,训练性能问题,不宜选择较复杂的分类模型。另一方面由于BiLSTM具有双向全局化处理方式、记忆单元、较复杂的门机制等特点,在对短文本时序数据进行处理时,相对于其他RNN类模型,BiLSTM在避免梯度消失的同时,更容易对上下文进行完整建模。BiLSTM和attention机制的组合,更容易找出对识别具有贡献的特征,使得领域识别更加精准。
意图识别是判断用户问题可能属于哪些标准问题,为了精确识别用户的意图,我们既可以对用户意图进行分类又可以进行匹配。但由于用户意图种类很多,单纯的分类任务效果要逊于匹配任务。深度文本匹配任务可以用representation-based模型、interaction-based模型。representation-based模型是将文本转化为句向量后,再计算句向量间的相似度,但它容易产生语义偏移的现象。interaction-based模型的核心思想是获取交叉矩阵,进行更细粒度的匹配,它可以解决语义偏移的现象,在很多文本匹配比赛中都获得了优异的效果。
我们尝试了上述两类模型,发现在工业级数据集中,以DSSM为代表的representation-based模型具有更好地表现,而interaction-based模型因为同一类问题的表达方式过于丰富,反而效果不如DSSM,由此qa_match中采用DSSM进行意图识别。
DSSM(Deep Structured Semantic Models)深度语义匹配模型,结构上一般分为:输入层、表示层、匹配层。DSSM通常把query和多个doc表征为相应的语义向量,并通过计算余弦相似度来衡量query和doc的距离,最终训练出语义相似度模型,该模型可以用来很好的预测两个句子的语义相似度。
qa_match在训练DSSM模型时,由于知识库中每个标准问题都有若干个扩展问题,为了让模型学习到它们具有相同的语义,我们通过下面的方法构建训练集:从知识库随机抽取一个query(标准问题或扩展问题),使用这个query对应的标准问题作为正例,从其余的标准问题中随机抽取N条作为负例,通过训练,模型可以很好地表示这一类问题的语义。在线推理时,我们使用用户问题作为query,所有的标准问题作为doc,为保证推理性能我们事先对每个doc做特征表征得到相应向量并保存在计算图里,线上我们只需用BiLSTM对query进行特征表征得到其对应的向量,然后与事先保存好的doc对应的向量计算余弦相似度,最终取相似度最高的topn doc做为query的候选意图做为意图识别模块的输出。
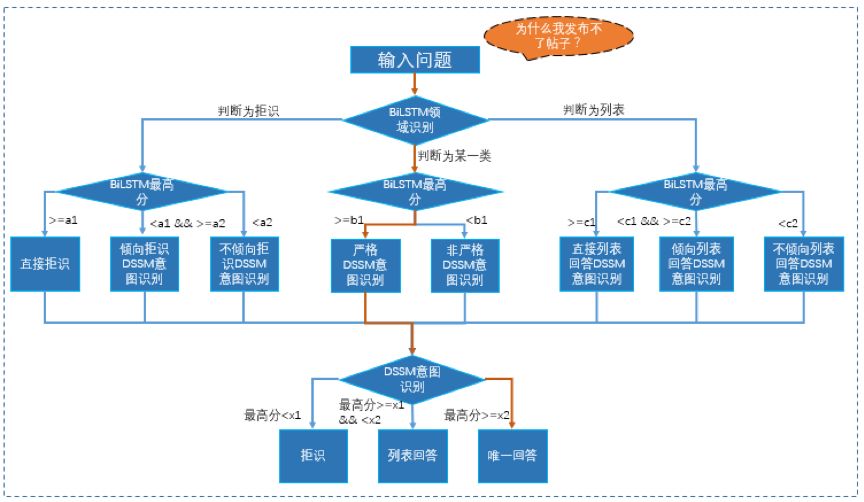
对用户问题进行领域识别和意图识别,得到问题所属领域和意图范围后,我们考虑对两种结果进行融合,以获取用户的真实意图并给予合适的回答(唯一回答、列表回答、拒绝回答)。模型融合的思路是:用户问题所属领域具有较高的置信度(领域识别打分较高)时,对应的意图范围倾向于保留该领域下的意图,并根据意图识别模型的置信度情况给予合适回答。
当前版本的模型融合主要是通过人工及统计经验配置参数,使用方可按照各自的场景数据进行配置。流程如下图所示,举个例子:如当用户提问“为什么我发布不了帖子?”,Bi-LSTM领域识别成“信息类”的概率为0.99,DSSM意图识别TOP1为“为什么无法发布信息?”的概率为0.98。当“信息类”的概率>=0.9(b1)且“为什么无法发布信息?”的概率>=0.95(x2)时候,结果按照下图黄色箭头所示流程进行融合,最终用户提问被匹配为标准问题“为什么无法发布信息?”并给予唯一回答,其它分支类似。
如何训练qa_match
qa_match支持两层结构的知识库问答,训练集中的一条问题需要同时具有意图标签和领域标签。但是对于简单的识别的任务,也可以直接使用本工具提供的领域识别模型或者意图识别模型。
1. 数据准备
我们总共需要四种数据:
数据中的“问题”要求以空格分隔。
2. 项目运行
要完成层级问答匹配任务,只需要三步:先进行领域识别,再进行意图识别,最后进行模型融合。我们将执行的命令写进了脚本run.sh里面,只需要执行命令bash run.sh即可。
3. 模型融合参数设置
我们模型融合参数的选择是基于统计的,首先会在测试集上计算同一参数不同阈值所对应标签的f1值,然后选取较大的f1值(根据项目需求可偏重准确率/覆盖率)对应的阈值做为该参数的取值。如:在选取BiLSTM拒绝回答标签对应参数阈值a1(2.5模型融合图中的a1)时,先会在测试集上确定不同的a1取值对应模型的回答标签(模型top1回答为拒绝回答&分值大于a1时则认为拒绝回答,否则认为应该回答),后续根据样本的真实标签计算f1值,最后选取合适的f1值(根据项目需求可偏重准确率/覆盖率)对应的取值作为a1的值。具体使用说明请参考github仓库中的README。
未来规划
未来我们会继续优化扩展qa_match的能力,计划开源如下:
(3)目前tensorflow已发版到2.1版本,后续我们会根据需求发布tensorflow 2.X版本或pytorch版本的qa_match。
如何贡献&问题反馈
本次开源只是qa_match贡献社区的一小步,我们诚挚地希望开发者向我们提出宝贵的意见。
您可以挑选以下方式向我们反馈建议和问题:
作者简介
王勇,58同城 AI Lab 算法架构师,主要负责58智能问答相关算法研发工作。
陈璐,58同城 AI Lab 资深算法工程师,主要负责58智能质检相关算法研发工作。
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:

关于我们:

一个在看,一段时光!👇


