中科院计算所范意兴专访: 深度文本匹配工具 MatchZoo 背后的个中细节
AI 科技评论按:日前,中国科学院计算技术研究所网络数据科学与技术重点实验室开源深度文本匹配项目 MatchZoo。据悉,MatchZoo 整合了当前最流行的深度文本匹配的方法(包括 DRMM、MatchPyramid、 DUET、 MVLSTM、aNMM、 ARC-I、ARC-II、 DSSM、CDSSM 等算法的统一实现),提供基准数据集(例如 WiKiQA 数据)进行开发与测试,可以应用到的任务场景包括文本检索、自动问答、复述问题、对话系统等等。详细信息可以参见:深度文本匹配开源工具(MatchZoo)
AI 科技评论注意到,短短一周时间,该项目在 GitHub 上的 star 数便达到 480 个,在 MatchZoo 微信群里,大家不断提出相应的改进建议以及使用过程中碰到的 bug,开发人员也在持续解疑中。
MatchZoo 的开源毫无疑问让文本匹配任务更加便利,那么,在这一项目背后,究竟有哪些成员在努力,做这一项目的初衷是什么,在开源过程中又遇到了哪些挑战?带着这些疑问,AI 科技评论第一时间联系到该项目的核心开发人员——中科院计算所的博士生范意兴,以下为AI 科技评论与他的交流内容。
初衷以及团队
据范意兴介绍,MatchZoo 项目由中科院计算所的郭嘉丰研究员、兰艳艳副研究员以及程学旗研究员发起,目前团队的开发成员中有来自中科院计算所、清华大学以及美国 UMASS 大学的研究生。
「项目的核心开发人员是来自中科院计算所的学生,包括我、庞亮以及侯建鹏,我们几个完成了项目的初期的整体框架的设计与开发,并实现了大部分的文本匹配的模型。后续有来自 UMASS 的杨柳和清华大学的郑玉昆加入,在原来项目的基础上,加入了更多的文本匹配的模型。」

上图从左至右:侯建鹏,范意兴,庞亮
为什么会想到研发这样一套框架并进行开源呢?范意兴对 AI 科技评论说到,「文本匹配任务是一个从信息检索任务、问答任务、对话任务中抽象出来的核心问题,也是我们实验室小组的一个重要方向,我们在文本匹配任务上已经积累了许多原创的模型,比如 MatchPyramid、MV-LSTM、MatchSRNN、DRMM 等等,但是没有一个统一的框架方便大家使用这些模型,同时,学术界在自然语言处理与信息检索研究方向也出现了大量模型,但是缺乏一个基准的环境来研究和对比已有的模型。」
基于前期的积累和当前的研究现状,他们选择开源深度文本匹配项目 MatchZoo。
他表示,「MatchZoo 旨在方便大家对比使用已有的文本匹配模型,开发新的文本匹配模型,以及把这些模型非常便捷的应用到自己的工作中去。」
MatchZoo 结构
根据此前介绍,可以看到,MatchZoo 使用了 Keras 中的神经网络层,由数据预处理、模型构建、训练与评测三大模块组成,具体结构如下图。
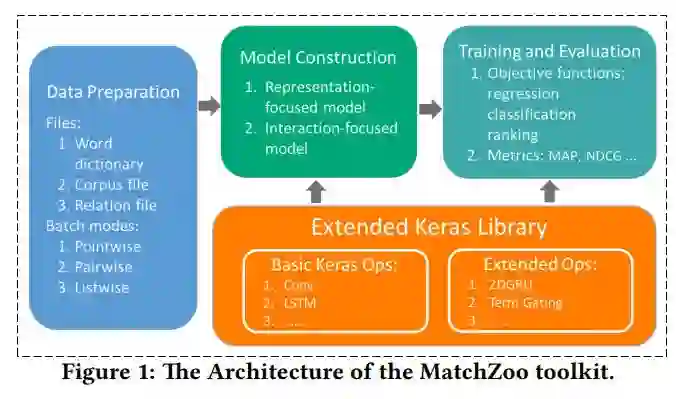
数据预处理模块:该模块包含通用的文本预处理功能,如分词、词频过滤、词干还原等,并将不同类型文本匹配任务的数据处理成统一的格式。
同时该模块针对不同的任务需求提供了不同的数据生成器,包括有基于单文档的数据生成器、基于文档对的数据生成器、以及基于文档列表的数据生成器。不同的数据生成器可适用于不同的文本匹配任务,如文本问答、文本对话、以及文本排序等。
模型构建模块:该模块包含了深度学习模型中广泛使用的普通层,如卷积层、池化层、全连接层等。除此之外,在这一模块中,他们还针对文本匹配定制了特定的层,如动态池化层、张量匹配层等。
训练与评测模块:该模块提供了针对回归、分类、排序等问题的目标函数和评价指标函数。用户可以根据任务的需要选择合适的目标函数。
在模型评估时,MatchZoo 也提供了多个广为使用的评价指标函数,如 MAP、NDCG、Precision,Recall 等。
而针对这些模块具体的细节,AI 研习社与范意兴进行了详细讨论,点击此处查看更多问答环节。
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请点击阅读原文
▼▼▼

————————————————————




