深度文本匹配开源工具(MatchZoo)

中国科学院计算技术研究所网络数据科学与技术重点实验室近日发布了深度文本匹配开源项目MatchZoo。MatchZoo是一个Python环境下基于TensorFlow开发的开源文本匹配工具,让大家更加直观地了解深度文本匹配模型的设计、更加便利地比较不同模型的性能差异、更加快捷地开发新型的深度匹配模型。MatchZoo提供了基准数据集(TREC MQ系列数据、WiKiQA数据等)进行开发与测试,整合了当前最流行的深度文本匹配的方法(包括DRMM[1], MatchPyramid[2], DUET[3], MVLSTM[4], aNMM[5], ARC-I[6], ARC-II[6], DSSM[7], CDSSM[8] 等算法的统一实现),旨在为信息检索、数据挖掘、自然语言处理、机器学习等领域内的研究与开发人员提供便利, 可以应用到的任务场景包括文本检索,自动问答,复述问题,对话系统等等。作为一个开源项目,欢迎大家给我们提供宝贵的建议与意见,同时也欢迎大家申请加入我们的开发队伍。
GitHub: https://github.com/faneshion/MatchZoo
MatchZoo工具具有容易拓展和便于设计新的深度文本匹配模型的特点,其结构如图所示:
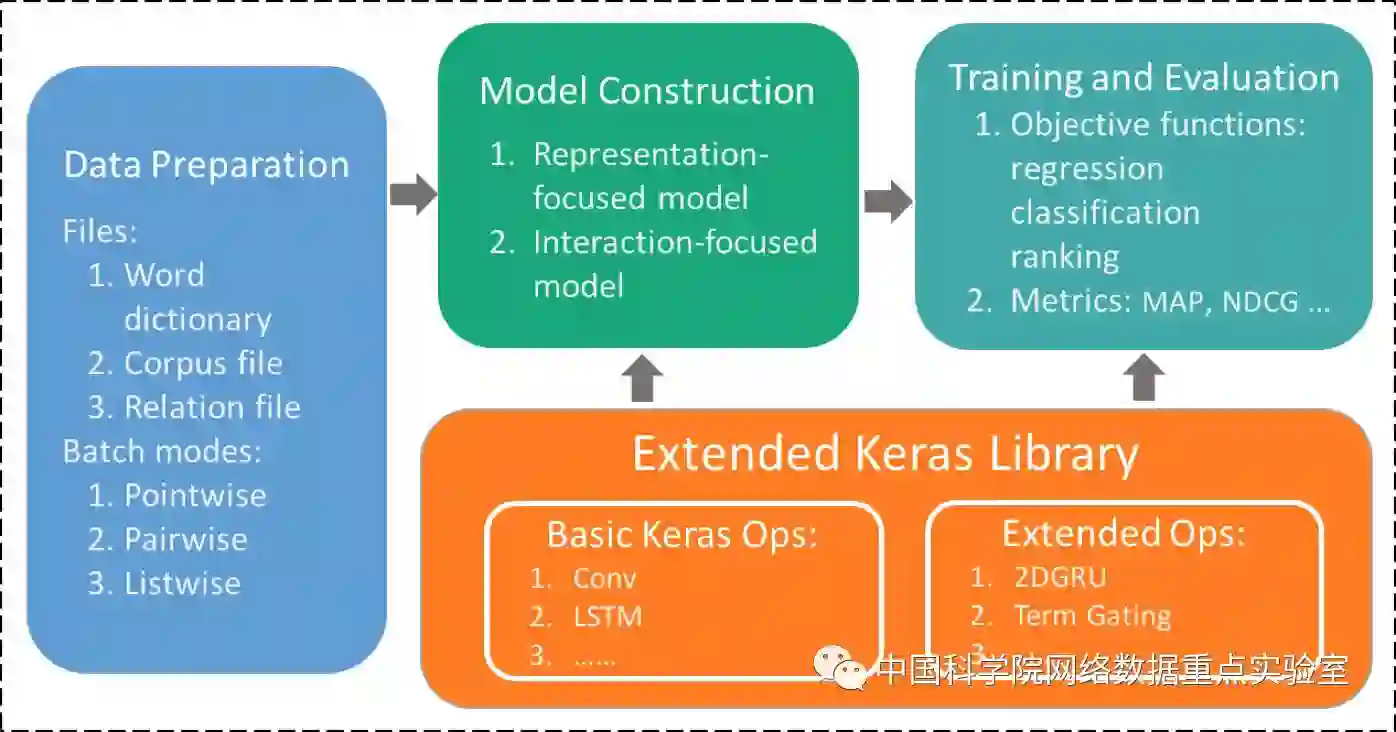
MatchZoo使用了Keras中的神经网络层,并有数据预处理,模型构建,训练与评测三大模块组成:
数据预处理模块(matchzoo/inputs/):该模块包含通用的文本预处理功能,如分词、词频过滤、词干还原等,并将不同类型文本匹配任务的数据处理成统一的格式,具体包含如下的几个文件:
corpus_preprocessed.txt:问题及回答内容文件,每行以(id, length, word_id)格式书写,分别表示问题或者回答的id,文本长度,以及词id;
relation_train.txt, relation_valid.txt, relation_test.txt:训练, 验证, 测试文件,每行以(rel,query_id, doc_id) 格式书写,分别表示问题与回答的相关度(数据中1为相关,0为不相关),问题的id,以及答案的id;
embed_glove_d50:词向量文件,每行以(id, embeddings)格式书写,分别表示词向量的id,以及每个embedding分量,该文件根据模型需要可选择性的提供。
同时该模块针对不同的任务需求提供了不同的数据生成器,包括有基于单文档的数据生成器、基于文档对的数据生成器、以及基于文档列表的数据生成器。不同的数据生成器可适用于不同的文本匹配任务,如文本问答、文本对话、以及文本排序等。
模型构建模块(machzoo/models/, matchzoo/layers/):该模块基于Keras以帮助我们快速开发。Keras中包含了深度学习模型中广泛使用的普通层,如卷积层、池化层、全连接层等,除此之外,在matchzoo/layers/中,我们还针对文本匹配定制了特定的层,如动态池化层、张量匹配层等。这些基本的层操作使得我们能够快速高效地实现复杂的深度文本匹配的模型,在matchzoo/models/中,我们实现了目前主流的深度文本匹配模型(如DRMM, MatchPyramid, DUET, MVLSTM, aNMM, ARC-I, ARC-II, DSSM, CDSSM等),具体的模型介绍请参照后续的模型部分。
训练与评测模块(matchzoo/losses, matchzoo/metrics/):该模块提供了针对回归、分类、排序等问题的目标函数和评价指标函数。例如,在文本排序中常用的基于单文档的目标、基于文档对的目标、以及基于文档序列的目标。用户可以根据任务的需要选择合适的目标函数。在模型评估时,MatchZoo也提供了多个广为使用的评价指标函数,如MAP、NDCG、Precision,Recall等。同时,在文本排序任务中,MatchZoo还能生成兼容TREC的数据格式,可以方便地使用trec_eval[9]来进行模型评估。
基准测试
我们采用TREC MQ系列基准数据、WikiQA基准数据等进行开发与测试,以下我们以WikiQA数据为例说明MatchZoo的使用。在项目的数据文件夹的WikiQA/run_data.sh 中,我们提供了从数据下载到预处理并生成MatchZoo数据格式的脚本,直接运行run_data.sh即可生成所需的数据。同时,matchzoo的模型文件夹中,针对WikiQA任务,我们为不同的模型配置了运行所需的参数,参数配置在matchzoo/models/README中有详细的说明。
在训练时,只需在MatchZoo/matchzoo中运行:
python main.py --phase train --model_file models/wikiqa_config/drmm_wikiqa.config
在测试时,可先在配置文件中指定要加载的模型参数文件,然后在MatchZoo/matchzoo中运行:
python main.py --phase predict --model_file models/wikiqa_config/drmm_wikiqa.config
我们对比了以下10个模型,不同模型的性能如下所示:
模型 |
性能指标 |
||
NDCG@3 |
NDCG@5 |
MAP |
|
DSSM |
0.3412 |
0.4179 |
0.3840 |
CDSSM |
0.5489 |
0.6084 |
0.5593 |
ARC-I |
0.5680 |
0.6317 |
0.5870 |
ARC-II |
0.5647 |
0.6176 |
0.5845 |
MV-LSTM |
0.5818 |
0.6452 |
0.5988 |
DRMM |
0.6107 |
0.6621 |
0.6195 |
aNMM |
0.6160 |
0.6696 |
0.6297 |
DUET |
0.6065 |
0.6722 |
0.6301 |
MatchPyramid |
0.6317 |
0.6913 |
0.6434 |
DRMM_TKS |
0.6458 |
0.6956 |
0.6586 |
由于WikiQA数据量大小的限制,这里ARC-I, ARC-II, MV-LSTM, DRMM, aNMM, DUET, MatchPyramid, DRMM_TKS都使用了预先训练好的Glove[10]词向量来初始化单词表达。这里的评价指标的得分是根据在验证数据集上的MAP指标选出的最佳模型在测试数据集上计算所得。由于WikiQA是一个排序的问题,这里统一采用的是pair-wise的hinge 损失函数。不同模型在训练数据集上的损失曲线如下图1所示,同时,不同模型在测试数据集上的MAP指标如图2所示。
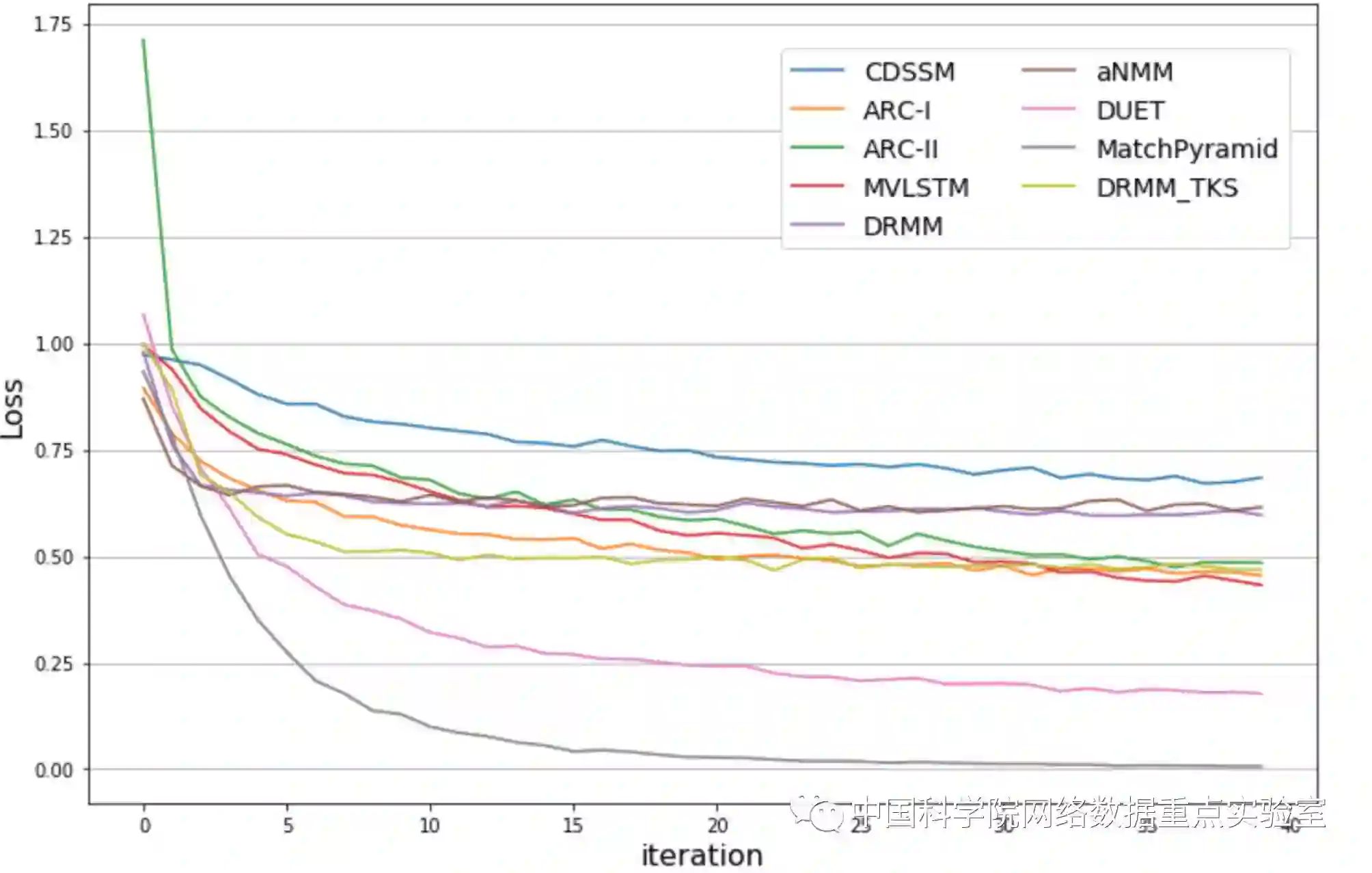
图 1 训练loss曲线图
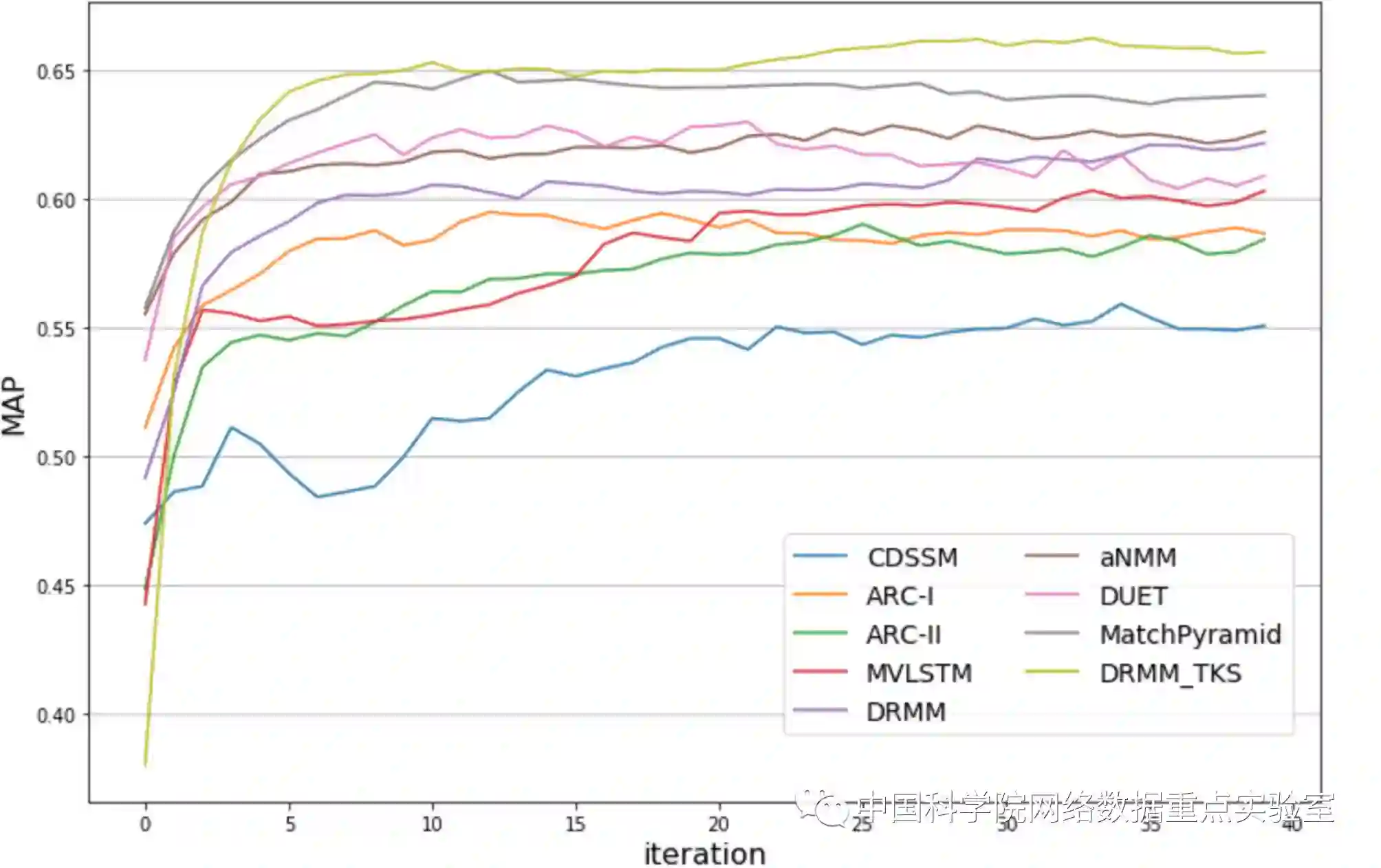
图 2 测试的MAP性能曲线图
欢迎大家关注我们的MatchZoo项目和我们的后续持续开发。大家可以在https://github.com/faneshion/MatchZoo/issues提出问题和建议,我们会在上面回复大家的提问。

[1] Guo,Jiafeng, Yixing Fan, Qingyao Ai, and W. Bruce Croft. "A deep relevancematching model for ad-hoc retrieval." In Proceedings of the 25th ACMInternational on Conference on Information and Knowledge Management, pp. 55-64.ACM, 2016.
[2] Pang,Liang, Yanyan Lan, Jiafeng Guo, Jun Xu, Shengxian Wan, and Xueqi Cheng."Text Matching as Image Recognition." In AAAI, pp. 2793-2799. 2016.s
[3] Mitra,Bhaskar, Fernando Diaz, and Nick Craswell. "Learning to Match using Localand Distributed Representations of Text for Web Search." In Proceedings ofthe 26th International Conference on World Wide Web, pp. 1291-1299.International World Wide Web Conferences Steering Committee, 2017.
[4] Wan,Shengxian, Yanyan Lan, Jiafeng Guo, Jun Xu, Liang Pang, and Xueqi Cheng."A Deep Architecture for Semantic Matching with Multiple PositionalSentence Representations." In AAAI, pp. 2835-2841. 2016.
[5] Yang,Liu, Qingyao Ai, Jiafeng Guo, and W. Bruce Croft. "aNMM: Ranking shortanswer texts with attention-based neural matching model." In Proceedingsof the 25th ACM International on Conference on Information and KnowledgeManagement, pp. 287-296. ACM, 2016.
[6] Hu,Baotian, Zhengdong Lu, Hang Li, and Qingcai Chen. "Convolutional neuralnetwork architectures for matching natural language sentences." InAdvances in neural information processing systems, pp. 2042-2050. 2014.
[7] Huang,Po-Sen, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck."Learning deep structured semantic models for web search usingclickthrough data." In Proceedings of the 22nd ACM internationalconference on Conference on information & knowledge management, pp.2333-2338. ACM, 2013.
[8] Shen,Yelong, Xiaodong He, Jianfeng Gao, Li Deng, and Grégoire Mesnil. "A latentsemantic model with convolutional-pooling structure for informationretrieval." In Proceedings of the 23rd ACM International Conference onConference on Information and Knowledge Management, pp. 101-110. ACM, 2014.
[9] https://github.com/usnistgov/trec_eval
[10] https://nlp.stanford.edu/projects/glove/



