中科院计算所发布MatchZoo 2.0, 深度文本匹配工具
【导读】深度文本匹配在检索式问答、文本检索等领域都有较为广泛的应用,MatchZoo是一款深度文本匹配的工具。它是为了促进深度文本匹配模型的设计比较和共享而开发。这里有很多像DRMM,MatchPyramid, MV-LSTM, aNMM, DUET, ARC-I, ARC-II, DSSM和 CDSSM一样的深度匹配模型,使用统一的接口进行封装。MatchZoo主要解决的任务有文档检索,问题回答,会话应答排序,同义句识别,等等。该项目主要由中科院网络数据科学与技术重点实验室团队维护。

请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“MZoo” 就可以获取深度匹配论文论文下载链接~
专知《深度学习:算法到实战》2019年1月正在开讲,欢迎报名!
MatchZoo 结构
根据此前介绍,可以看到,MatchZoo 使用了 Keras 中的神经网络层,由数据预处理、模型构建、训练与评测三大模块组成,具体结构如下图。
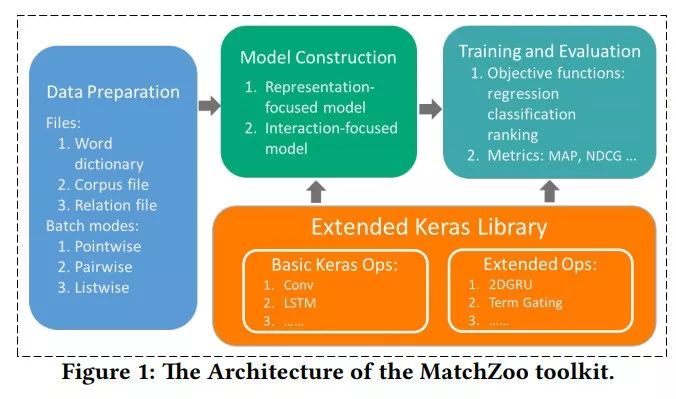
数据预处理模块:该模块包含通用的文本预处理功能,如分词、词频过滤、词干还原等,并将不同类型文本匹配任务的数据处理成统一的格式。
同时该模块针对不同的任务需求提供了不同的数据生成器,包括有基于单文档的数据生成器、基于文档对的数据生成器、以及基于文档列表的数据生成器。不同的数据生成器可适用于不同的文本匹配任务,如文本问答、文本对话、以及文本排序等。
模型构建模块:该模块包含了深度学习模型中广泛使用的普通层,如卷积层、池化层、全连接层等。除此之外,在这一模块中,他们还针对文本匹配定制了特定的层,如动态池化层、张量匹配层等。
训练与评测模块:该模块提供了针对回归、分类、排序等问题的目标函数和评价指标函数。用户可以根据任务的需要选择合适的目标函数。
在模型评估时,MatchZoo 也提供了多个广为使用的评价指标函数,如 MAP、NDCG、Precision,Recall 等。
只需要几步就能训练和使用一个深度语义匹配模型~
首先引入matchzoo并准备好数据:

然后预处理数据

在定制损失函数与评价指标

最后初始化模型,调节超参数!

Github地址:
https://github.com/NTMC-Community/MatchZoo
使用文档:
https://matchzoo.readthedocs.io/en/2.0/
论文地址:
http://www.zhuanzhi.ai/paper/689a25f1e6fa3570d864365772f6b46e
-END-
专 · 知
专知《深度学习: 算法到实战》课程正在开讲! 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



