一文读懂推荐系统知识体系-下(评估、实战、学习资料)
本文来源于数据派THU
本文主要阐述:
推荐系统的评估(Evaluation)
推荐系统的冷启动问题(Cold Start)
推荐系统实战(Actual Combat)
推荐系统案例(Case Study)
浏览前三章的内容请见上篇。
4. 推荐系统的评估(Evaluation)
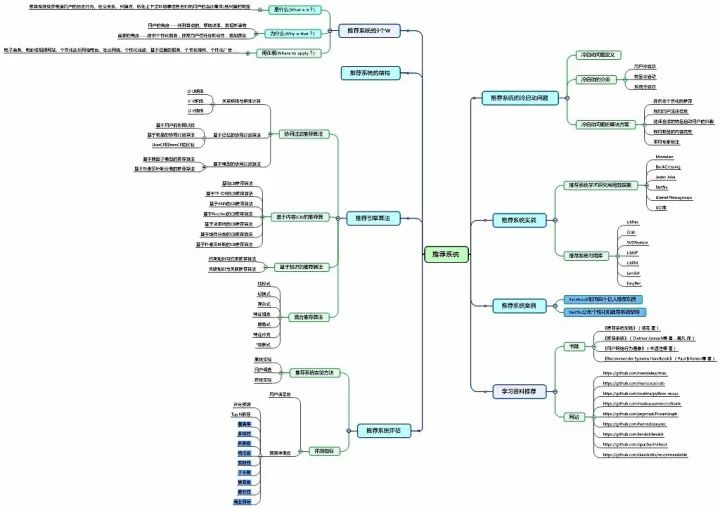
如何判断推荐系统的优劣?这是推荐系统评测需要解决的首要问题。一个完整的推荐系统一般存在3个参与方:
用户
物品提供者
提供推荐系统的网站
好的推荐系统设计,能够让推荐系统本身收集到高质量的用户反馈,不断完善推荐的质量,增加用户和网站的交互,提高网站的收入。因此在评测一个推荐算法时,需要同时考虑三方的利益,一个好的推荐系统是能够令三方共赢的系统。
4.1 推荐系统实验方法
一般来说,一个新的推荐算法最终上线,需要完成上面所说的3个实验:离线实验、用户调查和在线实验。
4.1.1 离线实验
离线实验的方法一般由如下几个步骤构成:
通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
将数据集按照一定的规则分成训练集和测试集;
在训练集上训练用户兴趣模型,在测试集上进行预测;
通过事先定义的离线指标评测算法在测试集上的预测结果。
从上面的步骤可以看到,推荐系统的离线实验都是在数据集上完成的,也就是说它不需要一个实际的系统来供它实验,而只要有一个从实际系统日志中提取的数据集即可,因此离线实验速度快,可以测试大量算法,这是离线实验的显著优点。而它的主要缺点是无法获得很多商业上关注的指标,如点击率、转化率等,而找到和商业指标非常相关的离线指标也是很困难的事情。
4.1.2 用户调查
离线实验的指标和实际的商业指标存在差距,比如预测准确率和用户满意度之间就存在很大差别,高预测准确率不等于高用户满意度。因此,如果要准确评测一个算法,需要相对比较真实的环境。最好的方法就是将算法直接上线测试,但在对算法会不会降低用户满意度不太有把握的情况下,上线测试具有较高的风险,所以在上线测试前一般需要做一次称为用户调查的测试。
测试用户的选择必须尽量保证测试用户的分布和真实用户的分布相同,比如男女各半,以及年龄、活跃度的分布都和真实用户分布尽量相同。此外,用户调查要尽量保证是双盲实验,不要让实验人员和用户事先知道测试的目标,以免用户的回答和实验人员的测试受主观成分的影响。
用户调查的优缺点也很明显。它的优点是可以获得很多体现用户主观感受的指标,相对在线实验风险很低,出现错误后很容易弥补。缺点是招募测试用户代价较大,很难组织大规模的测试用户,因此会使测试结果的统计意义不足。此外,在很多时候设计双盲实验非常困难,而且用户在测试环境下的行为和真实环境下的行为可能有所不同,因而在测试环境下收集的测试指标可能在真实环境下无法重现。
4.1.3 在线实验
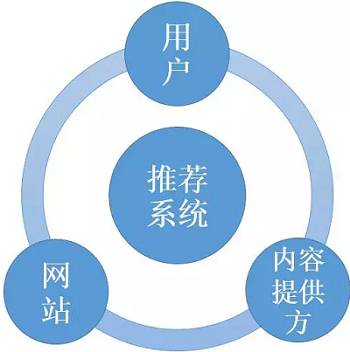
在完成离线实验和必要的用户调查后,可以将推荐系统上线做AB测试,将它和旧的算法进行比较。AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。对AB测试感兴趣的读者可以浏览一下网站 http://www.abtests.com/,该网站给出了很多通过实际AB测试提高网站用户满意度的例子,从中我们可以学习到如何进行合理的AB测试。
AB测试的优点是可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标。AB测试的缺点主要是周期比较长,必须进行长期的实验才能得到可靠的结果。因此一般不会用AB测试测试所有的算法,而只是用它测试那些在离线实验和用户调查中表现很好的算法。其次,一个大型网站的AB测试系统的设计也是一项复杂的工程。一个大型网站的架构分前端和后端,从前端展示给用户的界面到最后端的算法,中间往往经过了很多层,这些层往往由不同的团队控制,而且都有可能做AB测试。
如果为不同的层分别设计AB测试系统,那么不同的AB测试之间往往会互相干扰。比如,当我们进行一个后台推荐算法的AB测试,同时网页团队在做推荐页面的界面AB测试,最终的结果就是你不知道测试结果是自己算法的改变,还是推荐界面的改变造成的。因此,切分流量是AB测试中的关键,不同的层以及控制这些层的团队需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
4.2 评测指标
4.2.1 用户满意度
用户作为推荐系统的重要参与者,其满意度是评测推荐系统的最重要指标。但是,用户满意度没有办法离线计算,只能通过用户调查或者在线实验获得。
在线系统中,用户满意度主要通过一些对用户行为的统计得到。比如在电子商务网站中,用户如果购买了推荐的商品,就表示他们在一定程度上满意。因此,我们可以利用购买率度量用户的满意度。
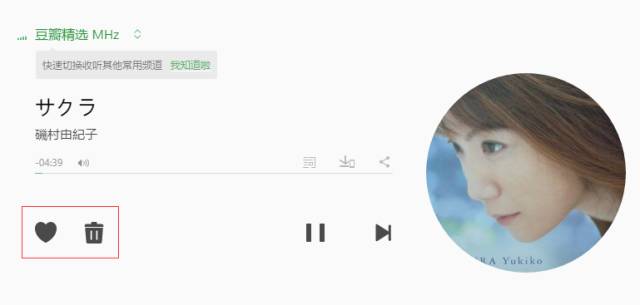
此外,有些网站会通过设计一些用户反馈界面收集用户满意度。比如在豆瓣网络电台中,都有对推荐结果满意或者不满意的反馈按钮(通过红心和垃圾箱的反馈来度量用户满意度),通过统计两种按钮的单击情况就可以度量系统的用户满意度。更一般的情况下,我们可以用点击率、用户停留时间和转化率等指标度量用户的满意度。
4.2.2 预测准确度
预测准确度衡量一个推荐系统或者推荐算法预测用户行为的能力,是最重要的推荐系统离线评测指标。从推荐系统诞生的那一天起,几乎99%与推荐相关的论文都在讨论这个指标。这主要是因为该指标可以通过离线实验计算,方便了很多学术界的研究人员研究推荐算法。
在计算该指标时需要有一个离线的数据集,该数据集包含用户的历史行为记录。然后,将该数据集通过时间分成训练集和测试集。最后,通过在训练集上建立用户的行为和兴趣模型预测用户在测试集上的行为,并计算预测行为和测试集上实际行为的重合度作为预测准确度。预测准确度的指标包括以下几类:
评分预测
很多提供推荐服务的网站都有一个让用户给物品打分的功能。如果知道了用户对物品的历史评分,就可以从中习得用户的兴趣模型,并预测该用户在将来看到一个他没有评过分的物品时,会给这个物品评多少分。
TopN推荐
网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐。TopN推荐的预测准确率一般通过准确率(precision)/召回率(recall)度量。令 R(u) 是根据用户在训练集上的行为给用户作出的推荐列表,而 T(u) 是用户在测试集上的行为列表。那么,推荐结果的召回率定义为:
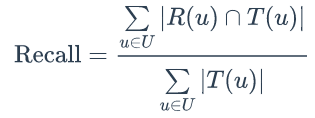
推荐结果的精准率定义为:
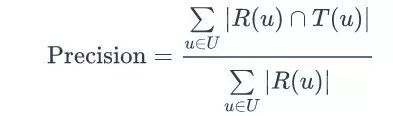
覆盖率
覆盖率(coverage)描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。假设系统的用户集合为 U,推荐系统给每个用户推荐一个长度为N的物品列表R(u)。那么推荐系统的覆盖率可以通过下面的公式计算:
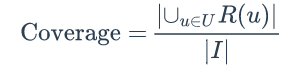
覆盖率是一个内容提供商会关心的指标。以图书推荐为例,出版社可能会很关心他们的书有没有被推荐给用户。覆盖率为100%的推荐系统可以将每个物品都推荐给至少一个用户。此外,从上面的定义也可以看到,热门排行榜的推荐覆盖率是很低的,它只会推荐那些热门的物品,这些物品在总物品中占的比例很小。一个好的推荐系统不仅需要有比较高的用户满意度,也要有较高的覆盖率。
多样性
为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同的兴趣领域,即推荐结果需要具有多样性。尽管用户的兴趣在较长的时间跨度中是一样的,但具体到用户访问推荐系统的某一刻,其兴趣往往是单一的,那么如果推荐列表只能覆盖用户的一个兴趣点,而这个兴趣点不是用户这个时刻的兴趣点,推荐列表就不会让用户满意。反之,如果推荐列表比较多样,覆盖了用户绝大多数的兴趣点,那么就会增加用户找到感兴趣物品的概率。因此给用户的推荐列表也需要满足用户广泛的兴趣,即具有多样性。
多样性描述了推荐列表中物品两两之间的不相似性。因此,多样性和相似性是对应的。假设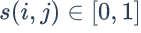
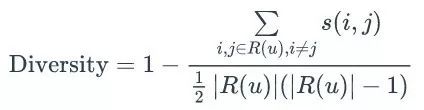
而推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
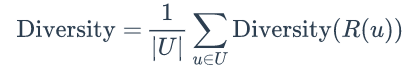
从上面的定义可以看到,不同的物品相似度度量函数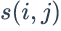
新颖性
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。在一个网站中实现新颖性的最简单办法是,把那些用户之前在网站中对其有过行为的物品从推荐列表中过滤掉。比如在一个视频网站中,新颖的推荐不应该给用户推荐那些他们已经看过、打过分或者浏览过的视频。但是,有些视频可能是用户在别的网站看过,或者是在电视上看过,因此仅仅过滤掉本网站中用户有过行为的物品还不能完全实现新颖性。
但是,用推荐结果的平均流行度度量新颖性比较粗略,因为不同用户不知道的东西是不同的。因此,要准确地统计新颖性需要做用户调查。
惊喜度
惊喜度(serendipity)是最近这几年推荐系统领域最热门的话题。令用户惊喜的推荐结果是和用户历史上喜欢的物品不相似,但用户却觉得满意的推荐。那么,定义惊喜度需要首先定义推荐结果和用户历史上喜欢的物品的相似度,其次需要定义用户对推荐结果的满意度。
用户满意度只能通过问卷调查或者在线实验获得,而推荐结果和用户历史上喜欢的物品相似度一般可以用内容相似度定义。也就是说,如果获得了一个用户观看电影的历史,得到这些电影的演员和导演集合A,然后给用户推荐一个不属于集合A的导演和演员创作的电影,而用户表示非常满意,这样就实现了一个惊喜度很高的推荐。因此提高推荐惊喜度需要提高推荐结果的用户满意度,同时降低推荐结果和用户历史兴趣的相似度。
信任度
度量推荐系统的信任度只能通过问卷调查的方式,询问用户是否信任推荐系统的推荐结果。提高推荐系统的信任度主要有两种方法:
需要增加推荐系统的透明度(transparency),而增加推荐系统透明度的主要办法是提供推荐解释。只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度。
考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。这是因为用户对他们的好友一般都比较信任,因此如果推荐的商品是好友购买过的,那么他们对推荐结果就会相对比较信任。
实时性
在很多网站中,因为物品(新闻、微博等)具有很强的时效性,所以需要在物品还具有时效性时就将它们推荐给用户。比如,给用户推荐昨天的新闻显然不如给用户推荐今天的新闻。因此,在这些网站中,推荐系统的实时性就显得至关重要。
推荐系统的实时性包括两个方面:
推荐系统需要实时地更新推荐列表来满足用户新的行为变化。比如,当一个用户购买了iPhone,如果推荐系统能够立即给他推荐相关配件,那么肯定比第二天再给用户推荐相关配件更有价值。很多推荐系统都会在离线状态每天计算一次用户推荐列表,然后于在线期间将推荐列表展示给用户。这种设计显然是无法满足实时性的。与用户行为相应的实时性,可以通过推荐列表的变化速率来评测。如果推荐列表在用户有行为后变化不大,或者没有变化,说明推荐系统的实时性不高。
推荐系统需要能够将新加入系统的物品推荐给用户。这主要考验了推荐系统处理物品冷启动的能力。对于新物品推荐能力,我们可以利用用户推荐列表中有多大比例的物品是当天新加的来评测。
健壮性
任何一个能带来利益的算法系统都会被人攻击,这方面最典型的例子就是搜索引擎。搜索引擎的作弊和反作弊斗争异常激烈,这是因为如果能让自己的商品成为热门搜索词的第一个搜索果,会带来极大的商业利益。推荐系统目前也遇到了同样的作弊问题,而健壮性(robust,鲁棒性)指标衡量了一个推荐系统抗击作弊的能力。
算法健壮性的评测主要利用模拟攻击。首先,给定一个数据集和一个算法,可以用这个算法给这个数据集中的用户生成推荐列表。然后,用常用的攻击方法向数据集中注入噪声数据,然后利用算法在注入噪声后的数据集上再次给用户生成推荐列表。最后,通过比较攻击前后推荐列表的相似度评测算法的健壮性。如果攻击后的推荐列表相对于攻击前没有发生大的变化,就说明算法比较健壮。
在实际系统中,提高系统的健壮性,除了选择健壮性高的算法,还有以下方法:
设计推荐系统时尽量使用代价比较高的用户行为。比如,如果有用户购买行为和用户浏览行为,那么主要应该使用用户购买行为,因为购买需要付费,所以攻击购买行为的代价远远大于攻击浏览行为。
在使用数据前,进行攻击检测,从而对数据进行清理。
商业目标
很多时候,网站评测推荐系统更加注重网站的商业目标是否达成,而商业目标和网站的盈利模式是息息相关的。一般来说,最本质的商业目标就是平均一个用户给公司带来的盈利。不过这种指标不是很难计算,只是计算一次需要比较大的代价。因此,很多公司会根据自己的盈利模式设计不同的商业目标。
不同的网站具有不同的商业目标。比如电子商务网站的目标可能是销售额,基于展示广告盈利的网站其商业目标可能是广告展示总数,基于点击广告盈利的网站其商业目标可能是广告点击总数。因此,设计推荐系统时需要考虑最终的商业目标,而网站使用推荐系统的目的除了满足用户发现内容的需求,也需要利用推荐系统加快实现商业上的指标。
5. 推荐系统的冷启动问题(Cold Start)
5.1 冷启动问题定义
推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,对于BAT这类大公司来说,它们已经积累了大量的用户数据,不发愁。但是对于很多做纯粹推荐系统的网站或者很多在开始阶段就希望有个性化推荐应用的网站来说,如何在对用户一无所知(即没有用户行为数据)的情况下进行最有效的推荐呢?这就衍生了冷启动问题。
5.2 冷启动的分类
冷启动问题主要分为3类:
用户冷启动,即如何给新用户做个性化推荐
物品冷启动,即如何将新的物品推荐给可能对它感兴趣的用户
系统冷启动,即如何在一个新开发的网站(没有用户,没有用户行为,只有部分物品信息)上设计个性化推荐系统,从而在网站刚发布时就让用户体会到个性化推荐
5.3 冷启动问题的解决方案
5.3.1 提供非个性化的推荐
最简单的例子就是提供热门排行榜,可以给用户推荐热门排行榜,等到用户数据收集到一定的时候,再切换为个性化推荐。Netflix的研究也表明新用户在冷启动阶段确实是更倾向于热门排行榜的,老用户会更加需要长尾推荐。
5.3.2 利用用户注册信息
用户的注册信息主要分为3种:
人口统计学信息,包括年龄、性别、职业、民族、学历和居住地
用户兴趣的描述,部分网站会让用户用文字来描述兴趣
从其他网站导入的用户站外行为,比如用户利用社交网站账号登录,就可以在获得用户授权的情况下导入用户在该社交网站的部分行为数据和社交网络数据。
这种个性化的粒度很粗,假设性别作为一个粒度来推荐,那么所有刚注册的女性看到的都是同样的结果,但是相对于男女不区分的方式,这种推荐精度已经大大提高了。
5.3.3 选择合适的物品启动用户的兴趣
用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。一般来说,能够用来启动用户兴趣的物品需要具有以下特点:
比较热门,如果要让用户对物品进行反馈,前提是用户得知道这是什么东西;
具有代表性和区分性,启动用户兴趣的物品不能是大众化或老少咸宜的,因为这样的物品对用户的兴趣没有区分性;
启动物品集合需要有多样性,在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣。
5.3.4 利用物品的内容信息
物品冷启动问题在新闻网站等时效性很强的网站中非常重要,因为这些网站时时刻刻都有新物品加入,而且每个物品必须能够再第一时间展现给用户,否则经过一段时间后,物品的价值就大大降低了。
对UserCF算法来说,针对推荐列表并不是给用户展示内容的唯一列表(大多网站都是这样的)的网站。当新物品加入时,总会有用户通过某些途径看到,那么当一个用户对其产生反馈后,和他历史兴趣相似的用户的推荐列表中就有可能出现该物品,从而更多的人对该物品做出反馈,导致更多的人的推荐列表中出现该物品。
因此,该物品就能不断扩散开来,从而逐步展示到对它感兴趣用户的推荐列表中针对推荐列表是用户获取信息的主要途径(例如豆瓣网络电台)的网站UserCF算法就需要解决第一推动力的问题,即第一个用户从哪儿发现新物品。最简单的方法是将新的物品随机战士给用户,但是太不个性化。因此可以考虑利用物品的内容信息,将新物品先投放给曾经喜欢过和它内容相似的其他物品的用户。
对ItemCF算法来说,物品冷启动就是很严重的问题了。因为该算法的基础是通过用户对物品产生的行为来计算物品之间的相似度,当新物品还未展示给用户时,用户就无法产生行为。为此,只能利用物品的内容信息计算物品的相关程度。基本思路就是将物品转换成关键词向量,通过计算向量之间的相似度(例如计算余弦相似度),得到物品的相关程度。
5.3.5 采用专家标注
很多系统在建立的时候,既没有用户的行为数据,也没有充足的物品内容信息来计算物品相似度。这种情况下,很多系统都利用专家进行标注。
代表系统:个性化网络电台Pandora、电影推荐网站Jinni。
以Pandora电台为例,Pandora雇用了一批音乐人对几万名歌手的歌曲进行各个维度的标注,最终选定了400多个特征。每首歌都可以标识为一个400维的向量,然后通过常见的向量相似度算法计算出歌曲的相似度。
6. 推荐系统实战
6.1 推荐系统学术研究常用数据集
MovieLen(https://grouplens.org/datasets/movielens/)
MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5。MovieLens包括两个不同大小的库,适用于不同规模的算法。小规模的库是943个独立用户对1 682部电影作的10 000次评分的数据;大规模的库是6 040个独立用户对3 900部电影作的大约100万次评分。
BookCrossing(http://www2.informatik.uni-freiburg.de/~cziegler/BX/)
这个数据集是网上的Book-Crossing图书社区的278858个用户对271379本书进行的评分,包括显式和隐式的评分。这些用户的年龄等人口统计学属性(demographic feature)都以匿名的形式保存并供分析。这个数据集是由Cai-Nicolas Ziegler使用爬虫程序在2004年从Book-Crossing图书社区上采集的。
Jester Joke(http://eigentaste.berkeley.edu/dataset/)
Jester Joke是一个网上推荐和分享笑话的网站。这个数据集有73496个用户对100个笑话作的410万次评分。评分范围是−10~10的连续实数。这些数据是由加州大学伯克利分校的Ken Goldberg公布的。
Netflix(http://academictorrents.com/details/9b13183dc4d60676b773c9e2cd6de5e5542cee9a)
这个数据集来自于电影租赁网址Netflix的数据库。Netflix于2005年底公布此数据集并设立百万美元的奖金(netflix prize),征集能够使其推荐系统性能上升10%的推荐算法和架构。这个数据集包含了480 189个匿名用户对大约17 770部电影作的大约10亿次评分。
Usenet Newsgroups(http://qwone.com/~jason/20Newsgroups/)
这个数据集包括20个新闻组的用户浏览数据。最新的应用是在KDD 2007上的论文。新闻组的内容和讨论的话题包括计算机技术、摩托车、篮球、政治等。用户们对这些话题进行评价和反馈。
UCI库(https://archive.ics.uci.edu/ml/datasets.html)
UCI库是Blake等人在1998年开放的一个用于机器学习和评测的数据库,其中存储大量用于模型训练的标注样本,可用于推荐系统的性能测试数据。
6.2 推荐系统可用库
-
LibRec(http://www.librec.net)

LibRec是一个覆盖了70余个各类型推荐算法的推荐系统开源算法库,有效地解决了评分预测和物品推荐两大关键的推荐问题。该项目结构清晰、代码风格良好、测试充分、注释与手册完善,基于GPL3.0协议代码开源。GitHub链接为 :https://github.com/guoguibing/librec
-
Crab(http://muricoca.github.io/crab/tutorial.html)

Crab是基于Python开发的开源推荐软件,其中实现有item和user的协同过滤。据说更多算法还在开发中,Crab的python代码看上去很清晰明了,适合一读。
系统的Tutorial可以看这里: http://muricoca.github.io/crab/
-
SVDFeature(http://svdfeature.apexlab.org/wiki/Main_Page)

一个feature-based协同过滤和排序工具,由上海交大Apex实验室开发,代码质量较高。在KDD Cup 2012中获得第一名,KDD Cup 2011中获得第三名,相关论文 发表在2012的JMLR中。SVDFeature包含一个很灵活的Matrix Factorization推荐框架,能方便的实现SVD、SVD++等方法, 是单模型推荐算法中精度最高的一种。SVDFeature代码精炼,可以用 相对较少的内存实现较大规模的单机版矩阵分解运算。另外含有Logistic regression的model,可以很方便的用来进行ensemble。
-
LibMF(http://www.csie.ntu.edu.tw/~cjlin/libmf/)

作者Chih-Jen Lin来自大名鼎鼎的台湾国立大学,他们在机器学习领域享有盛名,近年连续多届KDD-Cup竞赛上均获得优异成绩,并曾连续多年获得冠军。台湾大学的风格非常务实,业界常用的LibSVM,Liblinear等都是他们开发的,开源代码的效率和质量都非常高。
LibMF在矩阵分解的并行化方面作出了很好的贡献,针对SGD(随即梯度下降)优化方法在并行计算中存在的 locking problem 和 memory discontinuity问题,提出了一种 矩阵分解的高效算法FPSGD(Fast Parallel SGD),根据计算节点的个数来划分评分矩阵block,并分配计算节点。
-
LibFM(http://www.libfm.org/ )

作者是德国Konstanz大学的Steffen Rendle,他用LibFM同时玩转KDD Cup 2012 Track1和Track2两个子竞赛单元,都取得了很好的成绩,说明LibFM是非常管用的利器。
LibFM是专门用于矩阵分解的利器,尤其是其中实现了MCMC(Markov Chain Monte Carlo)优化算法,比常见的SGD优化方法精度要高,但运算速度要慢一些。当然LibFM中还 实现了SGD、SGDA(Adaptive SGD)、ALS(Alternating Least Squares)等算法。
-
Lenskit(http://lenskit.org/ )

这个Java开发的开源推荐系统,来自美国的明尼苏达大学的GroupLens团队,也是推荐领域知名的测试数据集Movielens的作者。
该源码托管在GitHub上(https://github.com/grouplens/lenskit)。
主要包含lenskit-api,lenskit-core, lenskit-knn,lenskit-svd,lenskit-slopone,lenskit-parent,lenskit-data- structures,lenskit-eval,lenskit-test等模块,主要实现了k-NN,SVD,Slope-One等 典型的推荐系统算法。
-
EasyRec(http://easyrec.org/ )

EasyRec是一个易集成、易扩展、功能强大且具有可视化管理的推荐系统,更像一个完整的推荐产品,包括了数据录入模块、管理模块、推荐挖掘、离线分析等。它可以同时给多个不同的网站提供推荐服务,通过tenant来区分不同的网站。架设EasyRec服务器,为网站申请tenant,通过tenant就可以很方便的集成到网站中。
7. 推荐系统案例(Case Study)
7.1 Facebook如何向十亿人推荐东西
作为全球排名第一的社交网站,Facebook利用分布式推荐系统来帮助用户找到他们可能感兴趣的页面、组、事件或者游戏等。Facebook在其官网公布了其推荐系统的原理、性能及使用情况。
https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/
Facebook中推荐系统所要面对的数据集包含了约1000亿个评分、超过10亿的用户以及数百万的物品。相比于著名的Netflix Prize ,Facebook的数据规模已经超过了它两个数据级。如何在大数据规模情况下仍然保持良好性能已经成为世界级的难题。为解决这一难题,Facebook团队使用一个分布式迭代和图像处理平台——Apache Giraph作为推荐系统的基础平台。
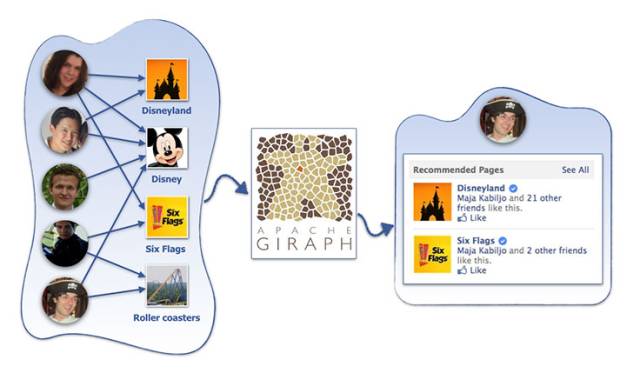
在工作原理方面,Facebook推荐系统采用的是流行的协同过滤技术。从数学角度而言,该问题就是根据用户-物品的评分矩阵中已知的值来预测未知的值。其求解过程通常采用矩阵分解(Matrix Factorization, MF)方法。MF方法把用户评分矩阵表达为用户矩阵和物品的乘积,用这些矩阵相乘的结果R'来拟合原来的评分矩阵R,使得二者尽量接近。如果把和之间的距离作为优化目标,那么矩阵分解就变成了求最小值问题。
对大规模数据而言,求解过程将会十分耗时。为了降低时间和空间复杂度,一些从随机特征向量开始的迭代式算法被提出。这些迭代式算法渐渐收敛,可以在合理的时间内找到一个最优解。随机梯度下降(Stochastic Gradient Descent, SGD)算法就是其中之一,其已经成功的用于多个问题的求解。SGD基本思路是以随机方式遍历训练集中的数据,并给出每个已知评分的预测评分值。用户和物品特征向量的调整就沿着评分误差越来越小的方向迭代进行,直到误差到达设计要求。因此,SGD方法可以不需要遍历所有的样本即可完成特征向量的求解。交替最小二乘法(Alternating Least Square, ALS)是另外一个迭代算法。其基本思路为交替固定用户特征向量和物品特征向量的值,不断的寻找局部最优解直到满足求解条件。
为了利用上述算法解决Facebook推荐系统的问题,原本Giraph中的标准方法就需要进行改变。之前,Giraph的标准方法是把用户和物品都当作为图中的顶点、已知的评分当作边。那么,SGD或ALS的迭代过程就是遍历图中所有的边,发送用户和物品的特征向量并进行局部更新。该方法存在若干重大问题。
首先,迭代过程会带来巨大的网络通信负载。由于迭代过程需要遍历所有的边,一次迭代所发送的数据量就为边与特征向量个数的乘积。假设评分数为1000亿、特征向量为100对,每次迭代的通信数据量就为80TB。其次,物品流行程度的不同会导致图中节点度的分布不均匀。该问题可能会导致内存不够或者引起处理瓶颈。假设一个物品有1000亿个评分、特征向量同样为100对,该物品对应的一个点在一次迭代中就需要接收80GB的数据。最后,Giraph中并没有完全按照公式中的要求实现SGD算法。真正实现中,每个点都是利用迭代开始时实际收到的特征向量进行工作,而并非全局最新的特征向量。
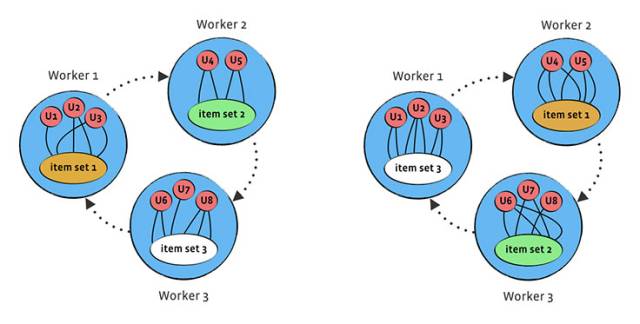
综合以上可以看出,Giraph中最大的问题就在于每次迭代中都需要把更新信息发送到每一个顶点。为了解决这个问题,Facebook发明了一种利用work-to-work信息传递的高效、便捷方法。该方法把原有的图划分为了由若干work构成的一个圆。每个worker都包含了一个物品集合和若干用户。在每一步,相邻的worker沿顺时针方法把包含物品更新的信息发送到下游的worker。这样,每一步都只处理了各个worker内部的评分,而经过与worker个数相同的步骤后,所有的评分也全部都被处理。该方法实现了通信量与评分数无关,可以明显减少图中数据的通信量。而且,标准方法中节点度分布不均匀的问题也因为物品不再用顶点来表示而不复存在。为了进一步提高算法性能,Facebook把SGD和ALS两个算法进行了揉合,提出了旋转混合式求解方法。
接下来,Facebook在运行实际的A/B测试之间对推荐系统的性能进行了测量。首先,通过输入一直的训练集,推荐系统对算法的参数进行微调来提高预测精度。然后,系统针对测试集给出评分并与已知的结果进行比较。Facebook团队从物品平均评分、前1/10/100物品的评分精度、所有测试物品的平均精度等来评估推荐系统。此外,均方根误差(Root Mean Squared Error, RMSE)也被用来记录单个误差所带来的影响。
此外,即使是采用了分布式计算方法,Facebook仍然不可能检查每一个用户/物品对的评分。团队需要寻找更快的方法来获得每个用户排名前K的推荐物品,然后再利用推荐系统计算用户对其的评分。其中一种可能的解决方案是采用ball tree数据结构来存储物品向量。ball tree结构可以实现搜索过程10-100倍的加速,使得物品推荐工作能够在合理时间内完成。另外一个能够近似解决问题的方法是根据物品特征向量对物品进行分类。这样,寻找推荐评分就划分为寻找最推荐的物品群和在物品群中再提取评分最高的物品两个过程。该方法在一定程度上会降低推荐系统的可信度,却能够加速计算过程。
最后,Facebook给出了一些实验的结果。在2014年7月,Databricks公布了在Spark上实现ALS的性能结果。Facebook针对Amazon的数据集,基于Spark MLlib进行标准实验,与自己的旋转混合式方法的结果进行了比较。实验结果表明,Facebook的系统比标准系统要快10倍左右。而且,前者可以轻松处理超过1000亿个评分。
目前,该方法已经用了Facebook的多个应用中,包括页面或者组的推荐等。为了能够减小系统负担,Facebook只是把度超过100的页面和组考虑为候选对象。而且,在初始迭代中,Facebook推荐系统把用户喜欢的页面/加入的组以及用户不喜欢或者拒绝加入的组都作为输入。此外,Facebook还利用基于ALS的算法,从用户获得间接的反馈。未来,Facebook会继续对推荐系统进行改进,包括利用社交图和用户连接改善推荐集合、自动化参数调整以及尝试比较好的划分机器等。
7.2 Netflix公布个性化和推荐系统架构
作为一家在线影片租赁提供商,Netflix能够提供超大数量的DVD,而且能够让顾客快速方便的挑选影片,同时免费递送,已经连续五次被评为顾客最满意的网站。Netflix的推荐和个性化功能在业界以精准著称,并公布了自己在这方面的系统架构。(http://techblog.netflix.com/2013/03/system-architectures-for.html)
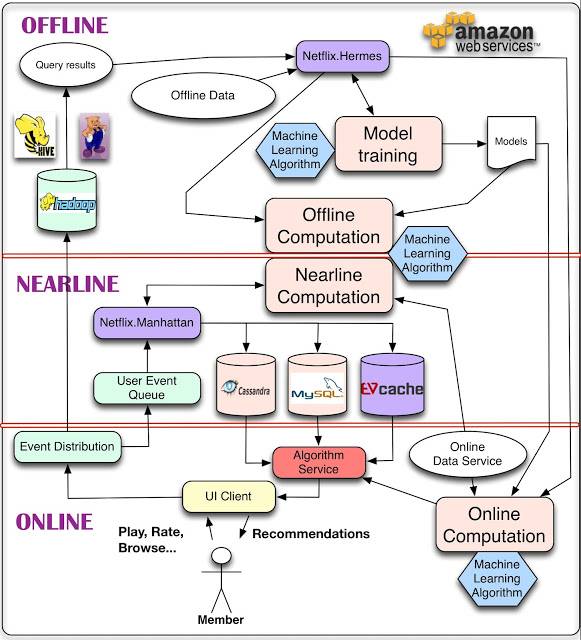
Netflix公布了他们的系统框架图,并对其中的组件和处理过程进行了解释:
对于数据,最简单的方法是存下来,留作后续离线处理,这就是我们用来管理离线作业(Offline jobs)的部分架构。计算可以以离线、接近在线或是在线方式完成。
在线计算(Online computation)能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。
离线计算(Offline computation)对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。
接近在线计算(Nearline computation)介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。
模型训练(Model training)是另一种计算,使用现有数据来产生模型,便于以后在对实际结果计算中使用。
另一块架构是如何使用事件和数据分发系统(Event and Data Distribution)处理不同类型的数据和事件。与之相关的问题,是如何组合在离线、接近在线和在线之间跨越的不同的信号和模型(Signals and Models)。最后,需要找出如何组合推荐结果(Recommendation Results),让其对用户有意义。
参考资源:
<以上稿件在参考以下资源的基础上撰写而成>:
https://www.slideshare.net/xamat/recommender-systems-machine-learning-summer-school-2014-cmu
http://www.open-open.com/lib/view/open1433322554291.html
http://www.infoq.com/cn/news/2015/06/facebook-recommender-system
https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/
http://www.infoq.com/cn/news/2015/12/Algorithm-case-10
https://github.com/mendeley/mrec
https://github.com/muricoca/crab
https://github.com/ocelma/python-recsys
https://github.com/markusweimer/cofirank
https://github.com/jegonzal/PowerGraph
https://github.com/hernad/easyrec
https://github.com/lenskit/lenskit
https://github.com/apache/mahout
https://github.com/davidcelis/recommendable
《推荐系统实践》(项亮 著)
《推荐系统》(Dietmar Jannach等 著,蒋凡 译)
《用户网络行为画像》(牛温佳等 著)
《Recommender Systems Handbook》(Paul B·Kantor等 著)




作者:李中杰,数据派研究部志愿者,清华热能系博士生。擅长数据分析处理及机器学习算法Python实现,对大数据技术充满热情,曾获天池大数据IJCAI16口碑实体商户推荐赛冠军和菜鸟网络最后一公里极速配送冠军。
猜你喜欢
想让视频网站乖乖帮你推内容?看看这位小哥是如何跟YouTube斗法的
重读经典 | 亚马逊“一键下单”的背后——个性化推荐系统的发展历程






