推荐场景下的对比学习总结
前言
最近对比学习(Contrastive Learning, CL)火得一塌糊涂,被Bengio 和 LeCun 这二位巨头在 ICLR 2020 上点名是 AI 的未来。作为普通打工人,对比学习能否带来AI质的飞越,从而导致未来出现终结者,不是我们考虑的问题。本文只聚焦于推荐领域,讨论对比学习能否提升推荐性能,帮我们早点完成OKR。
本文并非Contrastive Learning Tutorial之类的科普文章,不会讲述对比学习的发展沿革,也不会面面俱到每个技术细节。对这部分内部感兴趣的同学,可以参考张俊林大佬的《从对比学习视角,重新审视推荐系统的召回粗排模型》一文,快速入门。
接下来,本文将从以下三个方面展开:
-
讨论一下对比学习到底是什么。这一节的目的,并非为了吊书袋,我也不是什么考据狂。实在是对比学习和我们推荐常用的向量化召回,在很多底层技术上是通用的。而有一批水文,利用了这二者之间的相似性,将向量化召回算法用“对比学习”的概念重新包装,挂羊头卖狗肉,使很多同学觉得CL不过是新一波的概念炒作。

-
谈谈对比学习到底能给推荐系统带来哪些帮助。同学们不要对新技术盲目跟风,看完这一节,再来决定CL是否是解决你问题的那根稻草。 -
分析“对比学习在推荐系统中应用”的两篇典型论文。正如前面提到的,这方面的好文章并不多。很多跟风灌水之作,看标题上写着“对比学习”和“推荐”,下载下来一看,才发现不过是讲向量化召回的老生常谈。
到底什么是对比学习?怎么和向量化召回这么像?
初识对比学习,我也是不以为然的,觉得这不就是向量化召回吗?我们推荐工程师玩烂的东西,怎么CV同行们还拿来当个宝。
要说对比学习和向量化召回之间的相似性,看看我的另一篇文章《用统一框架理解向量化召回》就能有所感受。我在文章中提出了NEFP框架来构建向量化召回算法
-
N, Near, 正对应CL中“要让正样本embedding在向量空间足够近”的概念 -
F. Far, 正对应CL中“要让负样本embedding在向量空间足够远”的概念。 -
至于“引入负样本是为了让模型uniformity, 防止模型坍塌”的论调,其实对于搞推荐的同学都已经不陌生了。负样本对于召回算法的重要性已经深入人心(我的《 负样本为王: 评Facebook的向量化召回算法》一文也有小小贡献)。近年来,各大厂在如何构建easy negative, hard negative纷纷创新。相比之下,对比学习中的负样本策略还略显小儿科。 -
E, Embedding,对应CL中的encoder部分。CV/NLP/Reco各领域有各自常用的encoder方案。 -
P, Pairwise Loss,就是对“足够近,足够远”用数学形式进行量化。对比学习中常用的NCE Loss, Triplet Loss,对于搞推荐的同学,也都算是老熟人了。
看看我提出的NEFP与对比学习的关键概念是多么契合。当初对比学习还没现在这么火,否则肯定要好好蹭一波热度,拿对比学习把我的文章好好包装一下子。
但是,随着对CL的深入理解,我感觉是我浅薄了。对比学习与向量召回算法,只能算形似,也就是双塔结构、负采样策略、Loss这些底层技术被二者所共享。但是对比学习与我们推荐常用的向量化召回有着完全不同的精神内核。
-
向量化召回,属于Supervised Learning,无论是U2I, U2U, I2I, 哪两个向量应该是相似的(正例)是根据用户反馈(标注)得到的。 -
因此,在召回算法中,正样本从来就不是问题。大家从来不为找不到正样本而发愁,反而要考虑如何严格正样本的定义,将一些用户意愿较弱的信号(i.e., 噪声)从正样本中删除出去,顺便降低一下样本量,节省训练时间。 -
召回的主要研究目标是负样本,如何构建easy/hard negative,降低Sample Selection Bias。 -
对比学习,属于 Self-Supervised Learning ( SSL)的一种实现方式,产生的背景是为了解决" 标注少或无标注"的问题。 -
我之前说“召回是负样本的艺术”,那么CL更注重的应该是如何构建正样本。 -
Data Augmentation是CL的核心,研究如何将一条样本经过变化,构建出与其相似的变体。 -
Data Augmentation在CV领域比较成熟了(翻转、旋转、缩放、裁剪、移位等)。而推荐场景下,数据由大量高维稀疏ID组成,特征之间又相互关联,如何变化才能构建出合情合理的相似正样本,仍然是一个值得研究的课题。
正因如此,是否涉及Data Augmentation,在Data Augmentation上的创新如何,是我判断一篇CL论文的价值的重要标准。没有Data Augmentation,基于“user embedding与其点击过的item的embedding具备相似性”,或者“被同一个user点击过的item的embedding具备相似性”,构建出来的所谓“对比学习”,在我眼里,都是耍流氓。因为这些相似性是由用户反馈标注的,根本就不符合CL解决“少标准或无标注”的设计初衷。(当然,要是有人要和我杠,偏说U2I, I2I召回也算是Contrastive Learning,那我也没办法。就好比说算盘是计算机的鼻祖一样,你说了,那就是你对。)
除了Data Augmentation,至于如何构建负样本(没准CV研究得还没Reco深)、如何构建Encoder(CV/NLP里的结构,Reco也未必用得上)、如何建立Loss等方面,对于熟悉向量化召回的推荐打工人来说了,都老生常谈了,未必能看出什么新意思。
另外一点,CL在推荐场景下,一定是作为辅助训练任务出现的。道理很简单,User/Item之间的相似性(i.e.匹配性)才是推荐算法的重点关注。而CL关注的是"User与其变体"、"Item与其变体"之间的相似性,只在训练阶段发挥辅助作用,是不会参与线上预测的。
那么问题来了,引入CL辅助任务,能够给我们的推荐主任务带来怎么样的提升?
对比学习对于推荐系统有什么用?怎么用?
初看CL,作为Self-Supervised Learning的一种,是为了应对“少标注或无标注”的问题而提出的,感觉在推荐场景下没啥用武之地。因为大厂的推荐系统,啥都缺,就是不缺标注数据(用户反馈)。每天我们都为如何在海量数据上快点跑模型而发愁,甚至不得不抽样数据以降低输入数据的规模。“标注样本少”?不存在。
但是后来再细想一下,推荐系统中的样本丰富,也是个假象。就如何人间一样,推荐系统有海量样本不假,但是贫富差距也悬殊:
-
82定律才是推荐系统逃不脱的真香定律,20%的热门item占据了80%的曝光量,剩下80%的小众、长尾item捞不着多少曝光机会,自然在训练样本中也是少数、弱势群体 -
样本中的用户分布也有天壤之别。任何一个app都有其多数、优势人群,比如社交app中的年轻人,或者跨国app中某个先发地区的用户。相比之下,也就有少数、劣势人群在样本中“人微言轻”。
样本分布中的贫富悬殊,会带来什么危害?和人间一样,带来的是“不公平”,我们称之为bias
-
模型迎合多数人群,忽视少数人群,不利于用户增长。 -
模型很少给小众、长尾的item曝光机会,不利于建立良好的内容生态。
因此,在推荐系统中引入对比学习,解决“少数人群+冷门物料,标注样本少”的问题,其用武之地,就是推荐系统的debias
-
在主任务之前预训练,或者,与主任务共同训练。 -
让Embedding/Encoder层,多多见识一些平常在log里面不常见的少数人群和小众物料。让平常听惯了“ 阳春白雪”的模型,也多多感受一下“ 下里巴人”。 -
因为在训练阶段与少数人群与小众物料都“亲密接触”过了,这样的模型线上预测时,会少一份势利,对少数人群与小众物料友好一些。 -
其实也算是一种对少数样本的regularization。
如果明确了对比学习的目标是为了debias,那么有两点是值得我们注意的
-
参与对比学习的样本,和参与主任务的样本,必然来自不同的样本空间 -
主任务,需要拟合U~I之间的真实互动,还是以log中的已经曝光过的user/item为主。 -
而对比学习,既然是为了debias,必然要包含,而且是 多多包含鲜有曝光机会的少数人群和小众物料。 -
主任务与对比学习任务之间,一定存在Embedding或Encoder(某种程度)共享 -
近年来,给我的感觉, 参数共享、结构共享在推荐算法中,越来越不受待见。比如,多任务的场景下,同一个特征(e.g. userId, itemId)对不同目标,需要有不同embedding;再比如,阿里的Co-Action Net通篇都在讲参数独立性,同一个特征与不同特征交叉时,都要使用不同的embedding。 -
但是,对于对比学习,(某种程度) 参数共享、结构共享,是必须的。否则,主模型与CL辅助模型,各学各的,主模型中的bias依旧存在,CL学了个寂寞。
对比学习在推荐场景下的正确姿势
正如前文所述,尽管对比学习当下很火,但是在推荐系统中的应用本来就不多,再刨除一些将向量化召回也包装成对比学习的跟风灌水文,有价值的好文章就更少了。今天我挑选两篇对我帮助非常大的两篇文章,简单与大家分享。
Google的《Self-supervised Learning for Large-scale Item Recommendations》
讲推荐场景下的对比学习,我首推2021看Google的《Self-supervised Learning for Large-scale Item Recommendations》这一篇,正是此篇帮我树立了对CL的正确认识。这篇文章利用对比学习辅助训练双塔召回模型,目的是让item tower对冷门、小众item也能够学习出高质量的embedding,从而改善内容生态。
正如前文所述,读CL论文,重点是看其中的Data Augmentation部分。传统上,针对item的data augmentation,是采用Random Feature Masking (RFM)的方法,如下图所示。
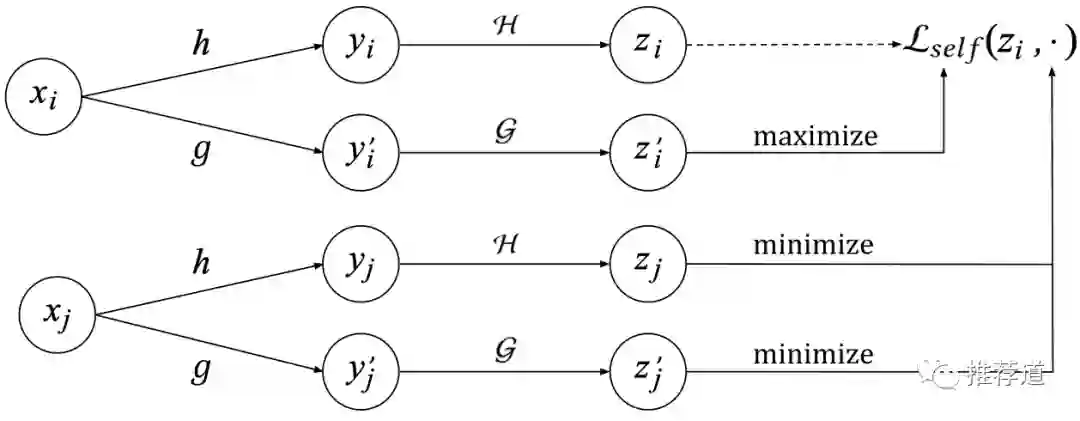
-
某个item , 随机抽取一半的特征h,得到变体 ,再经过Encoder H,得到向量 ;保留剩下的另一半特征g,得到变体 ,再经过Encoder G,得到向量 。 -
来自同一个item的两种变体对应的embedding 和 ,两者之间的相似度应该越大越好。 -
按照同样的作法,另一个item ,用一半特征h得到变体,再经过Encoder H得到 ;用另一半特征g,得到变体,再经过Encoder G得到 。 -
来自不同item的变体对应的embedding 和 (或 ),两者之间的相似度应该越低越好。
基于以上正负样本,整个对比学习辅助loss采用了Batch Softmax的形式,其实对于搞召回算法的同学来说,就非常常规了。(
是温度系数,N是batch size)
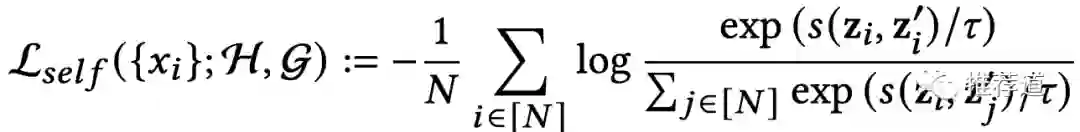
后续会提到,实际上H和G就是同一套结构与参数,同时也与主任务“双塔召回”中的item tower共享结构与参数。
但是,随机mask特征的data augmentation方法,存在问题。
-
这样容易制造出一些“脱离现实”的样本,比如一个变体中,我们保留了item作者的国籍是巴西,但是却缺失作品的语言?尽管这样的样本不能算离谱,但是毕竟对于模型来说,营养有限。 -
相互关联的两个特征,分别被拆分进两个变体中,比如“作者国籍”在h,“作品语言”在g。尽管看上去两个变体都是残缺的,但实际上所包含的信息(e.g., 作品受众)依旧是完整的。这两个变体的embedding太容易相似了,达不到锻炼模型的目的。
为了解决以上问题,Google的论文里面提出了Correlated Feature Masking (CFM)
-
首先,将任意两个特征 之间的互信息,离线计算好。(比如, 是作者国籍, 是语言, 是加拿大, 是法语)
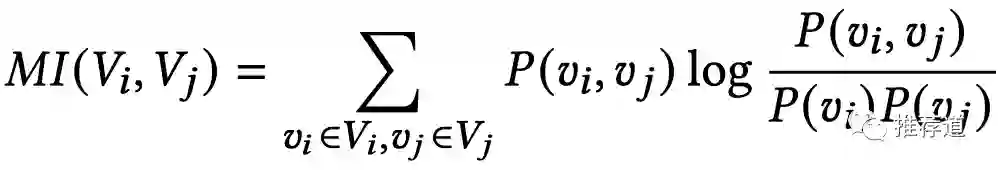
-
在训练每个batch时,随机挑选出一个种子特征 ,再根据离线计算好的互信息,挑选出与 关联度最高的n个特征(n一般取总特征数的一半),组成要mask的特征集 -
接下来的步骤就和常规CL步骤相同了,保留特征h= 构建一个变体,再拿剩下的一半特征g,构建另一个变体,两变体embedding要足够近。
除了提出Correlated Feature Masking (CFM)提升了变体的质量,Google的这篇论文还提出如下观点,值得我们注意并加以实践
-
Google原文还是拿CL当辅助任务与主任务(双塔召回)共同训练, 。但是作者也指出,在未来会尝试“ 先用CL pre-train,再用主任务 fine-tune”的训练模式。 -
整个item tower是被user~item双塔召回的主任务、对比学习辅助任务中的encoder H和G,这三者所共享的。这一点的原因前面也解释过了,CL在推荐系统中的目的,就是为了减轻主模型对long-tail user/item的偏见,如果各学各的,CL学了个寂寞,就变得毫无意义。
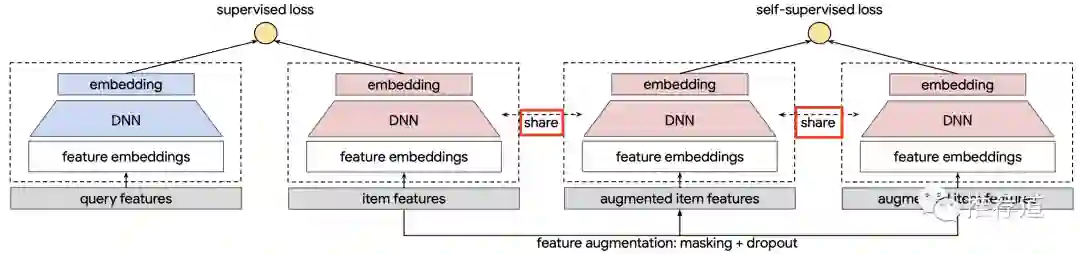
-
Google的论文里特别指出,召回主任务中的item主要还是来自曝光日志,因此还是偏头部item。而为了达到debias的目的,CL辅助任务中的item必须采用与主任务完全不同的分布, "we sample items uniformly from the corpus for "。事实上,在我看过的CL in Reco多篇论文中,Google的这篇论文是唯一一篇明确指出了样本分布对CL的重要性," In practice, we find using the heterogeneous distributions for main and ssl tasks is critical for SSL to achieve superior performance"。
阿里的《Disentangled Self-Supervision in Sequential Recommenders》
上一篇文章介绍的是针对item的data augmentation,而对于user来说,最重要的特征就是用户的交互历史,因此针对用户历史的data augmentation,就是影响针对user对比学习成败的重中之重。在我的《用统一框架理解向量化召回》一文中,就提到过一种利用孪生网络来构建U2U召回的方法:将用户历史序列,随机划分为两个子序列,各自喂入双塔的一边,训练要求两塔输出的embedding越相似越好。现在看来,这种作法实际上就是在做对比学习。
阿里的这篇文章针对的是sequentail recommender问题,即输入用户历史序列,预测下一个用户可能交互的item,因此seq-2-item是预测的主任务。同时,这篇论文里提出了类似“孪生网络”的方法训练seq-2-seq辅助任务,只不过有两点改进:
-
从用户完整历史中提取出两个子序列,不再是随机划分,而是按照时序划分。 而且为了建模时序关系,后一个子序列,还使用了倒序。 -
为了显式建模用户的多兴趣,Encoder不再将用户序列压缩成一个向量,而是提取出K个向量。 -
因此正例变成了,同一个用户,从他的前一段历史提取出的第k个兴趣向量,与从他后一段历史提取出的第k个兴趣向量,距离相近 -
负例扩展成,除了不同用户的兴趣向量相互远离,同一个用户的不同类别的兴趣向量,距离也要足够远。
对比学习公式如下。 代表用户在t时刻之前的历史, 是t时刻之后用户历史; 是负责从用户历史中提取第k个兴趣向量的encoder。
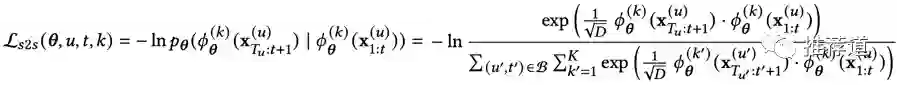
剩下的一些技术细节,比如显式地学出K个不同的兴趣向量比压缩成一个向量能提升多少、时序的分裂点t是随机的还是固定成一半的位置、......,我觉得都不重要,在阿里场景下取得的收益是否能够在你的场景下复现,就留待GPU和AB平台告诉我们答案了。
总结
本文也算是紧跟“对比学习”燎原之势的跟风应景之作,但是自认为还是有点干货的,而并非仅是别人成就的综述
-
谈了我对对比学习的理解,特别是厘清了与向量化召回算法的重要区别。尽管底层很多技术是通用的,但是 对比学习与向量化召回,是形似神不似。对比学习作为Self-Supervised Learning的一种,毕竟针对的是“少标注或无标注”问题,Data Augmentation是其核心,在推荐场景下往往作为辅助任务出现。有鉴于此,同学们日后再看到拿对比学习包装向量化召回的水文,一定要擦亮眼睛。 -
指出 对比学习在推荐系统中的用武之地,就是debias, 让平常听惯了主流人群&物料的“阳春白雪”的模型,也多多感受一下非主流人群&物料的“下里巴人”。为了达到debias的目的,要求我们在实践对比学习时,从 样本分布、参数共享、训练模式等方面要多加注意。 -
CL in Reco领域的好文不多,我分析了Google和阿里的两篇文章,感受一下正确姿势。特别是Google那一篇,推荐每个有意在推荐系统实践对比学习的同学,都仔细阅读一遍。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


