将对比学习扩展到监督式场景


发布人:Google Research 高级软件工程师 AJ Maschinot 及产品经理 Jenny Huang
近几年,得益于对比学习的应用,常用于各种图像和视频任务的自监督式表征学习取得了显著发展。这些对比学习方法通常会对模型进行训练,使其将嵌入向量空间中的目标图像(即“锚点”)的表征和匹配(“正类”)图像聚集在一起,并将锚点从多个非匹配(“负类”)图像上分开。因为假定标签在自监督式学习中不可用,所以正类通常是锚点的增强,而负类则为训练小批量的其他样本。不过,由于采用了这种随机采样,假负类(即从同类样本中作为锚点生成的负类)可能会降低表征质量。此外,如何确定生成正类的最好方法仍是一个热门研究领域。
对比学习
https://arxiv.org/abs/2002.05709
自监督式表征学习
https://arxiv.org/pdf/2011.00362.pdf
降低
https://arxiv.org/abs/2011.11765
与自监督式方法不同,全监督式方法可使用现有标签数据从现有的同类样本中生成正类,与仅通过增强锚点来实现的常用方法相比,这能在预训练流程中增加可变性。不过,在全监督式领域中顺利应用对比学习方面,人们仅开展了极少工作。
在 2020 年 NeurIPS 大会上发表的“监督式对比学习” (Supervised Contrastive Learning) 中,我们提出了一个新的损失函数 SupCon。该函数可缩短自监督式学习与全监督式学习之间的差距,并实现对比学习在监督式场景中的应用。SupCon 利用已加标签的数据,既能聚集来自同类的归一化嵌入向量又能区分来自不同类的嵌入向量。这可简化正类选择的流程,同时避免潜在的假负类。由于这种方法中的每个锚点都有多个正类,所以其可以更好地选择更多样化的正类示例,同时仍包含语义上相关的信息。与限制标签信息并仅将其用于下游训练(如传统对比学习用例)相比,SupCon 还能促进标签信息在表征学习中发挥积极作用。据我们所知,与使用交叉熵损失来直接训练模型的这一常见方法相比,SupCon 是首个能够在大规模图像分类问题中对比损失持续实现更佳性能。重要的是,SupCon 能简易地在训练中执行并保持稳定,可对各种数据集和架构(包括 Transformer 架构)的 top-1 准确率进行持续、稳定的改进,不受图像损坏和超参数变化的影响。
监督式对比学习
https://arxiv.org/abs/2004.11362
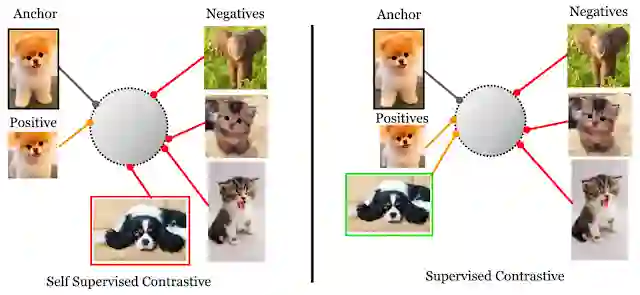
自监督式(左)与监督式(右)对比损失:自监督式对比损失会对各锚点的单个正类(即相同图像的增强版本)与包含小批量整个剩余部分的负类集合进行对比。而此论文中探讨的监督式对比损失则会对同类中归为正类的所有样本集与批量剩余部分中的负类进行对比

SupCon 可视为对 SimCLR 和 N 配对损失的概括,前者使用将相同样本中生成的正类用作该类锚点,而后者通过利用已知的类标签来从不同样本中使用生成的正类。对每个锚点使用多个正类和负类可确保 SupCon 实现更佳性能,而无需执行难以正确调整的困难负类挖掘(即搜索与锚点相似的负类)。

SupCon 包含文献中的多个损失,并且是 SimCLR 和 N 配对损失的概括
这种方法在结构上类似于自监督式对比学习,并针对监督式分类进行了修改。考虑到数据的输入批次,我们首先应用两次数据增强,为该批次中每个样本获得两份副本或“视图”(但可创建并使用任意数量的增强视图)。两份副本都会通过编码器网络向前传播,随后生成的嵌入向量便完成 L2 归一化。根据标准做法,表征将通过可选投影网络进一步传播,从而帮助确定有意义的特征。监督式对比损失将根据投影网络的归一化输出进行计算。锚点的正类包含作为锚点从相同批次实例中生成的表征,或作为锚点从具有相同标签的其他实例中生成的表征,而负类则是所有剩余实例。为了测量下游任务性能,我们基于冻结表征对线性分类器进行训练。
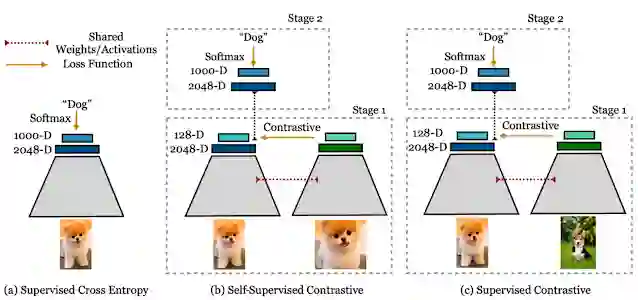
交叉熵自监督式对比损失与监督式对比损失左:交叉熵损失使用标签和 softmax 损失来训练分类器。中:自监督式对比损失使用对比损失和数据增强来学习表征。右:监督式对比损失不仅使用对比损失来学习表征,还使用标签信息来进行正类采样和增强相同图像
在 CIFAR-10 与 CIFAR-100 以及 ImageNet 数据集中,较之交叉熵、边距分类器 (Margin classifier)(使用标签)以及自监督式对比学习技术,SupCon 能持续提升 top-1 准确率。利用 SupCon,我们能在采用 ResNet-50 与 ResNet-200 架构的 ImageNet 数据集上实现极高的 top-1 准确率。在 ResNet-200 上,我们可实现 81.4% 的 top-1 准确率,较之使用相同架构的一流交叉熵损失提高了 0.8%(这对 ImageNet 而言可谓显著进步)。我们还在基于 Transformer 的 ViT-B/16 模型上对交叉熵和 SupCon 进行了对比,发现在相同的数据增强模式(未进行任何更高分辨率微调)下,改进效果(ImageNet 上的结果:77.8% 与 76%;CIFAR-10 上的结果 92.6% 与 91.6%)均高于交叉熵。
CIFAR-10 与 CIFAR-100
http://www.cs.toronto.edu/~kriz/cifar.html
显著进步
https://paperswithcode.com/sota/image-classification-on-imagenet
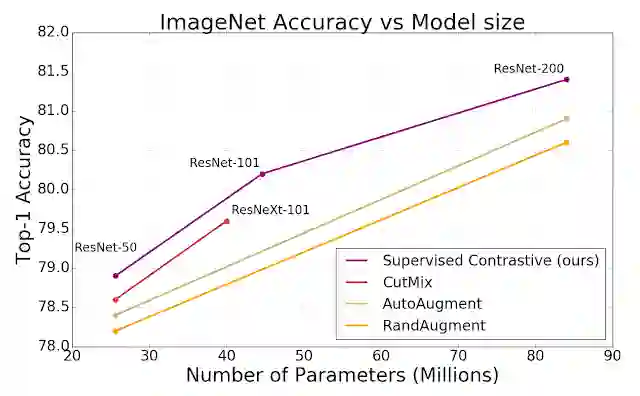
在采用标准数据增强策略(AutoAugment、RandAugment 和 CutMix)的情况下,SupCon 损失的性能始终优于交叉熵损失。我们不仅在 ResNet-50、ResNet-101 和 ResNet200 上展示了 ImageNet 的 top-1 准确率
我们还通过分析表明了损失函数的梯度可促进对困难正类和困难负类的学习。困难正类/负类可较大程度影响梯度,而简单正类/负类对坡度的影响则较小。这种隐式属性可帮助对比损失省去显式困难挖掘的麻烦,这也是许多损失函数(例如三元组损失)中一个微妙但关键的部分。如需了解所有派生,请参阅我们论文的补充材料。
我们论文
https://arxiv.org/abs/2004.11362
SupCon 也能更加稳定地应对噪音、模糊和 JPEG 压缩等自然损坏。平均损坏错误 (mCE) 可测量与基准 ImageNet-C 数据集相比的性能平均降低水平。与交叉熵模型相比,SupCon 模型在不同损坏中的 mCE 值更低,这表明其稳定性更佳。
ImageNet-C
https://github.com/hendrycks/robustness
我们通过实验证明,SupCon 损失对超参数范围的敏感性低于交叉熵。在增强、优化器和学习率变化方面,我们发现对比损失输出中的差异显著较小。此外,应用不同批次大小,同时保持其他所有超参数恒定,可使 SupCon 在每个批次大小中持续实现比交叉熵更高的 top-1 准确率。
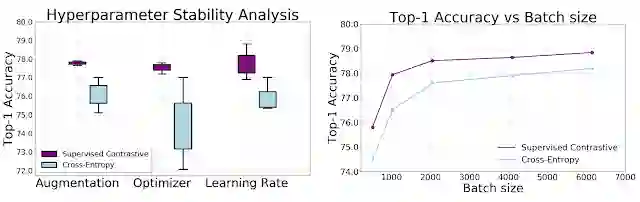
交叉熵和监督式对比损失作为超参数和训练数据大小的函数时,在采用 ResNet-50 编码器的 ImageNet 上测得的准确率;左:箱形图中显示 top-1 准确率与增强、优化器和学习率变化的对比,SupCon 在不同变量各项中的表现更为一致,这在最佳策略尚属未知先验时十分有帮助;右:将 top-1 准确率作为批次大小函数表明两种损失都可受益于较大的批次大小,而 SupCon 的 top-1 准确率更高,即便使用小型批次大小进行训练也是如此
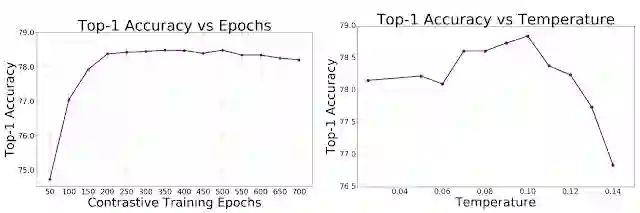
监督式对比损失作为训练时间和温度超参数的函数时,在采用 ResNet-50 编码器的 ImageNet 上测得的准确率;左:top-1 准确率作为 SupCon 预训练周期函数;右:top-1 准确率在 SupCon 预训练阶段作为温度函数;在对比学习中,温度是重要的超参数,并且最佳做法是降低对温度的敏感度
这项研究为监督式分类领域带来了技术进步。监督式对比学习能在简单的情况下,提高分类器的准确率和稳定性。传统的交叉熵损失可视为 SupCon 的特例,其中视图对应于图像,最终线性层中训练的嵌入向量则对应于标签。我们发现,SupCon 可受益于大型批次大小,并且在小批次上提升训练模型的能力也是未来探究的重要主题。
我们的 Github 代码库中提供了论文中用于训练模型的 TensorFlow 代码。我们也在 TF Hub 上发布了经预训练的模型。
我们的 Github 代码库
https://github.com/google-research/google-research/tree/master/supcon
发布了
https://hub.tensorflow.google.cn/s?publisher=google&q=supcon
NeurIPS 论文由 Prannay Khosla、Piotr Teterwak、Chen Wang、Aaron Sarna、Yonglong Tian、Phillip Isola、Aaron Maschinot、Ce Liu 和 Dilip Krishnan 共同撰写。特别感谢 Jenny Huang 负责本博文的编写工作。

推荐阅读

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看


