Nature子刊:最先进的人工神经网络离人类水平还有多远?

新智元报道
【新智元导读】人工神经网络(ANN)和大脑有着许多相似的地方,那么ANN到底从动物大脑中学到了什么呢?Nature Communications近期发布了一篇文章便对此问题进行了讨论。研究人员认为,机器与生物的工作原理不同导致二者不可能做到高度相似。

在监督学习中,数据成对组成——一个输入项(如图像)和它的标签(如单词“giraffe”)——目标是找到为新的pair生成正确标签的网络参数。
在无监督学习中,数据没有标签;目标是在没有明确指导的情况下发现数据中的统计规律。例如,我们可以想象,有了足够多的长颈鹿和大象的样本,我们可能最终推断出这两类动物的存在,而不需要明确地给它们贴上标签。
最后,在强化学习中,数据被用来驱动行为,这些行为的成功与否是基于一个“奖励”信号来评估的。
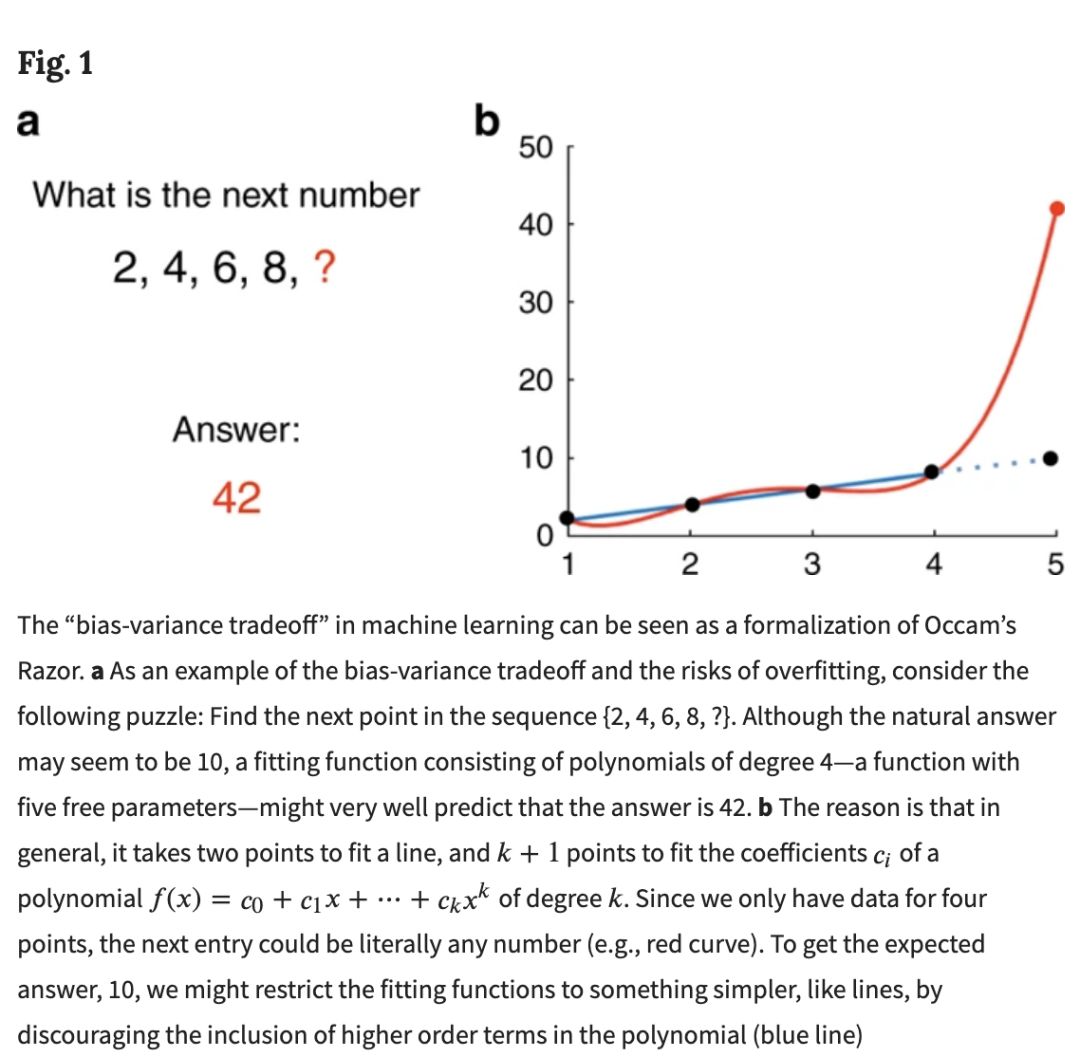
动物的学习和天生行为
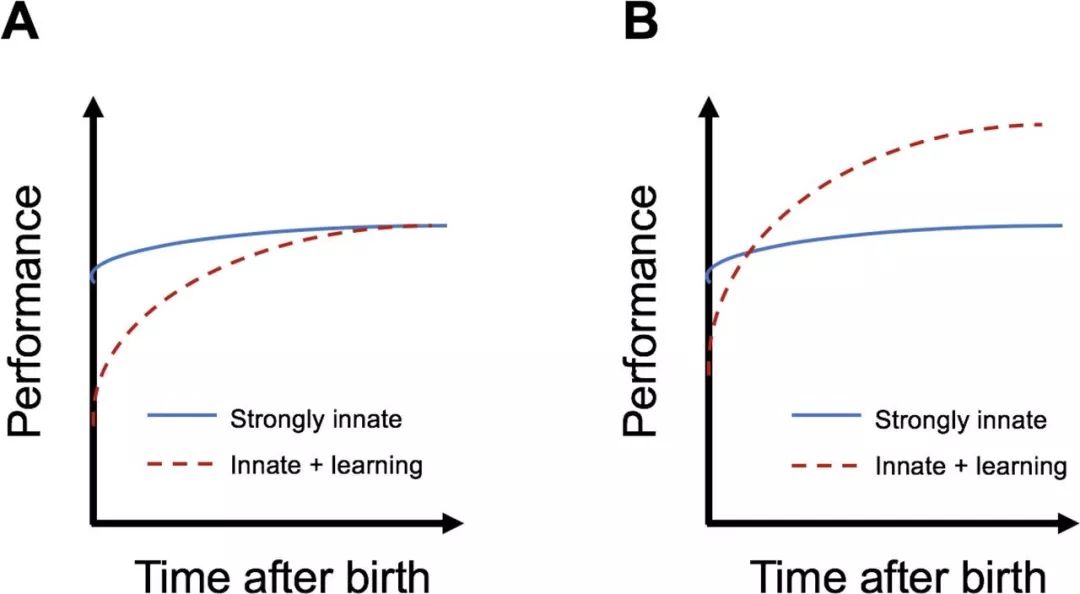
结论

登录查看更多
相关内容

人工神经网络(Artificial Neural Network,即ANN),它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
专知会员服务
20+阅读 · 2020年5月14日
Arxiv
7+阅读 · 2019年11月13日
Arxiv
34+阅读 · 2019年10月24日
Arxiv
3+阅读 · 2018年5月2日
Arxiv
5+阅读 · 2018年3月13日



相关VIP内容
专知会员服务
20+阅读 · 2020年5月14日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年11月13日
Arxiv
34+阅读 · 2019年10月24日
Arxiv
3+阅读 · 2018年5月2日
Arxiv
5+阅读 · 2018年3月13日