解码大脑信号直接合成语音,Nature新研究拯救失语者
机器之心报道
机器之心编辑部
为了让失语者开口「说话」,神经科学家设计了一种可以将大脑信号转换为语音句子的设备。这项研究发表在4月24日的Nature期刊上。
许多失去说话能力的人需要利用某种技术进行交流,这项技术要求他们做出微小的动作来控制屏幕上的光标,进而选择单词或字母。最著名的例子就是霍金,他使用的是一种利用脸颊肌肉激活的发声装置。但是由于使用者必须逐个字母打出自己要说的话,这种装置通常速度很慢,每分钟最多生成十个单词,而正常说话者每分钟平均要说 150 个词,而这主要归功于人类的声道。
近日,来自加州大学旧金山分校的研究者发表了一项研究,他们设计了一种将大脑信号转换为语音的设备,其原理为:将大脑活动映射到声道发音运动进而转换为声音。圣地亚哥州立大学神经科学家 Stephanie Riès 表示,用这种方法创建出的语音比直接将大脑活动映射为声音更加易于理解。
先来一段音频感受一下:
音频中包含两个句子示例,每个句子第一遍由参与者朗读,第二遍是利用该技术通过参与者的大脑信号合成出的语音。从音频中可以听出,这项技术已经可以合成完整的句子。但目前来看,该技术还不够准确,无法完全脱离实验室环境。
埃默里大学神经工程研究者 Chethan Pandarinath 表示,在此之前,科学家仅能利用 AI 将大脑信号转换为单词,而且这些单词通常仅包含一个音节。「从单音节词到句子的飞跃技术难度非常大,这也是这项技术令人印象深刻的原因所在。」
将大脑活动映射到发音运动

研究者将类似的电极植入参与者的头骨以记录他们的大脑信号。图源:UCSF。
研究者将电极植入五名参与者的大脑表面,作为癫痫疗法的一部分。首先,该团队在参与者大声朗读数百个句子时记录他们的大脑活动,然后将这些记录与之前测定发声时舌头、嘴唇、下巴和喉部运动的实验数据结合起来。
该团队基于这些数据训练了一种深度学习算法,然后将该程序集成到解码器中。该设备将大脑信号转换为对声道发音运动的估计,然后将这些运动转换为合成语音。Chang 表示,听了 101 个合成句子的听众平均能够理解其中 70% 的单词。
在另一项实验中,研究者请一名参与者大声朗读句子,然后再只张嘴不出声地默读同样的句子。Chang 表示,在只动嘴不出声的情况下合成的句子质量比基于有声语音创建的句子质量要低,但结果仍然令人振奋。
解码器设计
这一新型解码器共分为两个阶段,如图 1 所示。
第一阶段(见图 1a–b):将大脑信号转换为声道发音运动。使用双向 LSTM 循环神经网络将连续的神经活动解码为声道发音运动特征。
第二阶段(见图 1c-d):将声道发音运动转换为合成语音。使用双向 LSTM 将第一阶段获得的声道发音运动特征解码为声学特征(图 1c),然后将声学特征合成为语音。
解码器的一个关键组成是中间发声表示(见下图 b)。这一步非常重要,因为 vSMC 在语音合成期间表现出稳健的神经激活,语音合成期间主要编码发音运动。由于连续语音的发音追踪在该研究的临床环境中并不可行,因此研究者利用一种统计方法根据声音记录来估计声道运动轨迹(嘴唇、舌头和下巴的运动)以及其他生理特征(如发声方式)。这些特征初始化了语音编码器-解码器中的瓶颈层,训练该编码器-解码器的目的是重建参与者的言语声学。然后用编码器来推断用于训练神经解码器的中间发声表示。利用这种解码策略,可以准确地重建语音频谱。
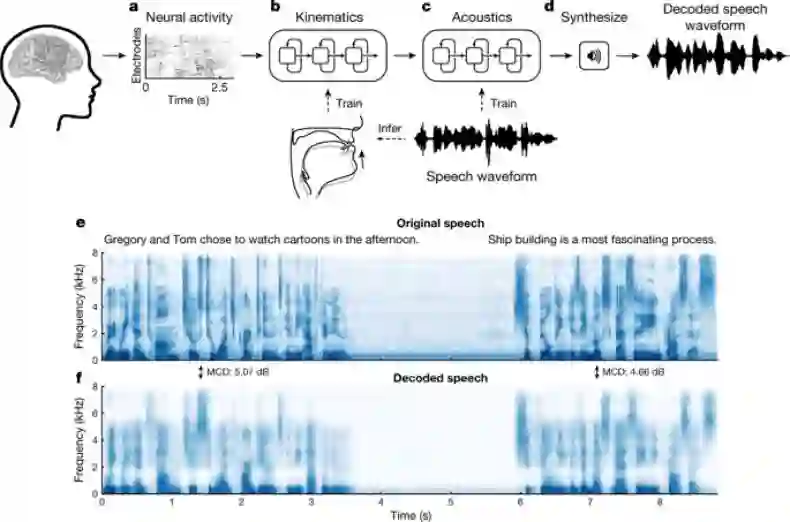
图 1:从神经信号中合成语音。
语音合成性能
该研究作者、加州大学旧金山分校神经外科医生 Edward Chang 表示,使用该方法后,听了 101 个合成句子的听众平均能够理解其中 70% 的单词。
具体性能见下图,其中 b 展示了每个句子的平均词错率(WER)分布情况。
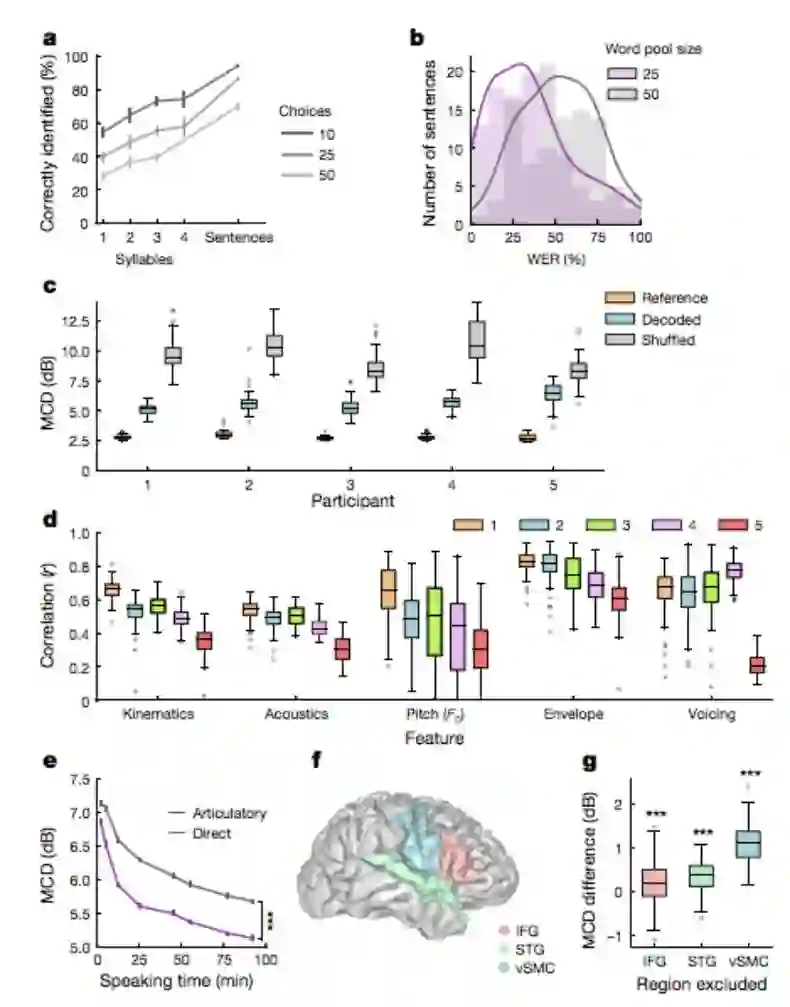
图 2:合成语音的被理解程度,及其针对特定特征时的性能。
下表展示了听众在一定词错率范围内的转录文本:

为了验证解码器是否依赖参与者的语音,研究者进行了一项对比实验:研究者请一名参与者大声朗读句子,然后再只张嘴不出声地读同样的句子。结果表明,后者的合成语音频谱与前者具备相似的频谱曲线。
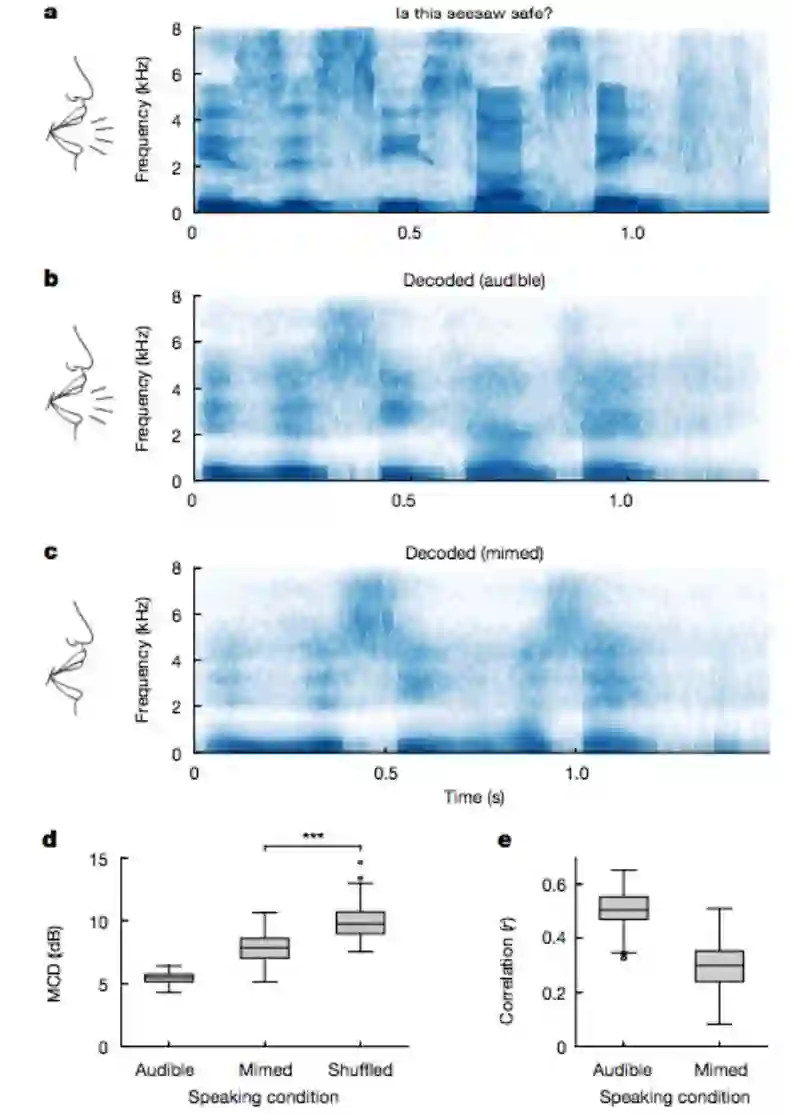
图 3:只动嘴不发声的情况下,该方法的语音合成结果。
方法局限
华盛顿大学神经工程研究者 Amy Orsborn 认为,目前尚不清楚这一新型语音解码器是否能够处理人们脑海中的词汇。「这篇论文很好地证明了该方法适用于动嘴不出声的情况,但是当一个人没有动嘴时,它能否理解其想说的话呢?」
美国西北大学神经学家 Marc Slutzky 同意这种观点,并认为该解码器的性能仍有改进空间。他指出,听众现在是通过从一组词中进行选择来识别合成语音,随着词数量的增加,人们在选择准确词汇上会更加困难。
这项研究「是非常重要的一步,但距离轻松理解合成语音还有很长的路要走。」Slutzky 表示。
论文:Speech synthesis from neural decoding of spoken sentences

论文链接:https://www.nature.com/articles/s41586-019-1119-1
摘要:将神经活动转换成语音的技术对于因神经系统损伤而无法正常交流的人来说是革命性的。从神经活动中解码语音难度很大,因为说话者需要对声道发声部位进行非常精准、快速的多维度控制。本研究设计了一个神经解码器,显式地利用人类大脑皮层活动中编码的运动表示和声音表示来合成语音。首先用循环神经网络直接将记录的大脑皮层活动解码为发音运动的表示,然后将这些表示转换为语音。在封闭的词汇测试中,听众可以识别和转录出利用大脑皮层活动合成的语音。中间的发音动态即使在数据有限的情况下也能帮助提升性能。解码后的发音运动表示可被「说话人」极大地保存,使得解码器的组件可在不同参与者之间迁移。此外,该解码器可以在参与者默念句子时合成语音。这些发现提升了使用神经假体技术恢复交流能力的临床可行性。

原文链接:https://www.nature.com/articles/d41586-019-01328-x
本文为机器之心报道,转载请联系原公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





