人工神经网络是否模拟了人类大脑?
本文作者Harold Yue,原载于知乎,数说工作室经授权发布。
链接:https://www.zhihu.com/question/59800121/answer/184888043
我是生物本科,认知神经科学研究生在读,课余时间比较喜欢编程和机器学习,正在自学,了解的稍微多一些。我试着从我的角度来说下我看到的深度学习和神经科学的联系。
深度学习和神经科学这两个学科现在都很大,我的经历尚浅,如果大家发现哪里说得不太对,欢迎提出指正,谢谢!
那我们就自底往上说。
1、神经元
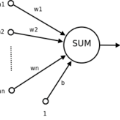
在深度学习领域,神经元是最底层的单元,如果用感知机的模型, wx + b, 加上一个激活函数构成了全部,输入和输出都是数字,研究的比较清楚,别的不说,在参数已知的情况下,有了输入可以计算输出,有了输出可以计算输入。
但在神经科学领域,神经元并不是最底层的单位,举例来说,有人在做神经元膜离子通道相关的工作。一个神经元的输入,可以分为三部分,从其他神经元来的电信号输入,化学信号输入,还有编码在细胞内的信号(兴奋,抑制类型,这里可以类比为 激活函数?),输出也是三个,电输出,化学输出,改变自身状态(LTP 长时程增强, LTD长时程抑制)。
我们是否足够了解神经元? 我个人十分怀疑这一点,前几天还看到一个关于神经元的进展,大意是神经元不仅能对单一信号产生反应,还能对一定一定间隔的信号产生反应。 神经元的底层编码能力其实更强。我们神经科学发展了这么久,可能真的连神经元都没真正的搞清楚。
在这另外说一句,深度神经网络里面,大部分节点都是等同的,但是在人类神经网络里面,并不是这样。不同的脑区,甚至脑区内部,神经元的形态都可以有很大的差异,如V1内部的六层就是基于神经元形态的区分。从这个角度,人类神经系统要更复杂一些。我个人并不否认每一种神经元可以用不同初始化参数的 节点来代替,但是目前来说,复杂度还是要比深度神经网络要高。
2、信号编码方式
再说编码方式,神经科学里面的神经元是会产生0-1 的动作电位,通过动作电位的频率来编码相应的信号(脑子里面的大部分是这样,外周会有其他形式的),而人工神经网络?大部分我们听到的,看到的应该都不是这种方式编码的,但是脉冲神经网络这个东西确实也有,(今天去ASSC 开会的时候看到了一个很有趣的工作,以后有空再写。)
神经网络的结构
目前的深度神经网络主要是三种结构,DNN(全连接的),CNN(卷积), RNN(循环)。还有一些很奇怪的, 比如说Attention 的?不好意思,文章还没看,不敢乱说……
放点图:
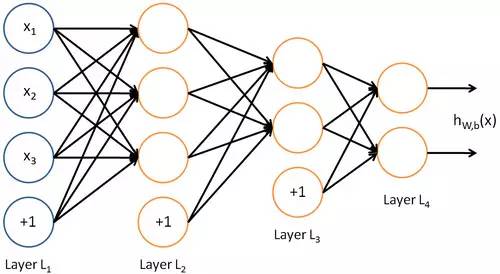
DNN:
CNN:
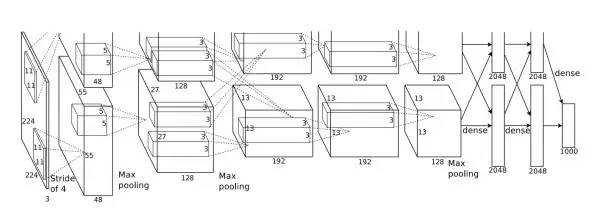
出处: AlexNet
RNN:
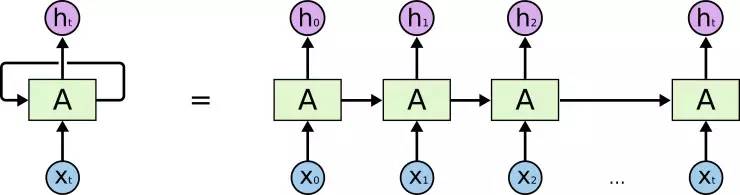
出处: Understanding LSTM Networks
神经科学里面的网络结构,此处以V1 为例:
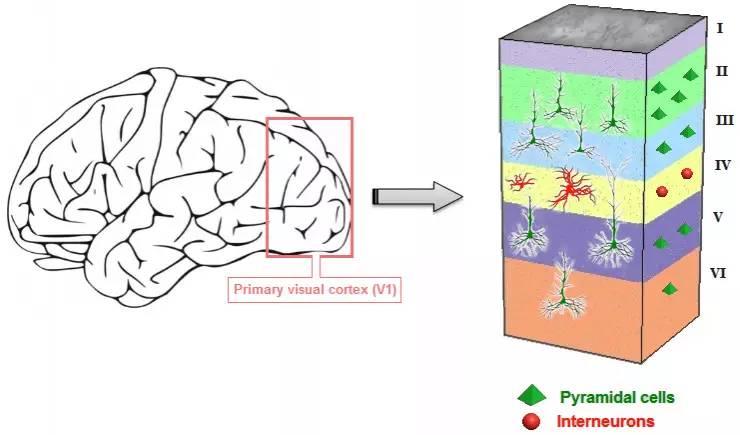
来源: Adaptation and Neuronal Network in Visual Cortex
和大家想的不同,视觉区分了V1,V2,V3,V4,V5(MT),上面还有FFA, 和一些掌管更高级功能的脑区。在这里面每一个小的视皮层里面,并不是纯由神经元互相连接构成的,仍然存在不同的层级结构。这里去google 找了一张图,不用管具体的文章,主要说明的是V1 的精细结构和连接关系。V1 的主要功能是识别点和不同角度的线段(Hubel 和W 在上世纪50年代在猫上的工作),但是其实不止如此,V1 还对颜色有一定的感知。
如果在这个层面作比较,我自己的理解是,人类神经网络是 DNN+ CNN + RNN 再加上脉冲作为编码方式。层内更像DNN, 层间和CNN 很类似,在时间上展开就是RNN。
好,我们继续。
3、训练方式:
深度神经网络的训练方式主要是 反向传播,从输出层一直反向传播到第一层,每一层不断修正出现的错误。但是大脑里面并没有类似反向传播机制,最简单的解释,神经元信号传递具有方向性,并没机会把信号返回上一层。举个例子,我要拿起手边的杯子,视觉发现向右偏移了一点,那我会自然而然的移动整个手臂向左一点,然后试着去重新抓住杯子。好像没人是让手指,手,最后是手臂朝杯子移动,甚至多次才能最后成功吧。在此引用下一篇文章里面的图。
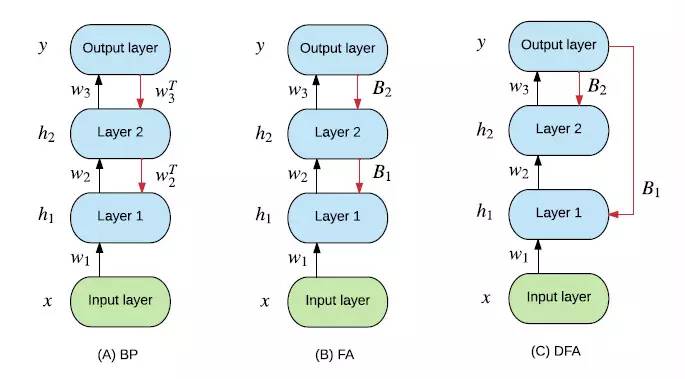
来源文章: Towards Biologically Plausible Error Signal Transmission in Neural Networks
我们的大脑,更像最后 DFA 的原理。出错了,把误差送到一个更靠近输入的地方,然后重新训练。
4、记忆和遗忘:
提到记忆的话,这里主要说的是LSTM, LSTM 的记忆储存在每个节点的权重里面,同时有专门的 遗忘门 控制遗忘速率。这些都是以数字的形式存储的。在神经系统里面,记忆的存储是由一些脑区的突触的形成和消失来存储的。其实他们有一个比较共通的地方在于,他们在训练过程中都是渐变的。得益于反向传播机制和 神经系统的生物性,他们在训练过程中和在不断的学习过程中都只能以一个相对慢的速度发生改变,从学习速率角度来讲,他们是比较相似的。
然后我们来说遗忘。遗忘在LSTM 里面是通过门来控制的,在神经系统里面,我觉得是和STDP相关的,它的基础是 Hebb 假说, Fire Together, Wire Together, 同步放电的神经元倾向于建立一个更强的连接。STDP 拓展了这一点,考虑了两神经元放电的先后顺序带来的影响。
简单来说,如果突触前神经元放电先于突触后神经元(神经元信号传导具有方向性,从突触前到突触后),这个突触会进入一个LTP 长时程增强状态,会对来自突触前的信号有更强的反应。反之,如果突触前神经元放电后于突触后,则会进入一个长时程抑制的状态(说明他俩并没有接收到相同来源的信号,信号不相关),一段时间的反应更弱。
深度神经网络里面门的权重也是 反向传播训练出来的,也有渐变的这个性质,当对于快速变化的刺激,有一定的滞后。从这个角度来说,人类神经系统要更灵活一些,可以在很短的时间内完成状态的切换。
觉得想说的大概就是这些,因为我自己做的研究是 视觉注意,更多在人身上做,所以对于中间的环路级别的研究,并不是特别的熟悉。再往上,谈到人类大脑皮层的工作,个人觉得做的十分的有限,对于大部分脑区,我们并不知道他们是怎么工作的,只是能把不同的脑区和不同的功能对应起来(还不一定准)。在这个角度上谈他们的异同是不太负责的,容易被打脸。
接下来我会试着邀请几个朋友来说下环路这个级别的事情,然后会找其他同行帮我挑错和补充。很多东西都是按照记忆写的,一些东西不一定准确。
5、观点总结
正如在提纲里面提到的。 对的答案往往类似,而错误的答案各有不同。地球上这么多高等的生命都有类似的底层网络结构,而其中的一种还发展出了这么伟大的文明,神经网络这个结构,至少已经被我们自己证明是一种有效的形式。但是是不是智能这个形式的全局最优解?我个人持怀疑态度。
神经网络是一个有效的结构,所以大家用这个结构做出一些很好的结果,我一定都不吃惊。但是如果谈模拟的话,就是尽力要往这个方向靠。这点上,我个人并不是十分看好这种方式。我们向蝙蝠学习用声音定位,发展的声呐无论是距离还是效果都远超蝙蝠。我们能超过蝙蝠的原因,第一是我们的技术有拓展性,底层原理共通的情况下,解决工程和机械问题,我们可以不那么轻松但是也做到了探测几千米,甚至几十公里。第二个原因就是我们需要而蝙蝠不需要,他们天天在山洞里面睡觉。哪用得着探测几十公里的距离,探到了也吃不着。
其实人类大脑也很类似,大脑是一个进化的产物。是由环境不断塑造而成的,人为什么没进化出计算机一样的计算能力,因为不需要。但是其实反过来也有一定的共通的地方,大脑里面的一些东西,我们也不需要,我们千百年来忍饥挨饿进化出的 对于脂肪摄入的需求,在儿童时期对于糖类摄取的需求。这么说的话,我们对于大脑,同样去其糟粕,取其精华不是更好吗?
我上面提到的是一个理想的情况,我们对大脑已经了解的比较透彻的,知道该去掉哪,留下哪。但是现在,可能还要走一段模拟的路子。
大概就是这个观点。 总结一下,就是, 深度神经网络和大脑皮层有共通的地方,但是并不能算是模拟。只是大家都找到了解题的同一个思路而已。
拓展阅读以及参考文献:
从科研到脑科学 - 知乎专栏
Understanding LSTM Networks
AlexNet:ImageNet Classification with Deep Convolutional Neural Networks
Towards Biologically Plausible Error Signal Transmission in Neural Networks
STDP: Synaptic Modification by Correlated Activity: Hebb's Postulate Revisited
《Python量化投资入门》来啦!
有这么一个 Python 培训课程,特点是:
从Python从入门到上手,手把手教你从安装到常用工具库的使用。
量化投资从基础到策略编写,手把手教你从获取数据到自动下单。
每位同学在课程结束后,都能有自己的策略并用Python实现自动交易。
课程中配套大量国内量化基金实际案例。
任何问题,可通过文字、语音、远程桌面等方式提问,老师亲自解答。
详细了解、试听课程:长按下图——「识别图中二维码」