人类:“共同探索围棋极限!”新AlphaGo:“不了吧,我到了。”
战胜你,与你无关,但最终是为了服务你。

5 月 27 日,端午节假期的前一天,少年棋手柯洁和 AlphaGo 的故事在乌镇结束了。
在过去的几天里,AlphaGo 战胜了当时这颗星球上最强的人类棋手。柯洁说:要专注于和人类下棋,不再和机器下棋了。
AlphaGo 的开发团队说:我们要专注于将 AlphaGo 的技术应用到其它领域,AlphaGo 也不会再和人类下棋了。
虽然更多的是唏嘘,但人类围棋界还是放下了心来。终于不用再和这个疯狂而变态的选手较劲了。
然而,5 个月后,AlphaGo 又有了新成果,这一次还是和围棋有关。如果说 AlphaGo 战胜柯洁是机器与人类的战争,那么这一次 AlphaGo Zero 的突破更像是某种客观规律的战争。
AlphaGo 似乎触摸到了围棋这一游戏的尽头。
自学成才的 AlphaGo Zero
AlphaGo 不是早就战胜人类了么?DeepMind 不是说不再让 AlphaGo 和人类下棋了吗?
没错,这一次 AlphaGo 的大新闻,确实和人类“没什么关系”。
DeepMind中AlphaGo项目组的主要负责人David Silver介绍,AlphaGo Zero目前已经是这个世界上最聪明的计算机棋手,它连续击败了此前战胜围棋世界冠军李世乭的 AlphaGo Lee 版本 100 次。
之所以以李世乭的版本作为对比而没有使用与柯洁对战的版本进行对比,是因为受到环境所限今年 5 月在乌镇与柯洁对战的 AlphaGo 其实是一个特殊的离线 AlphaGo Master 版本,仅由一个 TPU 在不连接网络的情况下完成对战。
无论是击败李世乭的版本还是击败柯洁的版本,过去的 AlphaGo 在“学习如何下棋”这个阶段,使用的都是大量的人类经典棋谱。它们被告知人类的高手在不同的情况下应该如何应对。而这一次的 AlphaGo Zero 在学习过程中完全没有使用任何人类的棋谱,它对玩法的探索完全是从自我对弈中学习的。
开始 AlphaGo Zero 会从非常随机且无厘头的下法开始进化,而它的陪练(另一个 AlphaGo Zero)的水平也很低。然后 AlphaGo Zero 会从每一场胜负中,取得经验,使得自己的奇艺水平不断提高。
David Silver说,很多人相信在人工智能的应用中算力和数据是更重要的,但在 AlphaGo Zero 中他们认识到了在当前,算法的重要性远高于算力和数据——在 AlphaGo Zero 中,团队投入的算力比打造上一个版本的 AlphaGo 少使用了一个数量级的算力。
使用了更先进的算法和原理,让 AlphaGo Zero 的程序性能本身更加优秀,而不是等待硬件算力技术的提升。
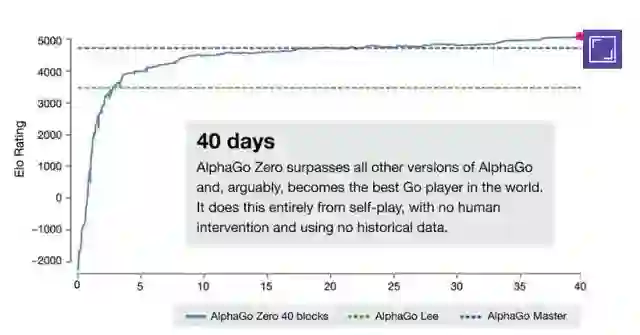
AlphaGo Zero 从零开始摸清围棋规则,就像是一个完全不会下棋的孩子。自我学习3天后,超过 AlphaGo Lee(战胜李世乭版本);21 天后,超过 AlphaGo Master(网络对战60:0版本);在训练 40天后,对弈双方相互交替持黑白棋的情况下,Zero 对 Master 胜率超过 90%。
在训练完成的 AlphaGo Zero 里,人们发现它自学成才的许多围棋打法与人类上千年来总结的知识是不谋而合的,比如打劫、征子、棋形、布局在对角等,都有人类围棋的影子。
所以人类棋手也不用伤心,这恰恰证明人类在过去的几千年里摸索出了围棋这一游戏的“自然规律”。而人工智能与人类棋手的对比就像是汽车和跑步。
每下一步仅需要思考是 0.4 秒的 AlphaGo Zero 所产生的美感与人类在紧张对弈时的美感是完全不同的,就像没有人会把F1方程式当赛跑比赛看一样。
那么,如何做到的?
祭出老图,我们先复习一下以前的 AlphaGo 是怎么工作的——

过去的AlphaGo每一棋的思考,分为两个界限清晰的步骤是:
1.获取棋局信息后,AlphaGo 会根据策略网络(policy network)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。这个过程得出的结果是概率分布,既棋盘上每个位置都有机会被选中,但客观情况下会有一个特定的区域拥有更高的概率。
2.根据上一步得出的概率分布,价值网络(value network)会对概率高的地区再进一步的判断,得出一个只有两个值的结果,每个落子位置要么被判定为会让自己赢,要么被判定为让对手赢。
在分配的搜索时间结束时,模拟过程中被系统最频繁考察的位置将成为 AlphaGo 的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,AlphaGo 的搜索算法就能在其计算能力之上加入近似人类的直觉判断。
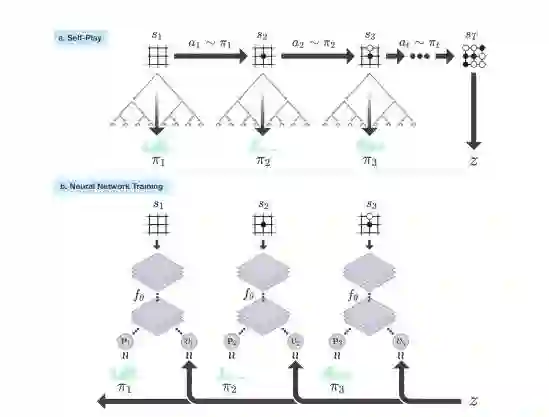
而新的AlphaGo在下棋时中并没有明显的策略网络与价值网络的分界,它将策略网络和价值网络设定为一个新的深层神经网络 fθ(s)= (p, v) 。其中 s 为棋盘位置,p 参数代表原本策略网络中代表落子概率,v参数代表落子后的胜率。
fθ(s) 同时对自己和对手的胜率进行预测,在每个位置 s,神经网络fθ都会进行一次计算。在其中一次对战获胜后,赢的一方所使用的 p 和 v 值将被作为参数调整进fθ。使得每一次对战后的 AlphaGo Zero 算法都在朝着可能存在的不败策略 fθ(s)=(π, z) 进发。
每次 AlphaGo 的新闻出来,总有读者问“如果两个 AlphaGo 对战会怎么样?”其实 AlphaGo 就是经过不断的自我对战实现了成长。
所以,有什么用?
“计算机下棋再强,有什么用?”
马云在今年曾经对 AlphaGo 提出过质疑,这确实也是许多普通吃瓜群众的质疑。计算机下棋,除了欺负柯洁弟弟之外确实没有什么用。但是,重要的是,在研究计算机解决围棋这一课题的过程中,DeepMind 的工程师在人工智能上产生了重要的突破。
论文发布一天后,David Silver 在 Reddit 回答网友关于 AlphaGo 后续版本的计划时表示,他们已经停止了对 AlphaGo 改进的研究计划,仅保留了研究试验台用于 DeepMind 研究人员去试验新的算法和思路。
这些突破可以广泛的应用到其它实际生产的领域,比如在去年7月份,DeepMind 就表示:如果全面推动 AI 实装到数据中心的话,最高可以达到 15% 的用电削减。
Deepmind 认为,这一次 AlphaGo Zero 上的突破能够让人工智能在一些缺少数据或数据异常昂贵的领域更好的发展,比如模拟蛋白质折叠研发新药、寻找新的化合材料等。
最重要的是,通过算法提升人工智能的效率,能够大幅减少对硬件“堆料”的依赖。如果你还不能理解人工智能如何减少数据中心电量的话,可以看一下这幅直观的对比图:
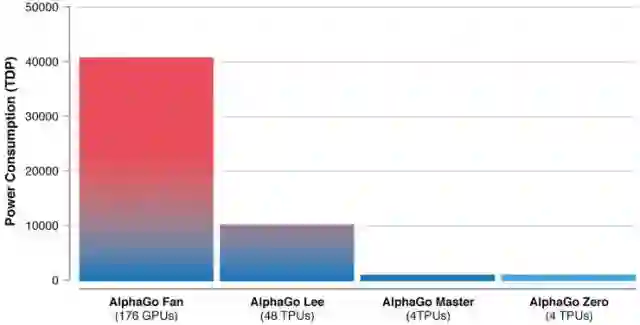
这是 AlphaGo 诞生以来四个版本的能耗对比,用一个与生活更息息相关的数字大概能让你理解这背后的价值。
2017 年,Google 公布了其在 2015 年全年的数据中心耗电情况,当时 Google 一年的用电量为 57 亿千瓦时,如果以北京这种高人均用电的大城市做对比,这相当于北京 712 万人的用电量。
在这样的数字上,仅仅是节省 10%,也能够对成本和环境造成巨大影响。
还有另一个对比可能让你理解人工智能对我们生活的改变。如果你是90年代生人,应该还记得在生物书上看到过那个“人类基因组计划”——对一个人的 23 对染色体进行全量测序。
这个耗时 13 年,耗资超过 10 亿美元,美国,中国,英国,日本,法国和德国6个国家20多所大学和研究机构完成的“世纪工程”。如今如果利用机器学习“再做一次”的周期大约为两周,成本大约为 2 万美金。而包括 Intel、华大基因、IBM 和 Google 等在内的新科技公司,正在力图在 2020 年把这个数字降到 24 小时,1000 美元。
而全量基因测序可以被认为是人类“攻克癌症”的重要一步,无论是在癌症的预防、筛查、优生还是对癌症药物的研究和治疗上,都会彻底改变现有癌症的现有诊疗方式。
这可能就是一群硅谷的高材生,要做出一条狗和围棋这个人类玩了上千年的桌面游戏较劲的原因吧。
更多活动详情,点击图片查看



