怎样让AI完成人类搞不定的任务?OpenAI提出迭代扩增法给AI设目标

李林 编译整理
量子位 出品 | 公众号 QbitAI
人类:AI啊,给北京设计一套不堵车的交通系统吧!
AI:想不堵车,只好……
想让AI去完成这种庞大复杂的任务,怎样训练、怎样指导,是个非常严峻的问题。
OpenAI今天提出了“迭代扩增”(iterated amplification),官方博客介绍说,这是一种AI安全技术,人类能运用这种方法,指导AI去完成那些人力不可及的任务。
简单来说,就是通过展示如何把任务分解成简单的子任务,让AI认清这个复杂任务的目标是什么、行为是怎样的。
这项技术,指向OpenAI成立之初就在讲的终极目标:让通用人工智能(AGI)更安全。

迭代扩增有什么用?要从如今AI常用的机器学习系统如何训练谈起。
训练一个机器学习系统,让它完成某种任务,需要人类提供训练信号,比如监督学习里的数据标签、强化学习里的奖励(reward),就都属于训练信号。
提供训练信号,对人类来说是一件说简单也简单,说难又很难的事情。这取决于想让AI学习什么样的任务。
让它识别手写数字,人类能认出这些数字标注出来就行;让AI玩游戏,人类会计算游戏得分、或者演示给AI看就行。而如果想让AI预测未来呢?
人类根本搞不定,训练信号更是无从提供起。要是提供错了,鬼知道AI会学出什么来……

迭代扩增就是用来给这类任务生成训练信号的。
这种方法基于这样两个条件:一是当人类遇到这种执行不了、或者无法判断完成情况的庞大复杂任务,起码还知道它能分解成哪些更小的部分;二是这些分解出来的小部分,人类还是可以完成的。
这样,就可以让人类去给这些小的子任务提供训练信号,然后把它们综合起来,指导总体任务。
当然,现在迭代扩增还没有用到人类无法解决的庞大任务上。为了测试这种方法,OpenAI先为它设置了五个小测验,分别是:
permutation powering
sequential assignments(顺序分配)
wildcard search(通配符搜索)
shortest path(最短路径)
union find(联合查找)





实验中,OpenAI的研究人员需要“假装不知道”这些任务应该怎样完成,不给机器学习模型提供完整的标注数据,而是将每一项任务分解成小的子任务,再为这些子任务提供训练信号,让AI间接地学习。
他们把通过迭代扩增和直接提供监督信号来训练的结果进行了比较,结果,在这5项任务上,通过迭代扩增来训练都获得了和直接使用监督学习差不多的效果。
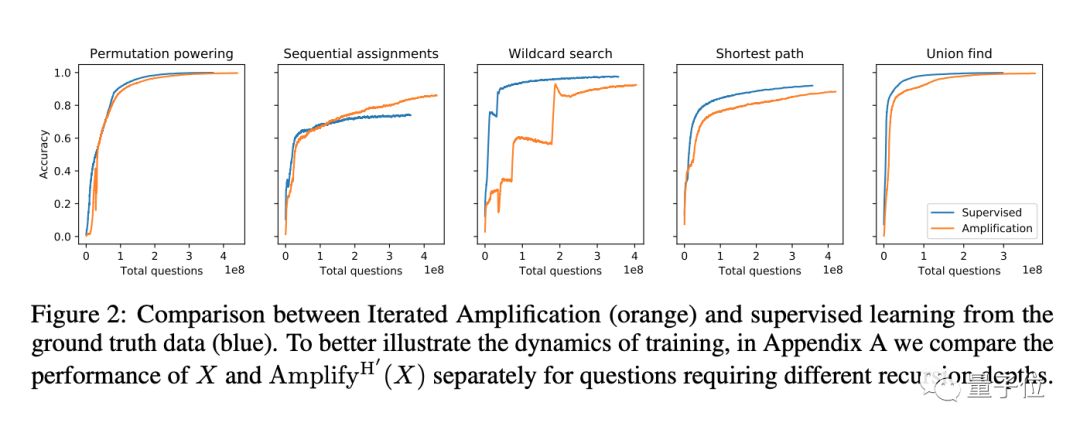
OpenAI说,他们计划将来用迭代扩增方法,来训练AI去实现人类搞不定的,真正的复杂任务。
看到这种方法,你可能会想到AlphaGo Zero中所用的专家迭代。它们有相似之处,也有很明确的区别:专家迭代增强的是一个已经存在的训练信号,而迭代扩增需要从头开始构建训练信号。
更多细节,都在这篇论文里:

Supervising strong learners by amplifying weak experts
https://arxiv.org/pdf/1810.08575.pdf




