【前沿跟进】Google, OpenAI提出层次强化学习新思路
文:CreateAMind陈七山
1前言:关于层次强化学习(HRL)
如何解决强化学习在反馈稀疏时的困难,一直是学界重点研究的方向。一种思路是采用层次化的思想 (Hierarchical Reinforcement Learning,简称HRL)。这并不是一个新兴的方向,20年前就有相关论文发表[1][2]。但由于始终没有达到理想的效果,所以最近各大机构如OpenAI, DeepMind, UCB都在进行这方面的研究,NIPS2017也有一个针对HRL的Workshop。
其中一个典型的工作是一篇MIT[3]的论文。当年DeepMind介绍QLearning玩Atari游戏的时候,着重介绍表现超过人类的打砖块等游戏,而在这个表的最底部,是一个Q-Learning得分为0的游戏,叫做Montezuma's Revenge。这个游戏的核心玩法在于,需要玩家先找到钥匙再开门,先找宝剑再打怪。为什么这个游戏对于Q-Learning非常困难呢?因为这个游戏的反馈(Reward)非常稀疏,只有在开门或者打怪成功之后才会得到奖励,这对于一个采取随机探索策略的模型来说,获得一次正反馈就如同大海捞针。
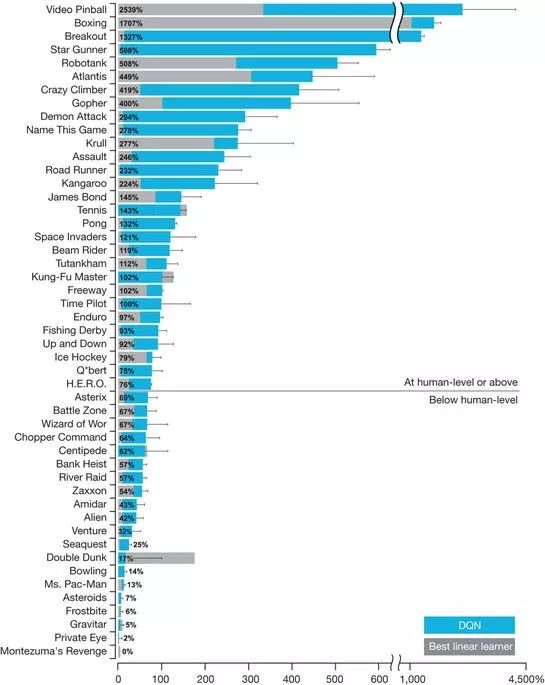

MIT的Joshua等人[3]则采用HRL的思想,成功将这个游戏玩到了较高的分数。他们的做法其实很简单,将游戏策略分为两层,上层(Meta Controller)负责处理先找钥匙再开门的逻辑,而下层(Skills)负责给定任意目标位置时,如何移动游戏角色到目标位置。训练时分开训练,先训练下层的Skills到收敛,再训练上层。测试时上下层统一起来,上层给下层发目标位置,下层移动游戏角色即可。这样分层后,相比于不分层直接探索,探索空间是极大地减小了,因此它能够成功得分并通过第一关。
虽然通关了这个游戏,但这样的HRL是并不理想的,因为这样的HRL并不具有通用性。对于每一个不同的任务,不同的游戏,它都需要人工制定好层次化结构与Skills的含义(如这里的找钥匙-寻路任务结构)。事实上,大多数HRL的论文其实都是人工指定并训练好Skills的,典型工作如HRL与模仿学习 (Imitation Learning)结合[4],以及用HRL玩Minecraft游戏[5]。
那么如何在训练过程中自动形成层次化结构(Skill Discovery)呢?这就引出了这篇文章的主要内容,关于层次强化学习(HRL)中的自动Skill Discovery思路。
Skills的定义主要能分为两种,一种是时间上的连续Action的抽象,另一种是具有实现子目标功能的模块(这里比较概括,后文会详细介绍)。接下来我就分两种Skills的定义,来介绍下两种不同的Skill Discovery的思路。
2作为连续Action抽象的Skill:MLSH
考虑一个马尔科夫决策过程 (MDP) 中的连续Action轨迹:a1, a2, a3 ... at。连续Action的抽象即是说,定义一个Skill,使用这个Skill就意味着输出这个Action序列:a1, a2, a3 ... at。自动学习连续Action的方法有使用类似EM方法的DDO[6],以及Meta-Learning Shared Hierarchies (MLSH)[7],接下来我着重介绍下MLSH的工作。
MLSH成功地实现了在模拟物理环境里,不仅让小蚂蚁能够爬行,而且还能够在迷宫内寻路:
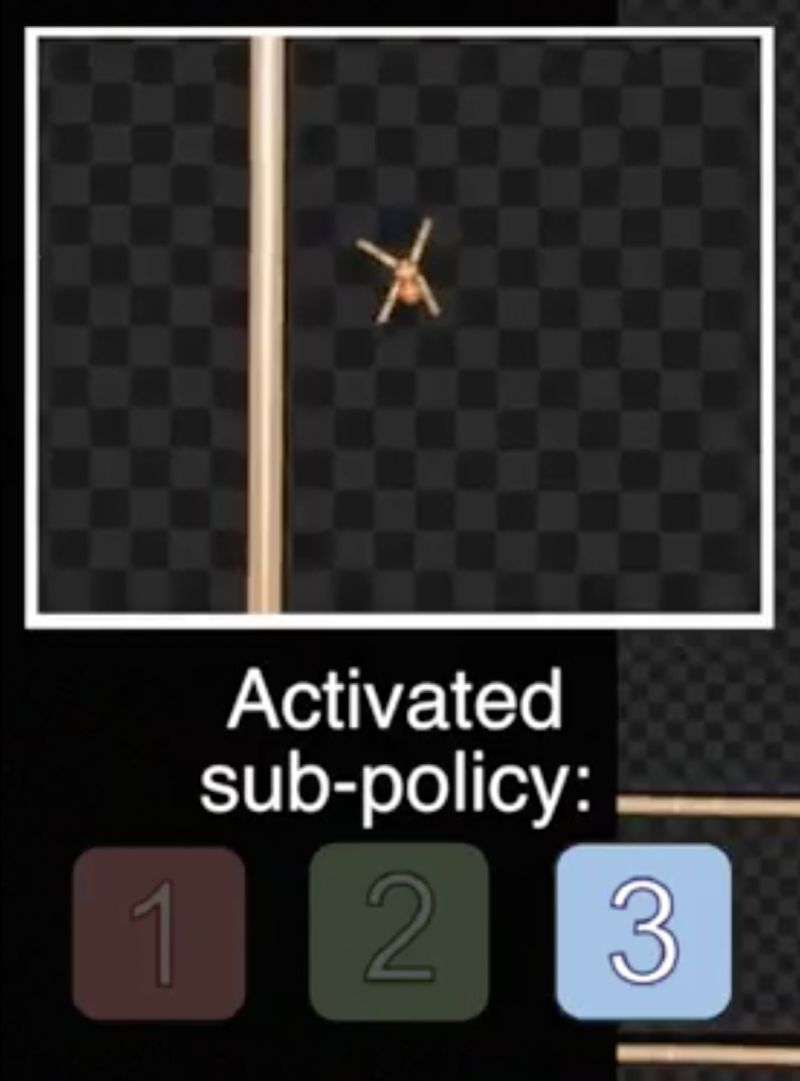
MLSH的整体结构是,如下图考虑一个两层的结构,上层的Policy(θ)输出Master-action选择输出下层Skills,下层的Skills(φ)输出真正的Actions。例如在蚂蚁的爬行任务中,Observation为地图和自身的位置,Actions为每一只脚的动作。通过一个两层的结构完成寻路任务并不算创新,MLSH的关键在于“Skills代表什么“是在过程中学习出来的。
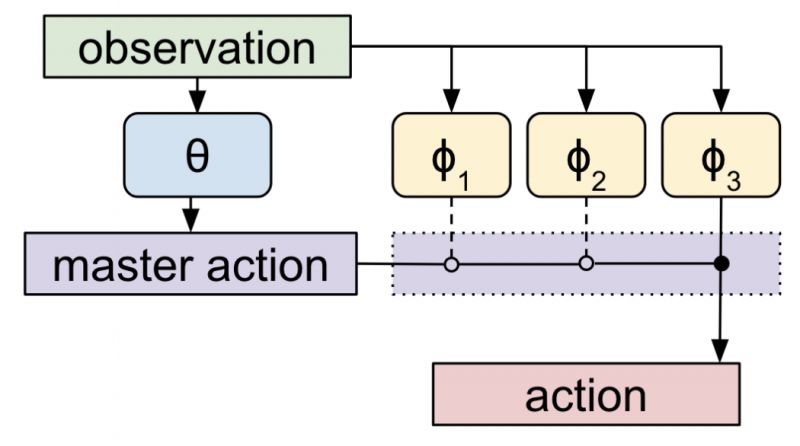
学习Skills的算法如下图所示,首先将Skills随机初始化,然后进入一个大循环,在循环中每次选择一个任务(有多个不同的任务)轮换训练上层Policy(θ)和联合训练下层Skills(φ)。值得注意的是,上层的Policy和下层的Skills观察到的时间尺度是不一样的,可以说是上层Policy只能观察到Skills执行前后的状态,而观察不到执行过程中的,这样做在时间尺度上形成了一个层次结构。

这个并不复杂的想法,为Skill Discovery提供了新的思路,并且也被成功应用到了真实的机械控制场景下[10],并相较于非Hierarchical的RL有更佳的表现。然而,文中的Skills虽然是模型自己学习得到的,但安排的任务顺序却是符合难度顺序和层次结构的(先学爬行再学寻路),这说明MLSH也不能说是"Meta"的通用Skill Discovery方法,还需改进。
3具有实现子目标功能的模块Skill:DE-HRL
Data-Efficient Hierarchical Reinforcement Learning(DE-HRL)[8]是一篇Google今年5月23日放在Arxiv上的文章,主要思想是上层生成子目标交给下层完成。该文章实际上是对Feudal Networks[9]的改进,使得模型可以Off-policy地训练,并去掉了Feudal Networks中的一些Tricks。
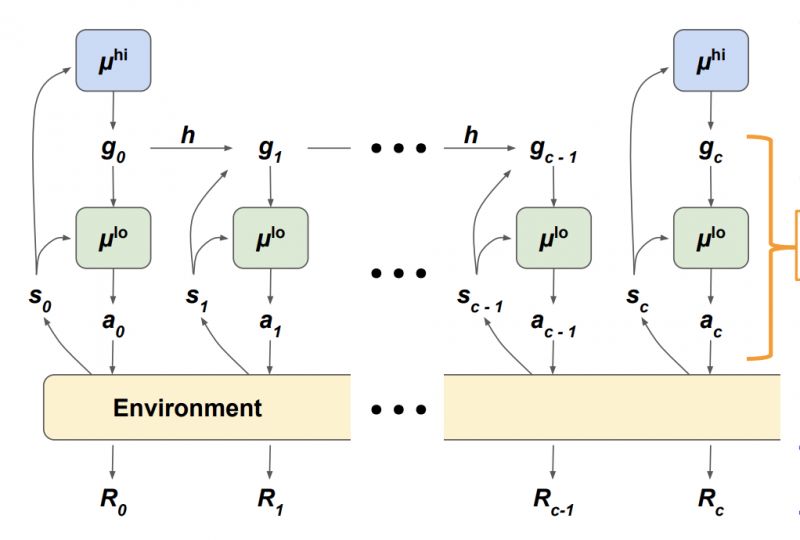
论文的主要思想如上图所示,首先从环境得到状态表示,高层μ(hi)在大时间尺度上作决策,低层μ(lo)在小时间尺度上做决策。高层决策时,生成一个目标交给低层,低层则不断通过Actions与环境交互去实现这个目标。图中的h是指的目标转移函数 (Goal Transition Function),定义如下:
举个例子,考虑一个2D平面中的寻路问题,S[t] = (2,3) 表示当前状态是在(2,3)位置,g[t]是(2,0)表示向右方向移动两格,而当Agent做出一个Action a[t]使得自己位置变为s[t+1] = (3,3)时,下一次的g[t+1] = h(s[t], g[t], s[t+1])为(1,0),就是说还需要向右移动一格。而这一步得到的Reward则设定为R[t] = -||h||,即是说 g[t+1]=h(s[t], g[t], s[t+1]) 越大,距离实现目标越远,Reward越小。训练过程如下图所示:

收集到Experience之后,使用Off-policy的方式分别训练高层和低层。低层的训练如图所示很明确了,高层的训练这里使用了一个目标重标记 (Goal Relabeling) 的Trick。因为考虑到在训练过程中,高层的数据来源并不是当前的低层,而是之前的低层,所以为了保持高低层训练的一致性,将目标重标记成最能够使得当前低层产生这些Actions的目标。
实验部分,文章搭建了一些更加复杂的环境,如下图所示,蚂蚁不仅需要学会爬行,还需要将红色方块向右推,以达到绿色标记的位置。下图中蓝色标记为高层的给出的目标位置。
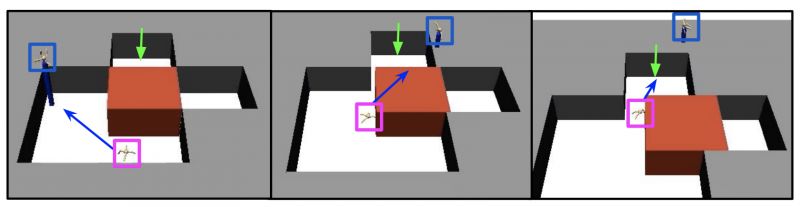
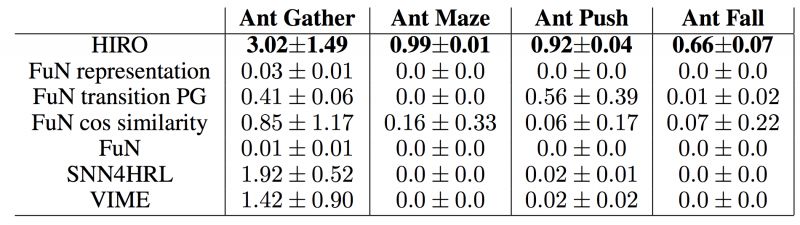
从实验结果上看,作者提出的HIRO在这一系列复杂任务中取得了很好的效果。下图中FuN是Feudal Networks[9]。FuN representation, FuN transition PG, FuN cos similarity为Feudal Networks[9]中作者提出的3个trick,实验中将这3个trick应用到HIRO上,发现效果反而不好。SNN4HRL[11]是将Stochastic Neural Networks应用到HRL中,VIME是一个非Hierarchical的模型。
总的来说,这篇文章通过高层给低层设置目标的方式来实现,并且目标是高层自动学习生成的,可以看做是高层的Action。但是仔细研究发现,实验中的状态表示和目标设置都是简单的位置坐标,这可能是因为在这个架构中,让高层生成复杂的目标比较困难。所以该工作应该只适用于状态简单的情形(如坐标),遇到状态复杂的情况(如图像)就还需改进优化。同时,这种固定两层的结构也没有拓展到更多层次的Hierarchy的能力。
4总结
层次化对于智能体来说是很自然也很重要的。例如对于一个在商场里寻找饭店的情形,对于人来讲,显然存在一个(想要去饭店 / 规划路径去饭店 / 选择向前走或转向或停下 / 控制腿部肌肉的活动) 的层次化结构。一方面,层次化结构能极大地减少探索的消耗,毕竟如果去饭店过程中每一个肌肉动作都需要思考,可能走一年也走不到饭店。另一方面,层次化结构蕴含很强的任务迁移能力,例如走路技能不论走哪里都是需要的,不应该重复学习。
虽然当前的HRL工作相较于非HRL的结构,解决问题的能力上有所突破,但改进的空间还很大。例如多层的HRL,不固定时间尺度的HRL,更有效的Skill Discovery策略等,都有待我们进一步探索。
[1] Richard S. Sutton and Doina Precup and Satinder P. Singh. Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning. 1999.
[2] Thomas G. Dietterich. Hierarchical Reinforcement Learning with the MAXQ Value Function Decomposition, 1999.
[3] Kulkarni T D, Narasimhan K, Saeedi A, et al. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation[C]//Advances in neural information processing systems. 2016: 3675-3683.
[4] Le H M, Jiang N, Agarwal A, et al. Hierarchical Imitation and Reinforcement Learning[J]. arXiv preprint arXiv:1803.00590, 2018.
[5] Tessler C, Givony S, Zahavy T, et al. A Deep Hierarchical Approach to Lifelong Learning in Minecraft[C]//AAAI. 2017, 3: 6.
[6] Fox, Roy, et al. "Multi-level discovery of deep options." arXiv preprint arXiv:1703.08294 (2017).
[7] Frans, Kevin, et al. "Meta learning shared hierarchies." arXiv preprint arXiv:1710.09767 (2017).
[8] Nachum, Ofir, et al. "Data-Efficient Hierarchical Reinforcement Learning." arXiv preprint arXiv:1805.08296 (2018).
[9] Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017).
[10] Kojcev, Risto, et al. "Hierarchical Learning for Modular Robots." arXiv preprint arXiv:1802.04132 (2018).
[11] Florensa, Carlos, Yan Duan, and Pieter Abbeel. "Stochastic neural networks for hierarchical reinforcement learning." arXiv preprint arXiv:1704.03012 (2017).
我们是骥智智能科技上海有限公司。我们致力于通用人工智能的无人驾驶研发,关注强化学习方法,视觉无监督语义级特征的生成模型技术,以及深度学习认知研究。





