唐宏 : 基于概率主题模型的高分辨率遥感图像非监督语义分割
导读
本报告从三个方面介绍基于概率主题模型的高分辨率遥感图像非监督语义分割,首先介绍语义分割基本的内涵和完成语义分割所涉及到的一些方法,其次介绍一些常见的概率主题模型,最后介绍一些简单的应用。
关注文章公众号
回复"唐宏"获取PDF及视频资料
作者

唐宏
北京师范大学教授
北京市重点实验室副主任
1.语义分割
什么是语义分割?如图所示,我们给机器一幅图像,希望机器给出专题地图,专题地图在每个像元上都会有一个对应的语义类别。简单的说,语义分割就是为图像上每一个像元分配一个地物类型的方法。本文的重点是讨论在非监督情况下如何对图像进行语义分割。

对于遥感图像而言,语义分割不是一个新的概念。在遥感图像分类的研究中,最开始研究者就想实现对一幅图像在每个像元上给出一个语义类别。最典型的方法就是提取像元的特征,对于每个像元的特征,通过一些算法对特征空间进行分割之后,判断像元处于特征空间的什么位置,据此从给定的类别集中选择一个类别,就可以把所有的像元结合在一起,形成一个专题地图,具体流程如下图所示。这种方法和我们刚才的语义分割达到的目的一样,区别是这种方法是基于像元实现分类。
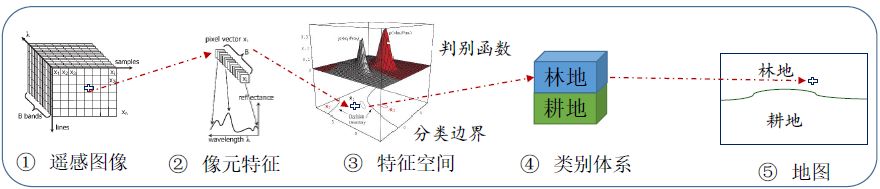
有很多方法能够实现基于像元的分类,这里介绍一种最简单的方法,假设每个地物类型符合某种特定的概率分布,再假设我们知道地物类型出现的概率。在这样的条件下,如果概率结构和概率分布的参数都一致,那么根据贝叶斯决策论,给定像元特征,就能够计算出它对应每个类别的后验概率,然后可以选后验概率最大的类别作为它的类别,这种方法称为产生式方法,是一种非监督学习方法。产生式方法主要解决三个问题:
第一是如何基于模型根据观测到的数据计算似然。
第二是如何推断每一个观测数据所对应的各个类别的后验概率,也称为状态的推断。
第三是如何通过似然的极大化估计模型中的参数,主要是均值、斜方差矩阵和混合比例。
假设我们的模型参数已知,对任何一个像元,可以很容易通过如下计算方式获得似然
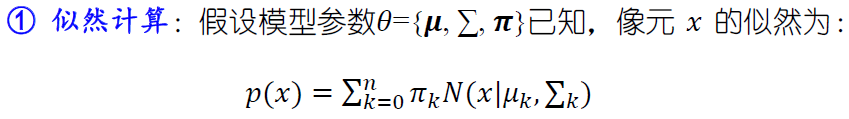
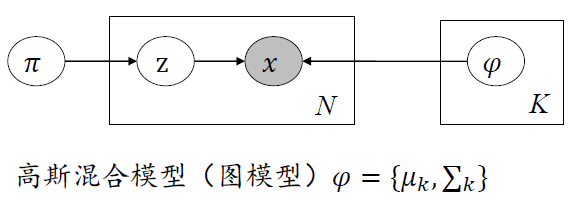
刚才设定的框架在非监督学习下有一个专有名词,称为高斯混合模型,将高斯混合模型用图的方式进行表示
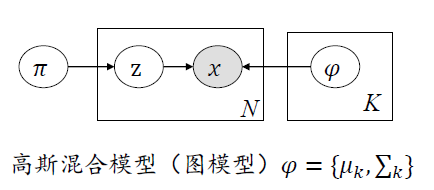
图中,圆圈代表随机变量,涂黑的部分表示图像像元或其特征,圆圈之间的箭头表示依赖关系。例如x观测量会依赖z和φ,其中φ就是高斯模型中的参数。
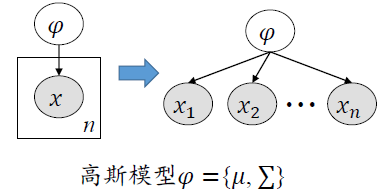
z表示类的标号,服从先验分布,对每一个观测的样本,我们想知道它由给定的高斯模型产生的概率是多大。具体做法是先根据类别先验分布选择第几个高斯混合成分,然后根据被选择的高斯分布进行采样,产生相应的样本。
推断图象所对应的状态,事实上就是逼近z所对应的后验概率的过程,计算出观测数据对应的类型或者类型分布后,就可以进行参数的估计了,在非监督学习下,最常用的参数估计方法就是极大似然法,一般做法是选定目标函数,然后相对于我们要求解的参数进行求导,找出极值点:
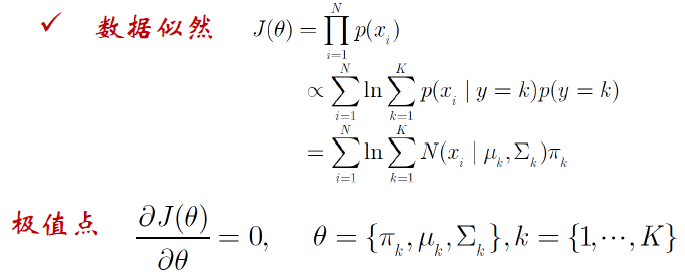
通过推导,我们能得到高斯混合模型中的混合比例,均值,协方差矩阵:
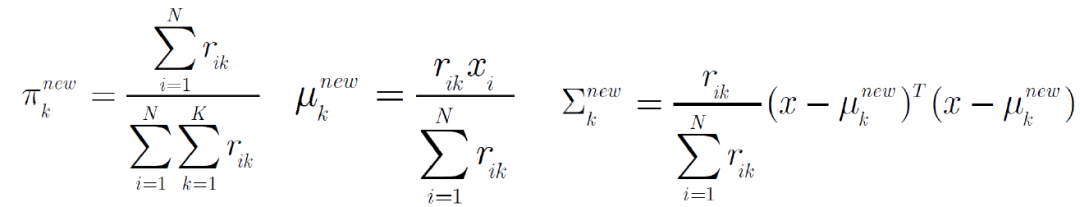
除此之外,还可以计算出第i个观测数据由第k个高斯产生的后验概率:
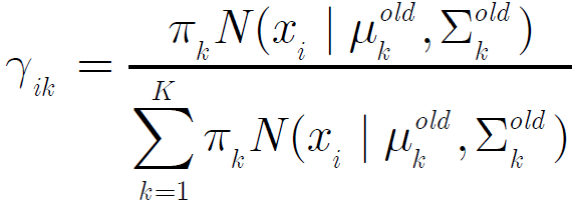
在这个过程中,我们使用的是期望极大化算法(EM算法),算法具体步骤此处不再赘述。
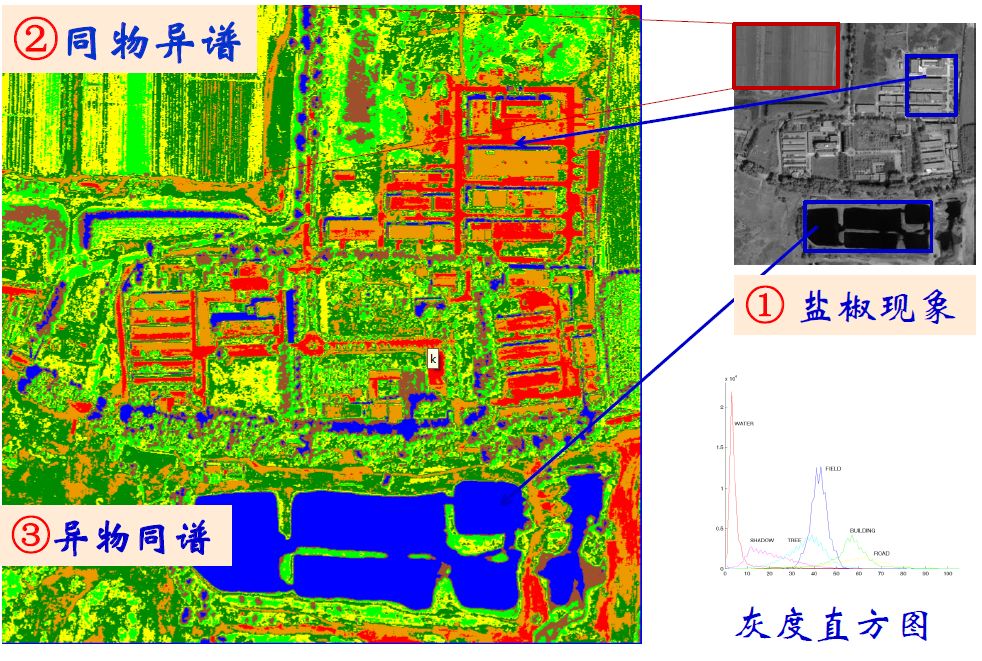
将这个方法用在遥感图像上,如图所示,假设我们要分析的图像是图中的灰度图像,我们采用灰度值作为观测像元的特征,用高斯混合模型聚类,观察结果,我们会发现几个特点,一是有的地方类别分布非常破碎,我们称为“盐椒类现象”,二是有的地方被分割成多种颜色,这种情况就是同一个物体由于灰度不同,被聚成不同的类型。另外在图中我们可以发现水体和建筑区域形成阴影的DN值非常相近,这种将光谱值相同的、不同物体归成同一个类的情况在遥感图像中称为异物同谱,之所以出现这些问题,主要原因是基于像元的分类只是在对应的特征空间进行分类过程,没有考虑到图像平面像元之间的位置、形态等关系。
2.主题模型
主题模型最初主要用于文本理解,处理的基本对象是文章,文章由很多词组成,主题模型不考虑词在文章中的顺序,这有点类似高斯混合形式。主题模型不仅仅可以处理文本数据,凡是分析的对象能够用词袋模型进行表示,就可以使用概率主题模型进行建模,主题模型的优点是能从海量的数据中发掘出数据集中隐含的语义。
词袋模型就是忽略文章中的语法和语序,仅仅用一组无序的词表示这样一篇文章,观察如下两篇文章:

用词袋模型表示这两篇文章基本的过程很简单,第一步是构造字典:
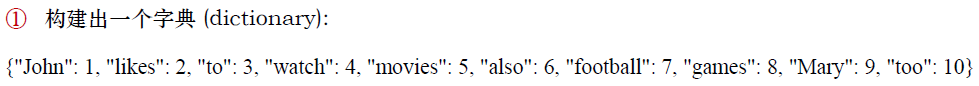
然后,用数字替换掉这两篇文章所对应的字,然后按构造的字典,统计每个字在文章中出现的次数:

由于文章表示成这样无序的一组数,所以对这些离散的观测量我们可以使用多项式分布,这个概率模型最主要的参数是每个词所出现的概率。多项式分布还有一个共轭分布,叫做Dirichlet分布,两者结合可以对模型参数进行集成。
用非监督方式学习去学习概率主题模型,能够从海量的数据里面发现文档所隐含的语义,语义首先包括主题,比如一篇文章谈论有关政治、体育还是法律,用它做图像的分类,可以理解成地物类别。语义还包括一定程度上对词含义的理解,同一个词在不同文章里面可能有不同的意思,能否通过主题模型推理出意味着我们能够解决上文提到的同谱异物问题。
现在介绍主题模型本身,先看一个最简单的概率主题模型:
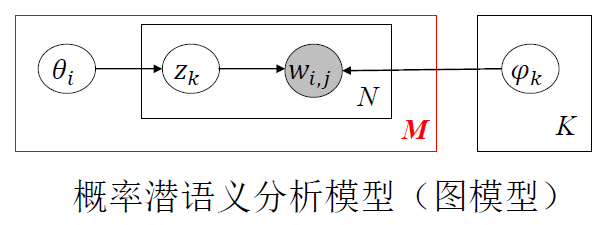
这个模型和高斯混合模型很像:
唯一显著的不同就是用红线标注出来的这个框和它所对应的数字M,我们只要知道是它是参数就可以。
概率主题模型实际上可以类比成多个高斯混合模型,高斯混合模型和概率主题模型有一个共同的地方,就是每个类的概率分布是共享的。据此能够求解模型的似然,只要求出似然就可以推断它的状态,进而估计参数。
对于第i篇文章的第j个词(wi,j),其似然为:
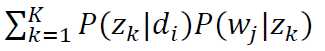
整个文集(M篇文章N个词)的似然为:
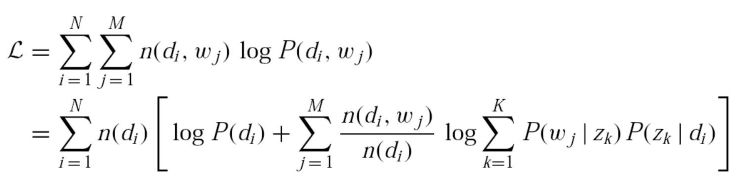
具体推导过程可以参考文献(Hofmann,2001)。
然后,可以用EM方法估计模型的参数,推断对应的状态,也就是计算出每个词所对应的分布,然后对似然进行极大化,算出高斯参数或者多项式参数:

这就是pLSA模型,pLSA模型有一个问题,就是模型的参数会随着文章数量、主题个数或词数量的增加而增加,参数多了之后会变的非常复杂,容易造成过拟合,为了解决这个问题,在此基础进行修改,得到LDA模型:
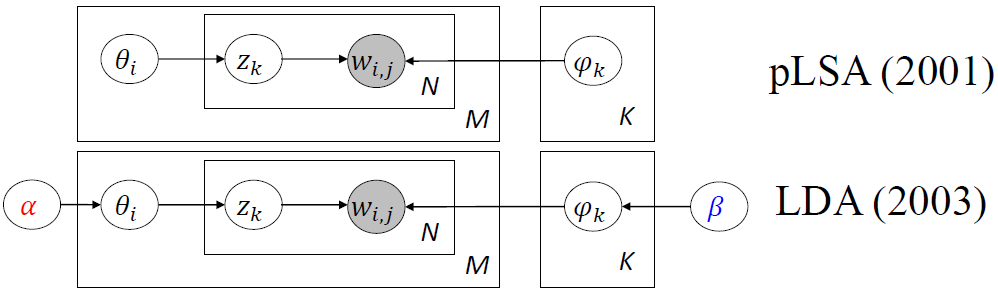
对比pLSA和LDA,可以发现LDA增加了两个参数α和β,它们是Dirichlet分布的参数,LDA增加Dirichlet分布有一个好处,由于这两个分布是共轭分布,使得最终结果的计算变得非常容易,直接利用如下的公式就可以:
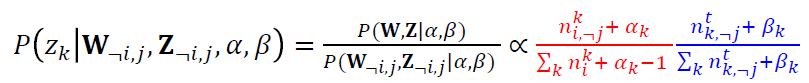
这个公式也被称为Gibbs采样公式,这个公式的主要思想是利用条件的分布逼近它们之间的联合分布。
LDA模型已经足够好了,但是还有一个缺陷,必须要知道类别的数量,然而在遥感图像里给定一幅图像之后要确定有多少类也不是很容易的事情,更深一步的HDP模型可以完成这个任务,HDP模型的推导过程就是经典的中餐馆过程(CRP):
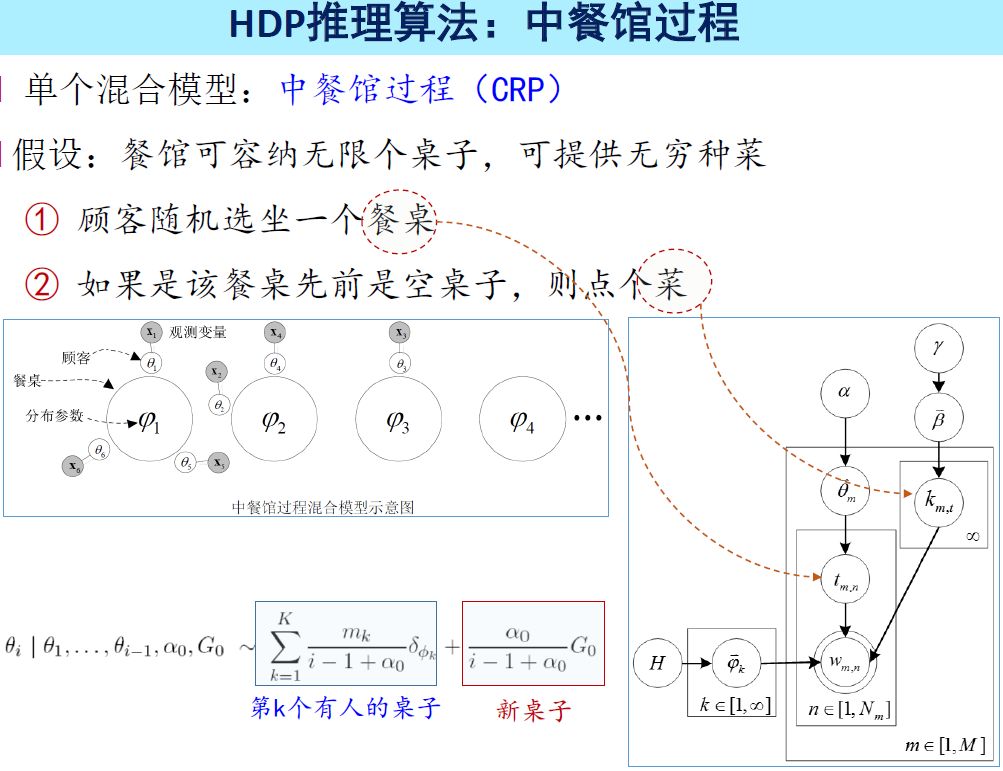
假设餐馆里面有很多桌子,有很多菜,推理的过程可以简化为:顾客要随机选择一个餐桌坐下来,如果餐桌之前没有人坐过,那就去点一个菜。与LDA不同的地方在于每次都可能会产生新桌子,这样能够推断出桌子的数量。每一篇文章是一个餐馆,所有的菜都是共享的,餐馆里面大家用同一种菜单。选桌子过程对应的就是图像分割过程,点菜的过程就是分类的过程。
3.遥感应用
要使用主题模型,必须想办法用词袋模型表征待分析对象。在图像应用中,假设一张图像对应一篇文章,原来连续的一些特征对应的就是文章中的词。预处理过程和刚才的词袋模型表示过程一样,先进行特征提取,然后形成一个字典,根据字典统计出直方图。在遥感图像中,如果我们把一级影像看成一个餐馆的话,数据量太大。那么就要进行语义分割问题,我们需要把图像切成小的图像,然后将小的图象当成一篇文章,或者上文提到的一个餐馆:

下图是把pLSA模型用到本文开始的图像中,并与高斯混合模型进行比较:

其中不同的颜色代表不同的主题或者不同的类,仔细观察,可以发现左侧很多阴影部分被当成了水,而右侧没有这种情况。这是因为主题模型能够根据不同的状况,对同种元素在不同的地方产生不同的理解。
主题模型可以解决遥感图像中的一些同谱异物的问题,但是它也有缺陷,它的问题跟上文提到的高斯混合模型问题一样,它假设文章中各个词没有任何顺序的关系,不同的分析单元(也就是每块图像)之间是条件独立的。解决这个问题最简单的办法,就是在局部图像平面上引入一个空间的相关关系。我们刚才打了一个比喻,中餐馆中人进来先选择桌子再点菜,而依赖距离的中餐馆过程则略有不同,具体来说就是人进了餐馆之后,不是找桌子而是找人,以这样的关系实现空间的聚类。事实上,可以把像元之间的空间关系都可以纳入距离里面,这种方式是在输入端引入局部连接的方式。除此之外,也可以在输出端引入一个空间关系,比如引入Markov随机场约束。下图可以看出使用各种方法的效果

其中左上图是初始的SAR图象,如果纯粹的用CRP进行聚类,就相当于使用类数不给定的一个高斯混合模型,那么得出的结果如右上所示,可以看出斑点很多,结果不好。左下图是增加了Markov先验约束相对弱一点的情况,右下图是约束强一点的情况,可以看出空间一致性得到了增强。
前文所描述的方法目前还只是用在全色影像上,其它类型的影像其实也是适用的。比如对于多光谱图象,通过K均值将它聚成若干个类别,其实和全色影像是一样的。如果观测的数据有两种,一种是全色影像,另一种是多光谱影像,那我们可以将这两种图象纳入这样的框架中,同时做一点小小的改动。一般全色影像空间分辨率更高,多光谱影像光谱分辨率更高,我们用更多的光谱信息进行分类或者聚类,这样既可以利用全色影像高空间分辨率空间信息,又可以利用多光谱的光谱信息。总的来说,就是用全色实现分割,用多光谱实现分类,虽然数据不同,但它们共享图像分割体的基本信息。下图为实验效果,左侧两幅图像对应的选桌子结果,中间对应的是点菜结果,右侧对应选桌子和点菜这两个采样的持续过程。

我们做了一个实验,在四川在龙门山断裂带东北部选择了一个影像,在西南边选了一个影像,这两处地方的传感器不同、下垫面不同,它们的距离尽管不是特别远,但也不是同一个地点的影像,用我们的模型可以比较好的提取建筑物,这一研究可以用在地震救援中(例如,Shu et al.,2015; Mao etal.,2016; Li et al.,2017)。
我们下一步想实验更多传感器,更多元,观察不同分辨元影像性能。这其中牵扯到很多模型,给大家列出来放在这里,如果大家对其中一个模型或者几个模型感兴趣,大家可以去查阅一下这些文献。


历史文章推荐:




