CVPR 2022 Oral | 基于熵筛选的半监督三维旋转回归

关键词:半监督学习 三维旋转回归 概率建模

导 读
本文是计算机视觉顶级会议CVPR 2022入选的口头报告(oral presentation)论文《FisherMatch: Semi-Supervised Rotation Regression via Entropy-based Filtering》的解读。该论文由北京大学陈宝权和王鹤研究团队合作,首次提出从单帧 RGB 图像中回归三自由度物体旋转(朝向)的半监督学习算法 FisherMatch。
该算法对 SO(3) 群上的旋转回归进行基于 matrix Fisher 分布的概率建模,利用分布的熵导出伪标签的置信度从而进行伪标签筛选。该机制大大优化了从有标注数据到无标注数据的信息流动,展示了在 ModelNet10-SO(3),Pascal3D+ 等数据集上对半监督三维旋转回归任务效果的显著提升。

论文地址:https://arxiv.org/abs/2203.15765
项目主页:https://yd-yin.github.io/FisherMatch
01
引 言
使用深度神经网络从单帧 RGB 图像中回归物体的三自由度旋转(朝向)是物体位姿估计、机器人抓取、三维重建等应用的关键技术之一,受到计算机视觉和计算机图形学的广泛关注。尽管近年来旋转回归领域的监督学习取得了明显的进展,这些工作大都依赖大规模有标注数据集。众所周知,三维旋转的精确标注是非常昂贵和耗时的,这一因素已经成为了制约该项技术发展的瓶颈之一。为了减少所需的标注,我们因而考虑探索半监督学习。当前半监督学习领域的工作主要关注分类问题,对回归关注不足,特别是对于旋转回归而言一片空白。注意到这样的算法需要处理 SO(3) 群这种非欧几里得流形上的元素预测并施加半监督学习,这对已有的半监督学习算法提出了严峻的挑战,也带来了可以研究的空间。
这此项工作中,我们首次提出了一个针对三维旋转回归的一般性的半监督学习算法 FisherMatch。该算法不局限于特定领域的知识,也不要求同一物体不同视角的图像对。借鉴在图像分类任务中广泛使用的半监督学习算法 FixMatch [1],我们采用师生共同学习框架,其中学生模型的参数是可学习的,而老师模型的参数是学生模型参数的指数移动平均数(exponential moving average)。有标注数据和其对应真值用于训练学生模型,而无标注数据则使用由老师模型输出的“伪标签”进行监督,因而构建了师生模型之间的历史一致性。
FixMatch 成功的关键在于过滤掉置信度较低的伪标签,而仅使用高置信度的伪标签监督模型。这里的基本假设是预测结果的置信度和其质量呈正相关关系,因而基于置信度的筛选机制确保了伪标签的质量。幸运的是,分类任务输出的类别概率值天然包含了置信度信息;类似地,在三维目标检测任务中,3DIoUMatch [2] 构建了单独的网络用于预测当前输出的置信度。然而,由于缺乏对结果置信度的合理估计,将 FixMatch 应用到三维旋转回归任务中十分困难——我们既不能像分类任务一样直接依据概率值的大小作为置信度,也不能像三维目标检测任务一样产生足量对置信度的监督,但是我们依旧需要置信度来支持伪标签的筛选。
正如 [3] 指出,对旋转空间的概率建模是获取旋转回归置信度的合理方法。为了适应 SO(3) 群的特点,研究者分别使用 Bingham 分布,matrix Fisher 分布等分布描述旋转空间,进而获得置信度信息,其中 matrix Fisher 分布由于旋转表示的连续性获得了更优的效果。
在本文中,输入单张 RGB 图像,算法将输出一个 matrix Fisher 分布的参数,进而构建 SO(3) 空间的分布。我们提出通过计算分布的熵表达预测的置信度,并用于伪标签筛选机制。具体来讲,只有高置信度,即熵小于阈值的伪标签才会通过筛选并用于监督模型。实验证明熵对预测结果的效果具有明显的表达作用,即使在标注数据很少(低至5%)的情况下,熵仍能高效表达预测的准确性。在物体三维旋转估计的常用数据集 ModelNet10-SO(3) 和 Pascal3D+ 数据集上,我们的算法在多种标注数据比例的设定下均取得了明显优于全监督和其他半监督基线算法的效果。
02
方法简介
三维旋转的概率建模
Matrix Fisher 分布是在 SO(3) 空间针对旋转矩阵的一种概率分布,概率密度的表达式为:
另一个重要的分布是在
考虑到旋转表达的连续性,我们使用 matrix Fisher 分布对 SO(3) 空间进行概率建模,以预测三维旋转回归的置信度。
算法框架
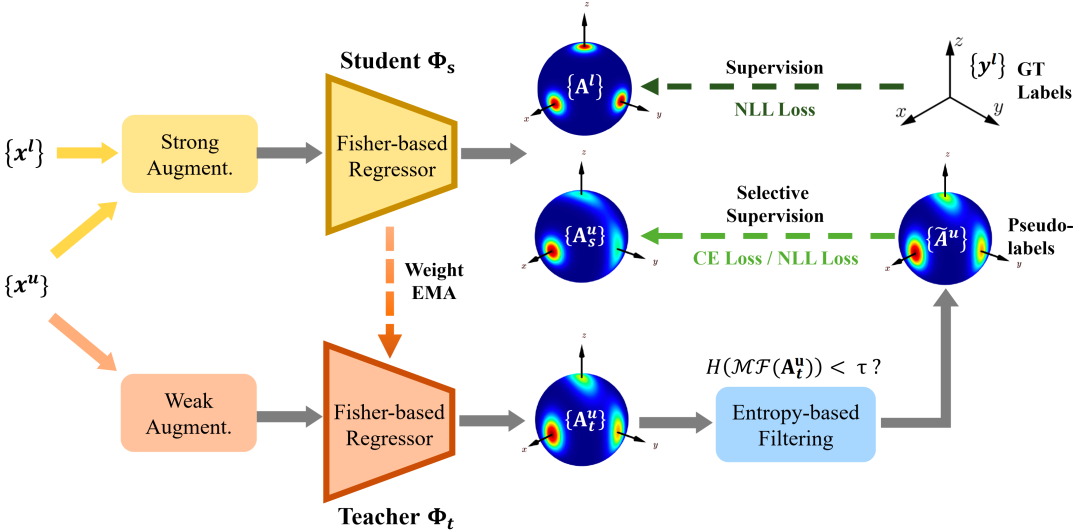
图1. 算法框架
如图1所示,旋转回归器
受 FixMatch 启发,我们仅希望使用预测准确的伪标签来监督学生模型,否则,质量较差的预测将会减慢训练过程,甚至对系统造成损害。为了刻画预测的置信度,我们提出使用分布的熵,这一在统计学中常用于描述混乱程度的物理量,来衡量不确定性。较低的熵代表了较“尖锐”的分布,亦即较低的不确定性和较高的置信度。具体来讲,仅当伪标签的熵低于给定的阈值
对于有标注数据,我们使用 negative log likelihood (NLL) 损失函数来学习旋转的概率模型。对于无标注数据,不同于常规的回归任务,学生模型的输出和伪标签均为概率分布,我们分别探讨了 cross entropy (CE) 损失和 negative log likelihood (NLL) 损失函数,发现 NLL 损失是 CE 损失在伪标签绝对确信情况下的极限。实验发现,CE 损失对置信度的阈值有更高的宽容度,实验中我们使用 CE 损失作为无监督损失函数。
03
实验结果
在 ModelNet10-SO(3) 和 Pascal3D+ 数据集上,我们将本文算法和多个基线算法进行对比,结果如图2、图3所示。实验结果证明,在多种标注数据比例的设定下,我们的算法显著优于其他算法,体现了方法的有效性。
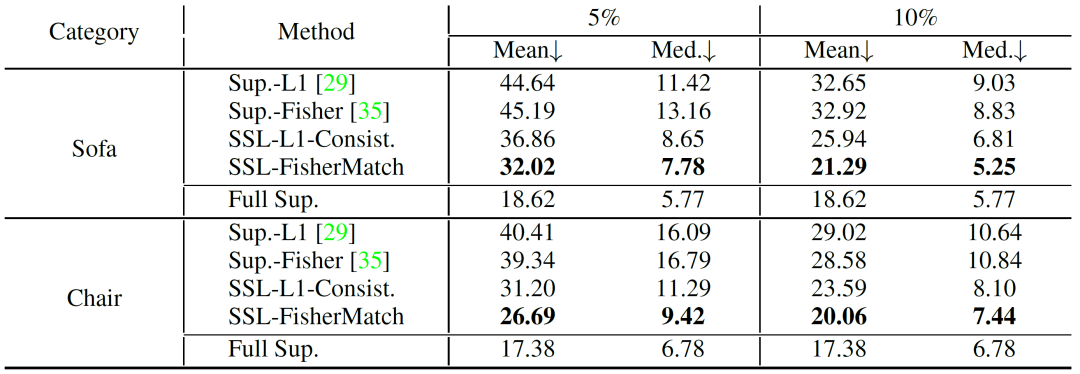
图2. ModelNet10-SO(3) 数据集上的数值结果
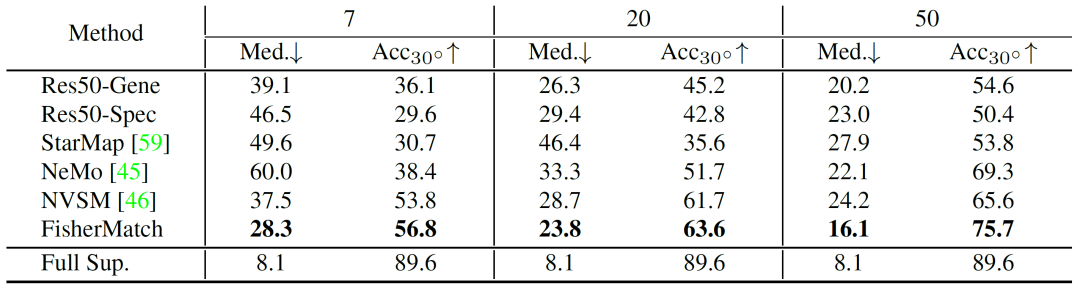
图3. Pascal3D+ 数据集上的数值结果
分析可知,随着半监督学习的进行,无标注数据的置信度不断上升,通过置信度筛选的伪标签比例越来越高,同时质量基本维持稳定,在无标注数据和测试数据上都获得明显的效果提升。

图4. 训练过程分析
04
结 语
我们提出了半监督学习从单帧 RGB 图像中回归物体三维旋转的算法 FisherMatch,算法利用师生共同学习框架,通过对 SO(3) 空间的概率建模构建基于熵的伪标签筛选机制。实验证明了算法的有效性。
当有标注数据和无标注数据数量都很少时,网络预测的置信度由于过拟合失去了对预测效果的有效表示,进而降低了伪标签筛选和整个算法框架的效果。
参考文献
[1] Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems, 33:596–608, 2020.
[2] He Wang, Yezhen Cong, Or Litany, Yue Gao, and Leonidas J Guibas. 3dioumatch: Leveraging iou prediction for semisupervised 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14615–14624, 2021.
[3] Sergey Prokudin, Peter Gehler, and Sebastian Nowozin. Deep directional statistics: Pose estimation with uncertainty quantification. In Proceedings of the European conference on computer vision, pages 534–551, 2018.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“FMER” 就可以获取《CVPR 2022 Oral | 基于熵筛选的半监督三维旋转回归》专知下载链接





