训练轮数降至1/10、性能却更好?商汤&中科大提出升级版DETR目标检测器

极市导读
来自商汤研究院和中科大的研究者提出了“可变形DETR”,它能解决原始DETR收敛慢、计算复杂度高这两大问题。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2010.04159
DETR收敛慢、计算复杂度高的固有缺陷催生了可变形DETR
当今的目标检测器大多使用了人工设计的组件,如锚框生成、基于规则的训练目标分配、非极大值抑制后处理等。所以它们不是完全端到端的。Facebook AI 提出的 DETR【1】无需这些手工设计组件,构建了第一个完全端到端的目标检测器,实现了极具竞争力的性能。DETR 采用了一个简单的结构,即结合了卷积神经网络和 Transformer 【2】的编码器-解码器结构。研究人员利用了 Transformer 既通用又强大的关系建模能力来替代人工设计的规则,并且设计了恰当的训练信号。
虽然DETR的设计非常有趣,而且性能也很好,但它自身也存在着如下两个问题:
以上提到的问题可以主要是由于 Transformer 中的组件在处理图像特征图时的天生缺陷。在初始化时,注意力模块(如公式(1)所示)的注意力权重近似均匀地分布在特征图的所有像素上,所以需要非常长的训练轮数来学习将注意力权重集中于稀疏的有意义的位置。另一方面,Transformer 的编码器中注意力权重计算的复杂度与像素个数的平方成正比。因而它需要非常高的计算和内存复杂度来处理高分辨率的特征图。
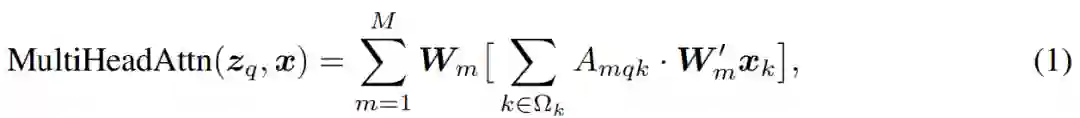
在图像领域,可变形卷积【5】是一个非常强大而且高效的机制,它将注意力集中于稀疏的空间位置。虽然天生避免了上面提到的这些问题。但它缺乏关系建模机制这一元素,而这是 DETR 成功的一大关键。
所以,在本文中,来自商汤研究院和中科大的研究者提出了可变形 DETR,解决了 DETR 收敛慢、计算复杂度高这两大问题。
可变形DETR方法和模型解读
具体而言,可变形 DETR 结合了可变形卷积中的稀疏空间采样的优势和 Transformer 中的关系建模能力。研究者提出了可变形注意力模块(如公式(2)所示),它关注于一小部分采样的位置,作为从特征图所有像素中预先筛选出显著的 key 元素。
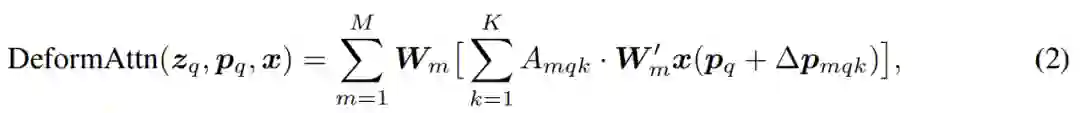
这一模块天生可以被扩展到聚合多尺度特征上(如公式(3)所示),而不需要 FPN【6】的帮助。
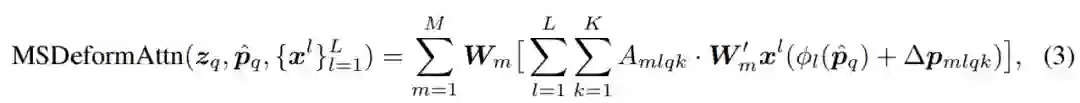
可变形 DETR 目标检测器用(多尺度)可变形注意力模块替换 Transformer 注意力模块来处理特征图,如下图 1 所示。
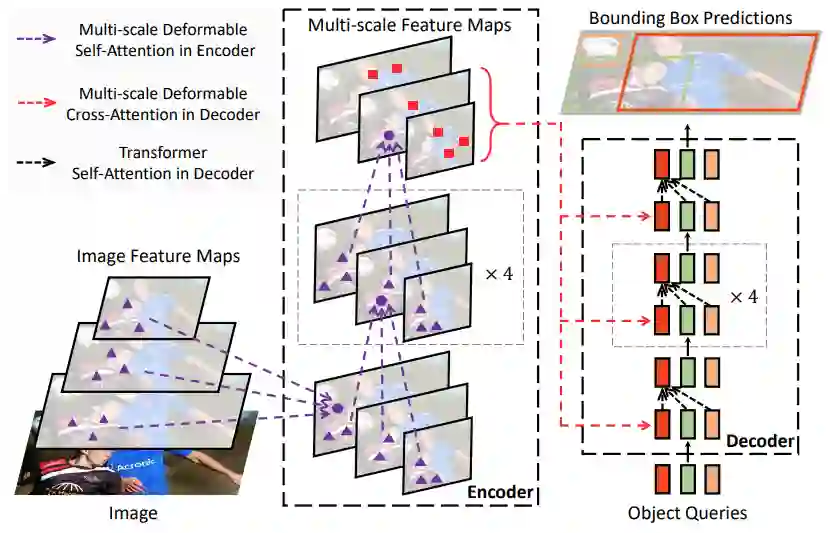
图 1:可变形 DETR 目标检测器图示
由于可变形 DETR 的快速收敛性和计算、内存高效性,它打开了探索端到端目标检测器的变种的可能性。此外,研究者探索了一个简单而有效的迭代式物体边界框细化机制来进一步提高检测性能。他们也尝试了两阶段可变形 DETR,其中第一阶段的 region proposals 也是由可变形 DETR 的一个变种生成,然后被进一步输入到解码器进行迭代式物体边界框细化。
研究者在 COCO 基准【3】上的大量实验展示了这一方法的有效性。与 DETR 相比,可变形 DETR10 训练轮数降至 1/10(见下图 2),但达到了更好的性能(尤其是在小物体上,见下表 1)。本论文中提出的两阶段可变形 DETR 变种可以进一步提升性能,可变形 DETR 的代码也将开源。
实验结果
下面将介绍论文中的一些主要实验结果。
可变形 DETR 与 DETR 在 COCO 2017 val set 上的性能对比如下表 1 所示。
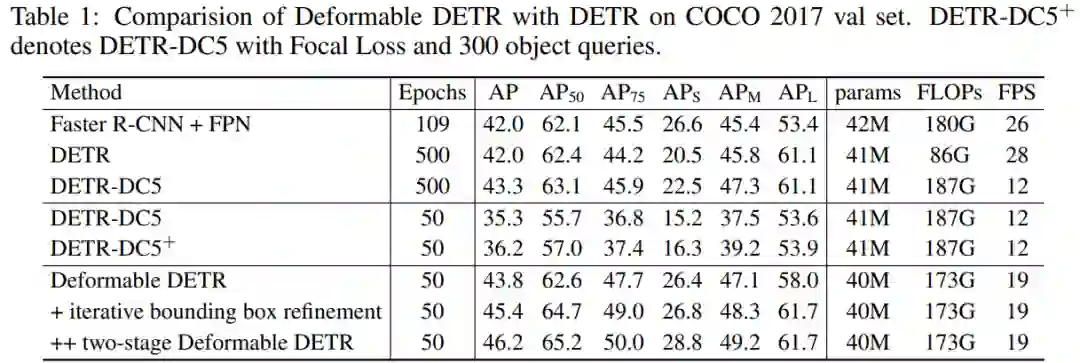
表 1:可变形 DETR 与 DETR 在 COCO 2017 val set 上的比较
可变形 DETR 和 DETR 的收敛曲线对比如下图 2 所示。
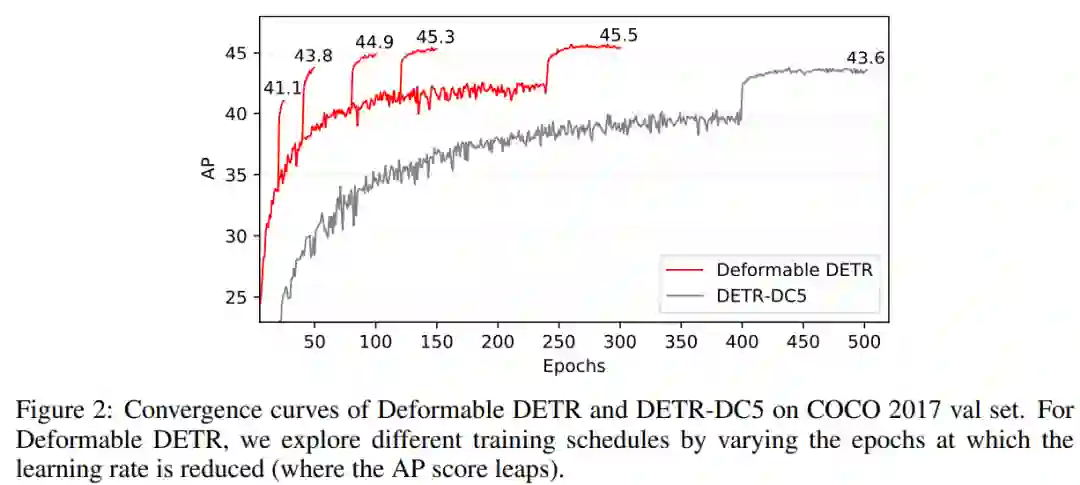
图 2:可变形 DETR 与 DETR 的收敛曲线对比
可变形注意力模块的控制变量实验如下表 2 所示。
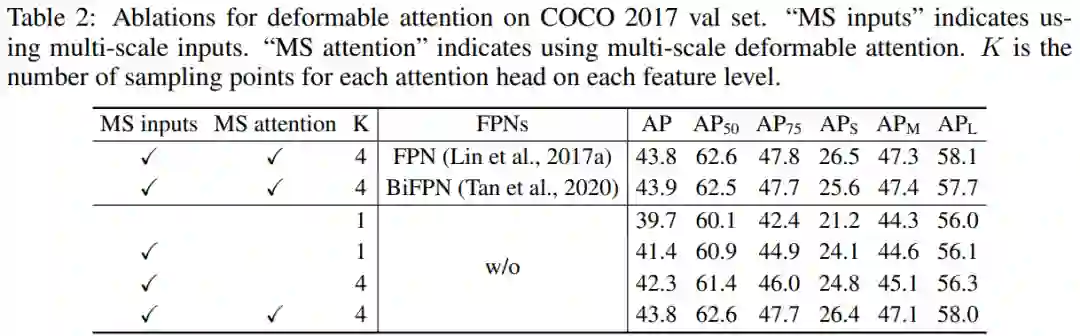
表 2:控制变量实验
可变形 DETR 与当前最为先进的目标检测器在 COCO 2017 test-dev 上的性能对比如下表 3 所示。
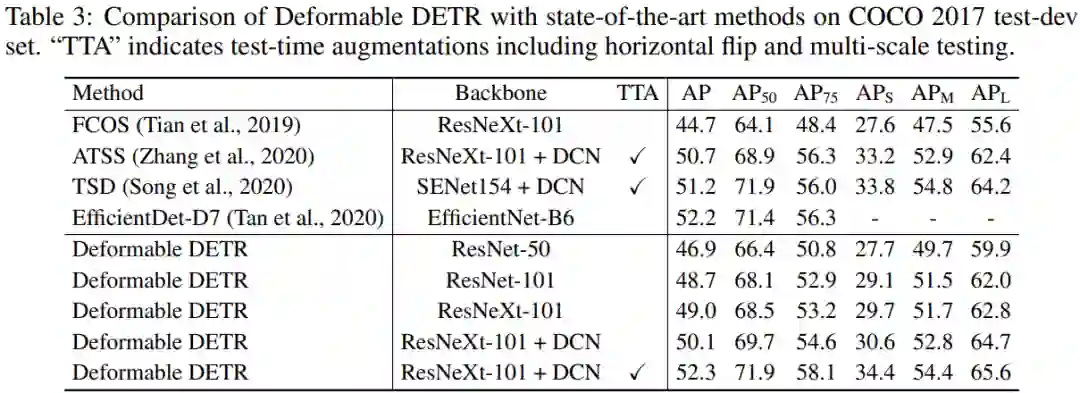
表 3:可变形 DETR 与当前最先进的方法在 COCO 2017 test-dev 上的比较
参考文献
[1] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
[3] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[4] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
[5] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017.
[6] Tsung-Yi Lin, Piotr Doll´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017a.
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!