UniLM-UIE在多形态信息抽取比赛中的应用

研究方向 | 信息抽取及预训练模型风险

近年来,基于通用信息抽取(UIE)的范式在学术届、工业界引起了广泛的关注,一系列相关的顶会文章涌现出来 [1,2,3,4,5,6,7,8,9],涉及 信息抽取、问答、对话、分类、匹配、文本生成等不同的 NLP tasks。
CCKS22 通用信息抽取技术创新奖 [10,12,14]
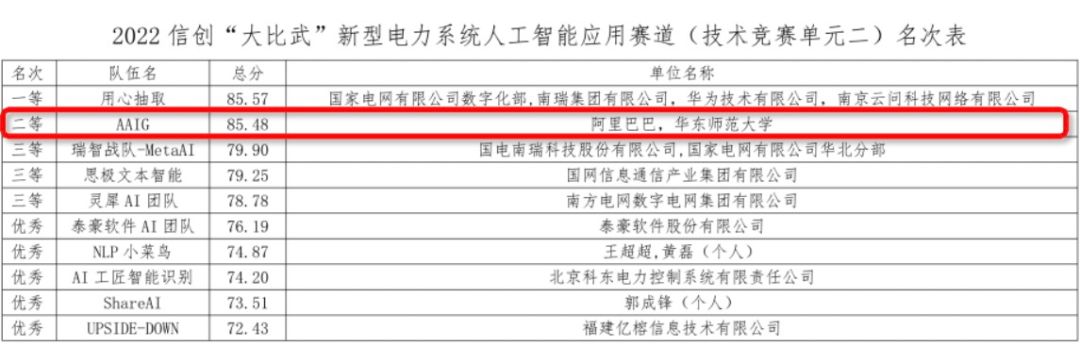
电力抽取比赛选拔赛、决赛模型得分 TOP1 [11,15],总分 TOP2 [28](决赛模型分 85.54,总分 8 5.48(TOP1 总分 85.57),非电力行业背景)

-
Decoder-only 相比 Seq2Seq,降低了模型复杂度 -
相比 Seq2Seq,Decoder-only 可以实现更大的基础模型如 GPE-MOE [16] 、GLM [17]
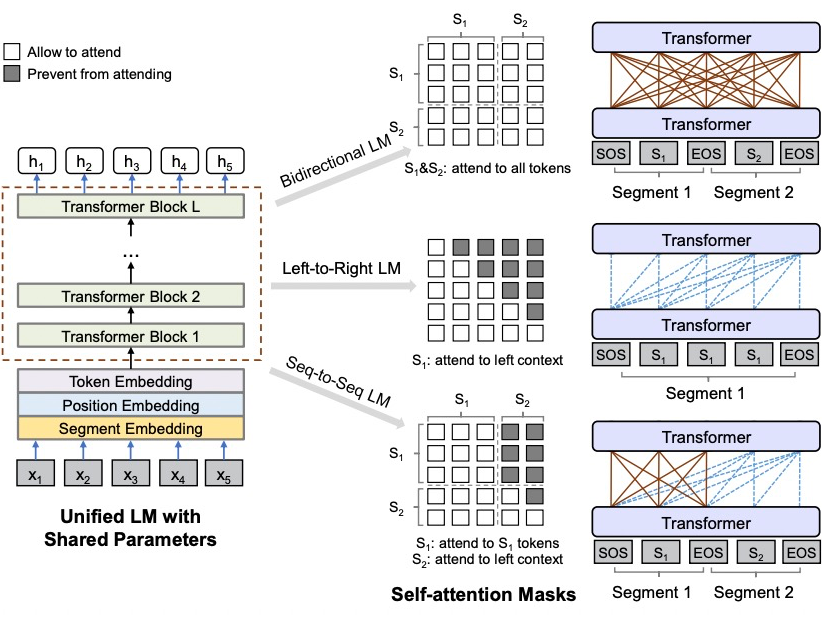
UniLM-Seq2Seq 模型的训练则相对比较简单,输入序列包含 条件输入+输出序列,attention mask 根据输入、输出序列构建即可。
2.2 UIE
前面,我们主要介绍了 UniLM 的基本原理,下面,我们主要介绍 UIE 的输入和输出构造形式:
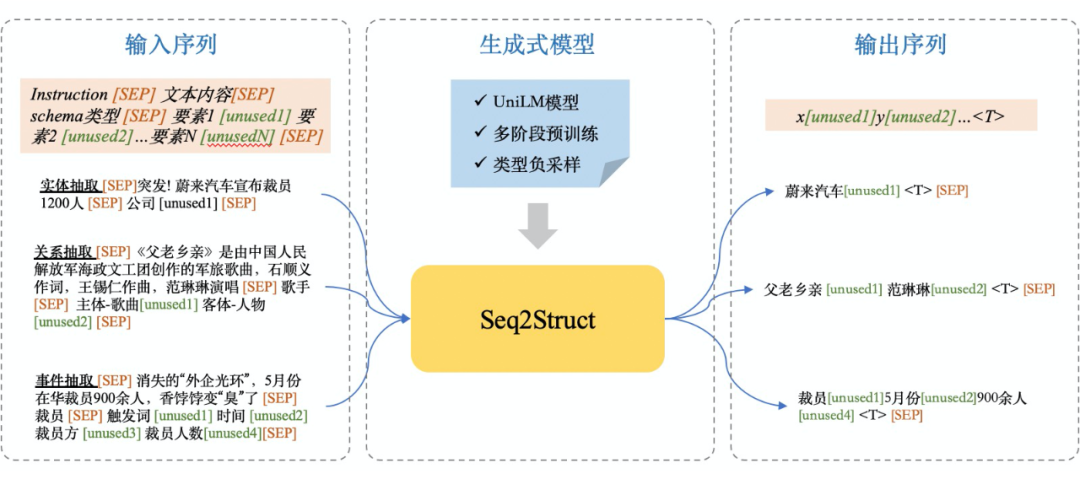
2.2.1 输入形式
输入形式与模型独立无关,不同的文章有不同的输入形式,当然,输入形式也决定了解码方法。这里,我们采用如下的输入形式:
instruction[SEP]text[SEP]schema-type[SEP]element_1[unused1]element_2[unused2]...[SEP]这里,instruction 代表任务类型,如实体抽取、信息抽取、事件抽取。当然,也可以考虑加入领域如事件抽取-灾害意外等,构建更细粒度的 instruction。这里:
schema-type 为预先指定的一个 schema 类型,如地震;
-
element_1[unused1] 则表示一个要素。其中,element_1 为要素的文本描述,[unused1] 则为一个 sentinel token,代表该要素。不同的 element 对应不同的 sentinel token,即可实现不同 element 的区分;
2.2.2 输出形式
value_1[unused1]value_2[unused2]...<T>value_3[unused1]value_4[unsued2]...<T>[SEP]value_1 为一个生成的值,通常为一个 token span,其类型则为 [unsued1]。根据输入 schema 的要素类型和 sentinel token 的对应关系,value_1 的类型为 element_1。
<T> 则实现了不同元组的区分即每一个
内的元组均为一个完整的结构化元组如 SPO、实体或者事件元组。

由于我们的 UIE 输入需要指定 schema 类型,在训练时这个可以根据有监督数据获取,然而,在推理阶段,却需要一个辅助分类器获取 schema 类型。这使得 UniLM-UIE 并非一个完整的端到端抽取模型,且抽取效果依赖于 schema 分类结果。schema 分类器在少样本、schema 类型易混淆等场景下,容易成为性能瓶颈。为此,我们提出了使用类型负采样的训练策略 [20]:
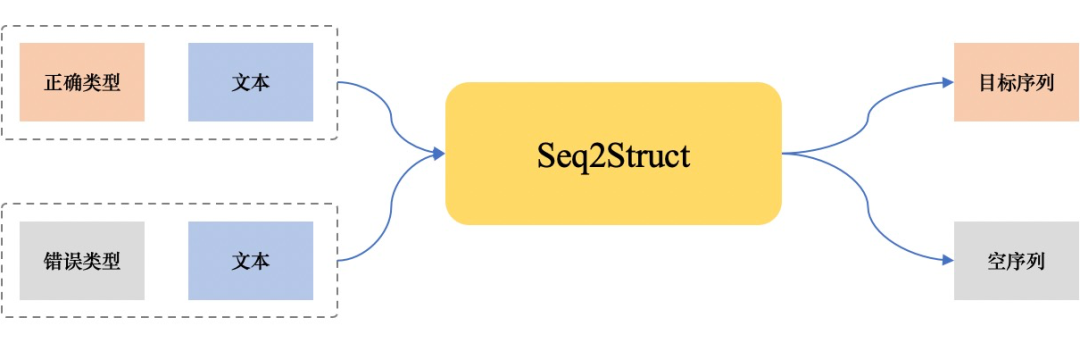
UniLM-UIE 成为一个真的的端到端抽取系统,不必依赖 schema 分类器;
负采样使得模型学会根据输入内容、schema类型 决定是否输出目标序列(知之为知之,不知为不知);
类型负采样使得模型对错误 schema 类型具备一定的鲁棒性。
3.2.1 无监督预训练
Roberta-Large 只使用了 MLM 预训练且为双向 attention mask,对于复杂 Seq2Seq 任务效果较差(具体地,我们基于 bert4keras 实践了 duee 的 UniLM-UIE 事件抽取,在三元组的评估方式下,20-epoch 很难收敛);
-
我们构造的 UIE 输入输出形式与 T5 的预训练形式较为接近,与下游应用更匹配的预训练对于下游任务更有帮助 [3] ;
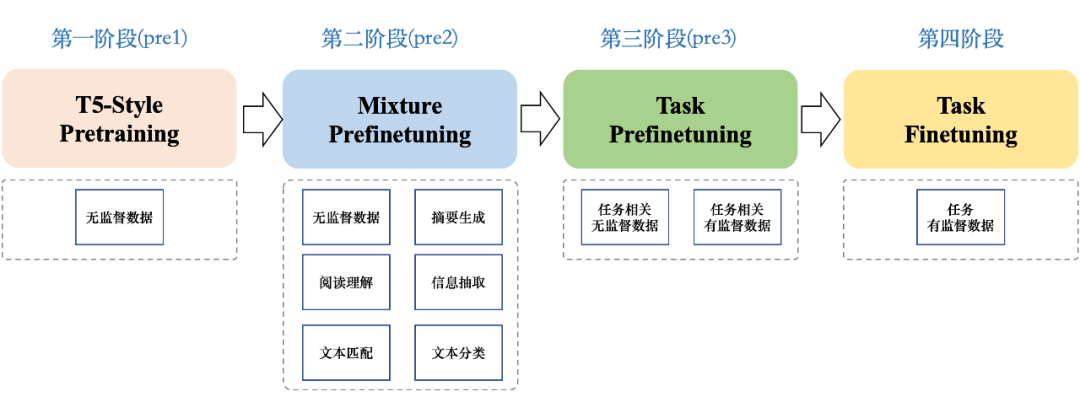
3.2.2 prefinetuning
prefinetuning 阶段,我们主要考虑了两个不同的训练方法,mixture-pre-finetuing 使用了全部的有监督(包括阅读理解、分类、匹配、抽取等)+无监督数据进行训练,旨在让模型学会使用有监督数据的标签信息,同时,加入无监督数据,避免模型过拟合。
task-prefinetuning 阶段则主要考虑了任务数据的有监督(信息抽取、事件抽取、实体抽取)+无监督训练。如果训练 budget 有限的情况下,直接进行 task-prefinetuning 也能达到较好的效果。
3.3 解码过程
由于信息抽取的要素值均位于原文,所以,我们采用约束解码 [21] 限制解码空间,同时,设置 beam-search-width=2。

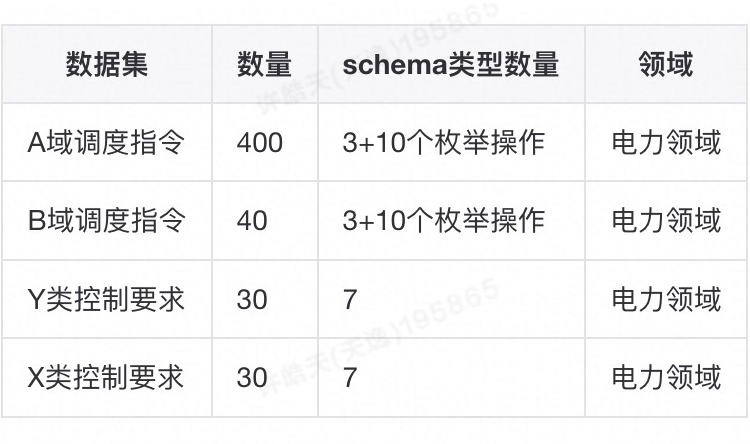
电力多模式抽取比赛是电力行业电力调度场景的事件抽取。其训练数据如下表所示:
("事件类型", “要素类型”, "要素值")[("事件类型1", “要素类型1”, "要素值1"), ..., ("事件类型1", “要素类型n”, "要素值n")]
[("事件类型1",“要素类型1”, "要素值11"), ..., ("事件类型12", “要素类型n”, "要素值1n")]
3. 本次比赛需要线上提交推理包在线推理,对推理时间(2小时)、压缩包大小(6G)有明确限制。限制了过多的模型集成等,更符合实际生产环境等应用。

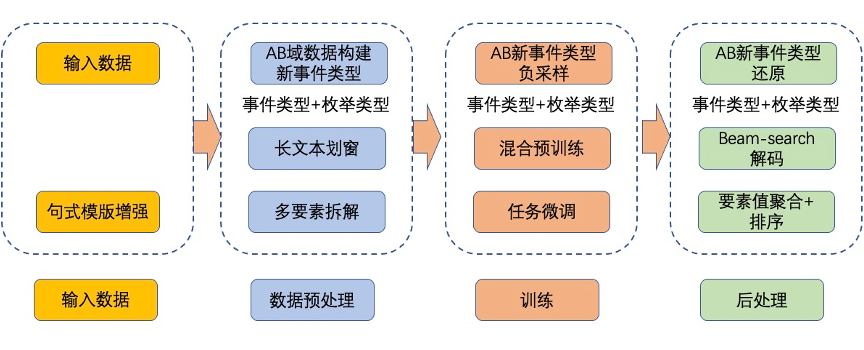
我们的系统方案
[{'要素类型':'v1','要素值':'u1'}, ..., {'要素类型':'v1','要素值':'un'}] 
结果
比赛分为两个阶段,选拔赛和决赛。
6.1 选拔赛
下表为选拔赛结果:
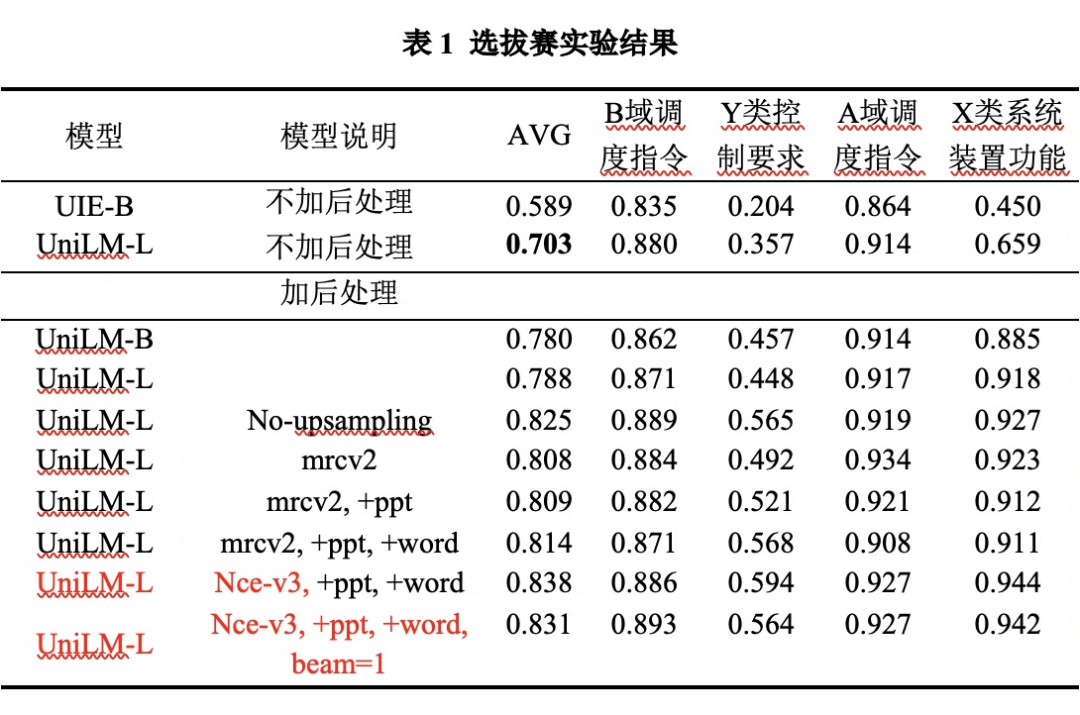
选拔赛阶段,我们对比了百度 UIE-MRC-Base [18],在前期均不使用后处理的条件下,我们的 UniLM-UIE-Large 线上即可取得 0.703 的效果,远超 UIE-MRC-Base 的 0.589,以及官方 baseline 的 0.49。这里,由于评估指标为完整事件元组的评估,UIE-MRC 可以较好地完成给定类型的值抽取,但难以对抽取结果合理划分事件(如果数据集句式特殊,可能可以根据句式组合配对,但实用性较窄且方案不够简洁)。
-
数据复制,数据均衡采样; 加入 官方答疑视频 ppt 中的数据以及官方 word 文档里面的数据;
测试不同的 beam-search-size。

同时,V3 版本 - no-upsampling 可以实现单模型 0.825 的效果。这里,我们可以看到,由于少样本场景,数据输入的顺序可能对模型效果产生较大影响 [27],使用均衡采样可以降低数据输入顺序对训练的影响。
全量抽取数据集+电力数据:实现了 A 和 B 的最佳结果,X 和 Y 下降 10 几个点;
AB 单独训练,XY 单独训练:实现了 X 的最佳结果;
注:top2-4 均为电力行业背景团队如国家电网(主办方单位),南方电网,国电南瑞等:
任务有监、无监督数据+全量信息抽取数据集的 task-prefinetuning;
任务有监督数据的 task-finetuning;
少样本数据集 duplicate 10 份;
少样本数据均衡采样;
可能可以在一周内实现该比赛的最佳单模型以及最佳模型组合结果。
6.2 决赛
-
拓展前缀词。如拓展“功能依据”的前缀:根据、按照、依据; 拓展句式模板。功能依据+命令信息内容;
拓展句式模板。命令信息内容+功能依据;
加入易混淆数据。官方 word,ppt 易混淆数据构造;
多条件构造,句号分割--->不同的元组;
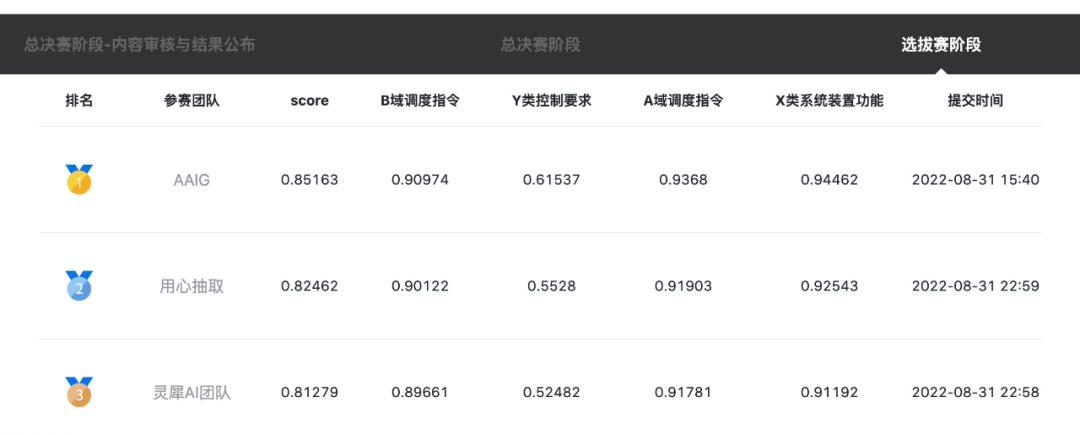
决赛结果如下:
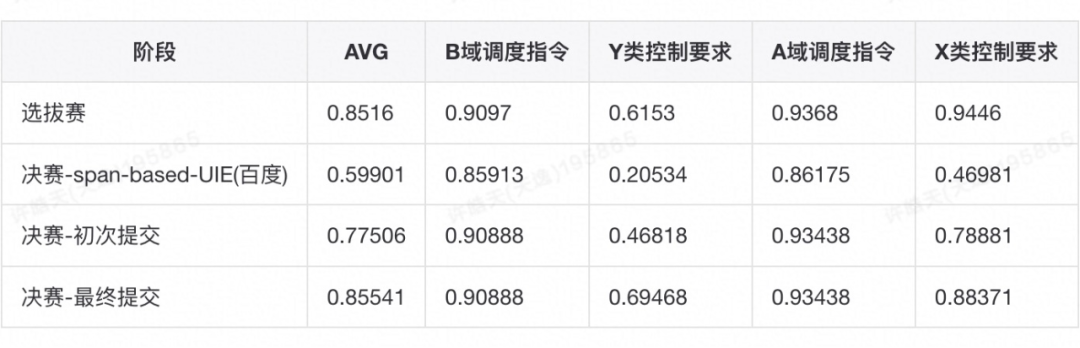
决赛阶段,我们看到,UIE-MRC-Base 依然只有 0.5991 的效果,而我们的选拔赛最佳模型可达到 0.775 的结果;后续,我们也评测了选拔赛最佳单模型 0.838 在决赛数据集的效果:

可以看到,选拔赛最佳单模型与选拔赛最佳结果相差很小。相比选拔赛结果,决赛结果的 Y 和 X 下降较多,也说明了决赛数据和选拔赛数据可能在句式、实体层面存在较大的 GAP。最后,我们使用上述提到的数据增强(基于训练集 500 条样本),使得最终结果从 0.772 提升到 0.85541:

注:决赛 9.2 开始后仅一天(9.3)即可达到,也充分验证了 UniLM-UIE 强大的拟合能力。

总结
基于 task-prefinetuing,我们的 UniLM-UIE 能够从海量数据中学习抽取逻辑,即使面对垂直行业如电力行业,没有大量的无监督数据、以及行业背景等不利条件下,我们也能够借助 UniLM-UIE 从其他数据集学习到的抽取能力,实现优异的领域迁移效果,为垂直行业知识图谱构造等提供了新的方案和可能性,同时,保持整个抽取系统的简洁性。

生成式解码速度慢、schema 遍历慢,实际中可以使用更快的解码框架如 [22,23];
生成 token 序列,缺少 token 位置信息,对于基于位置信息评估的应用或者比赛,位置回标 可能存在 遗漏、重叠等问题;
长文本划窗处理,不同窗内的解码元组结果较难合并;
schema 顺序、目标序列的顺序对模型有影响 [10] 如数据多可能避免过拟合,数据少可能欠拟合等;
-
相比 MRC、word-pair 等方式,生成式仅有目标解码序列的似然值,难以通过阈值筛选等操作对解码结果做筛选和修正;

未来工作
此外,我们也正在基于旋转位置编码的 roformer [25] 进行 bert 词表的预训练、UniLM-UIE 的完整训练流程,使得 UniLM-UIE 可以支持更长的文本序列,同时,可能也能提升效果如 GLM [17]。

UIE 可能本身很难做到零样本的迁移,而基于少量数据的 UIE+task-prefinetuning 的训练流程,是有可能实现垂直行业的快速领域适配。同时,结合大模型,可预计会达到更好的抽取效果。对于垂直行业,可以提供一个更简洁的方案,而如果想做一个模型在不同场景都通用,可能存在几个问题:
不同领域的抽取难度不同,生成式抽取对于多任务建模不需要引入额外参数,而输入数据的顺序、数据复制的比例、数据采样策略等对不同任务和数据集有不同的影响。比如笔者尝试将所有有监督抽取数据集合并训练,在电力选拔赛的 X 和 Y 上面下降 10 几个点;
不同的抽取任务需要的抽取能力不同,多个数据集混合训练,很可能使得模型产生 “抽取能力 bias” 即对于某些 pattern、schema 的抽取偏好,降低其在其他数据集的抽取效果;
多模态、NLP、CV、ASR 等都在走 Unified 的路径,可以极大降低模型碎片化的问题,集中力量办大事。

参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编



