乘风破浪的Seq2Seq模型:在事件抽取上的应用

©PaperWeekly 原创 · 作者 | 王增志
单位 | 南京理工大学硕士生
研究方向 | 情感分析与观点挖掘

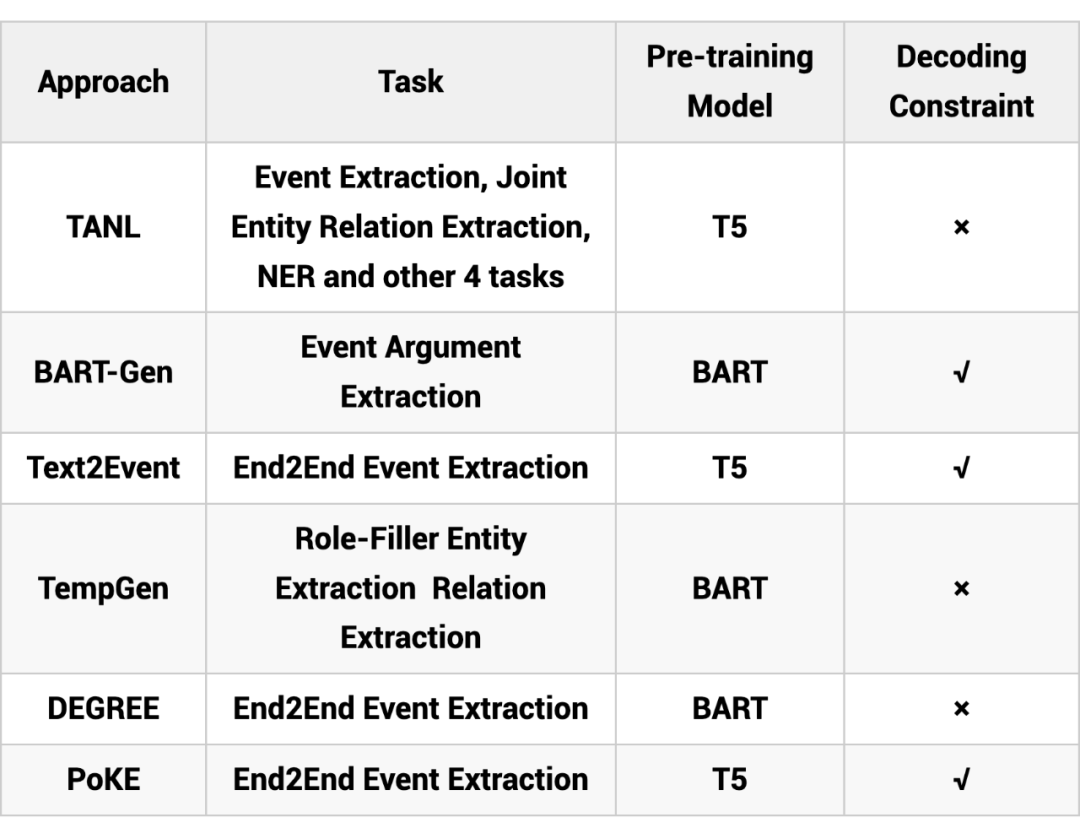
2020 年自然语言处理方向出现了很多令人印象深刻的工作, 其中就包括了这一系列 Seq2Seq 大规模预训练语言模型,比如 BART [1],T5 [2] 和 GPT-3 [3],直觉上这些生成模型一般会用于摘要和翻译这种典型的生成任务,2021年的很多工作开始尝试利用这些强大的生成模型来建模一些复杂的自然语言理解任务,比如命名实体识别,属性级情感分析和事件抽取任务等等。本文将会按照时间线简要对基于生成式方法的事件抽取相关的工作进行梳理。
Input: The man returned to Los Angeles from Mexico following his capture Tuesday by bounty hunters.
Output:

该任务分为如下几个子任务:
Trigger Identification:检测(抽取)句子中的事件的触发词,可以是一个词也可以是一个span;
-
Trigger Classification:判断抽取到的触发词对应的事件类型; -
Argument Identification:检测(抽取)句子中的论元比如某种事件发生的时间,地点等; -
Argument Classification:判断抽取到的论元对应的论元角色;

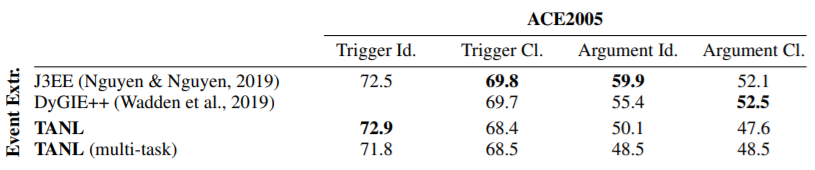
这是一篇来自 AWS 团队 ICLR 2021 的工作 [4],作者致力于研究结构预测任务(比如命名实体识别,实体关系抽取,语义角色标注,共指消解,事件抽取,对话状态追踪等)的多任务学习,之前的大多数方法都是针对具体的特定的任务进行建模,训练一个任务特定的判别器,但是这样的方法一方面结构不能被适配到其他类似的任务上,给迁移学习带来了困难,另一方面这种判别式的结构很难利用标签的语义知识。
基于此,作者提出了 TANL 模型(Translation between Augmented Natural Language),即给定输入,输出原有文本和对应的文本标注。如下图所示,输入文本,输出的文本在原文本的上做了 augmented,即加上了标注,图中的实体关系联合抽取任务,会在头实体上加上对应的实体类别,在尾实体上除了加上实体类型,还会加上关系,以及对应的头实体 span;语义角色标注任务,模型会标注出主语,谓语,时间地点等;共指消解任务,模型会标注出所有的第一个 mention,然后在后续出现的 mention 上标注对应的本体,最后对输出的文本进行解析,得到预测的结构。



这是一篇发表在 NAACL 2021 [7] 的工作,针对常见的句子级的任务存在信息不完整的问题,作者研究文档级的事件论元抽取任务,并将其建模为按照事件模板进行生成的形式。同时作者还提出了一个文档级的事件抽取 Benchmark: WIKIEVENTS,并且包含了完整的事件和共指标注。
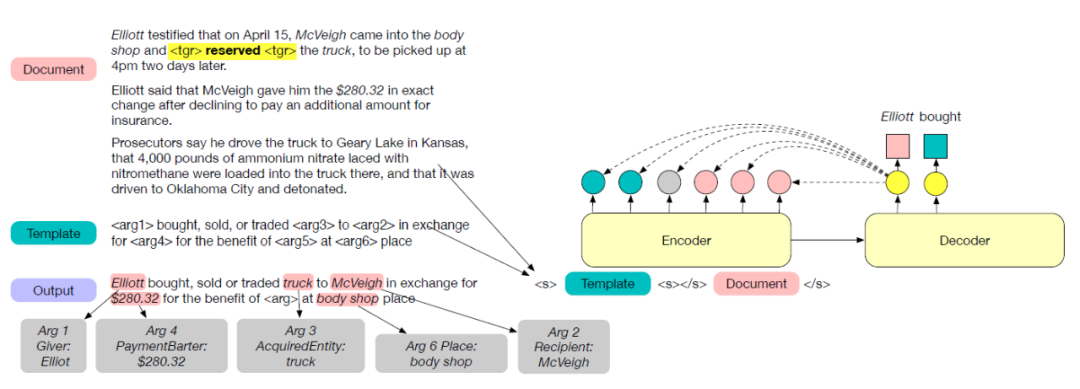
上述只是提到了事件的论元抽取,但是模型的输入需要含有对触发词的标注,故此作者提出了一个基于关键词的触发词抽取方法(抽取触发词和对应的类型),不用于常见的全监督的 setting,这里只提供关键词级别的监督,即针对每个类别,提供几个描述该类别的词汇,作为监督信号,然后通过 BERT 获得关键词的平均词向量作为类别的表示,然后使用 BERT-CRF 模型和 IO 的标注方案,对 CRF 中的特征/发射分数和转移分数进行了一定的改动(毕竟没有完整的标注信息)。
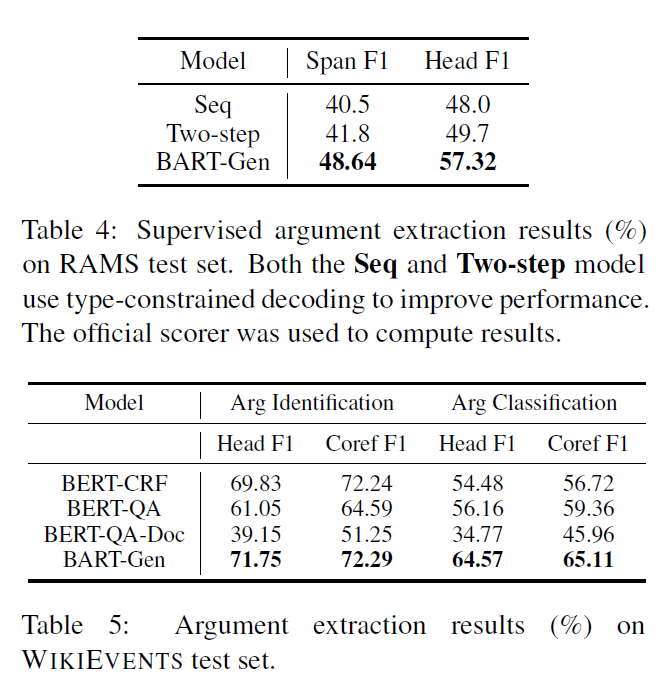

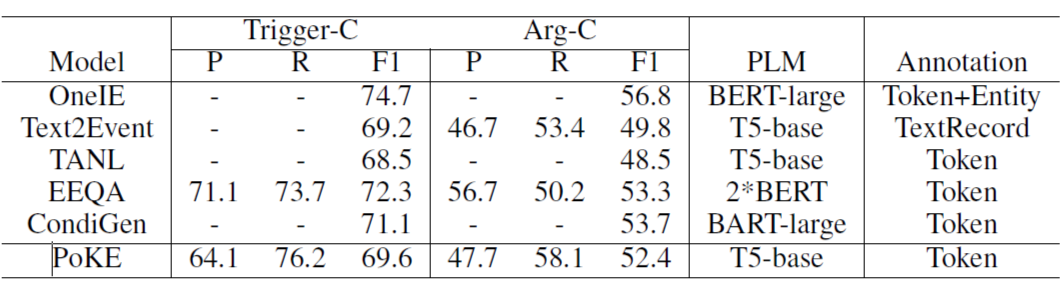
这是一篇发表在 ACL 2021 [9] 上的一个工作,之前的事件抽取的工作主要是将任务拆解成几个子任务分开来解决,在这个工作中作者提出模型 Text2Event,将事件抽取建模成 Seq2Seq 的形式,输入句子,输出结构化的事件。下面是一个输入输出的例子,输出的结构格式为 ((事件类型 触发词 (角色 论元)) ...),然后对输出的文本进行解析就可以得到结构化的事件。
-
Input: The man returned to Los Angeles from Mexico following his capture Tuesday by bounty hunters. -
Output: ((Transport returned, (Artifact The man), (Destination Los Angeles), (Origin Mexico)), (Arrest-Jail capture (Person The man), (Time Tuesday) (Agent bounty hunters))
为了避免使用生成模型(T5)直接生成这种非自然的句子过于困难,作者使用课程学习的思路,先去训练做简单的子任务比如生成(type, trigger words)和(role, argument words)这种相对简单的格式,最后再去训练学习直接生成完整的事件抽取任务的句子格式。

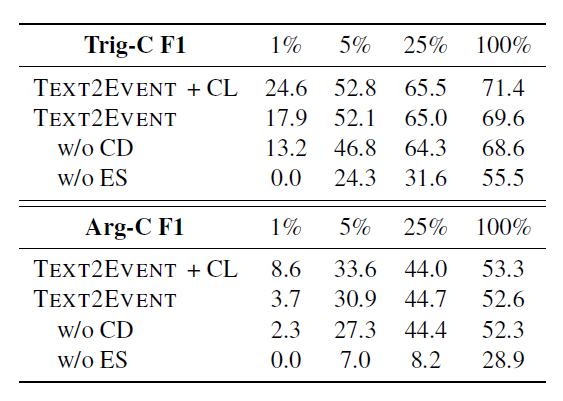

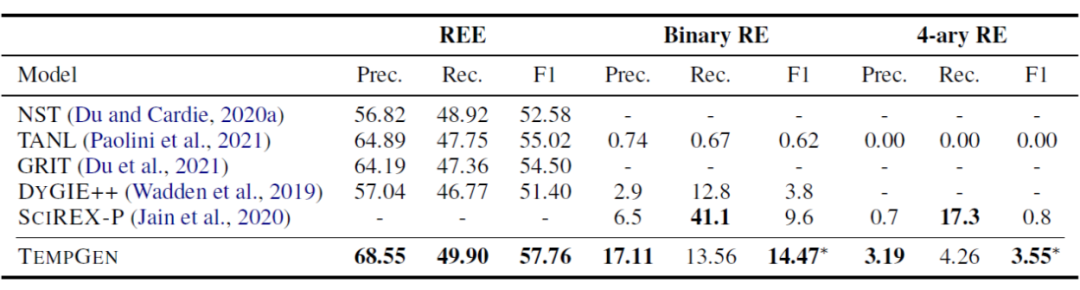
这是一篇发表在 EMNLP 2021 [10] 上的工作,虽然做的任务不是事件抽取,但是任务形式上跟事件抽取很像。该工作通过将文档级的角色填充的实体抽取(role-filler entity extraction (REE))和关系抽取任务转换成 seq2seq 的形式来解决在对文档级建模存在的实体间长程依赖问题。
任务形式如下图所示:针对 REE 任务,使用预先定义的模板,<SOT> 和 <EOT> 表示模板的开始和结束,<SOSN> 和 <EOSN> 表示 slot name 的开始和结束,<SOE> 和 <EOE> 表示实体的开始和结束;针对关系抽取任务,同样使用以上类似的模板。


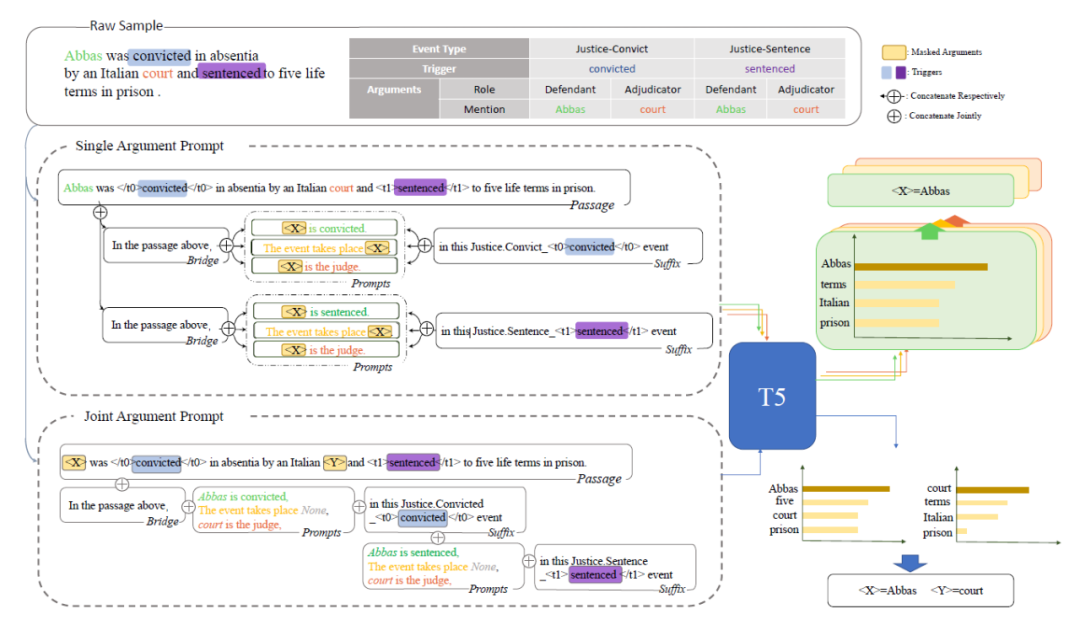
该工作 [11] 也是类似的做法,是采用生成式的方法利用 Prompt 去生成预定义的模板。这样做可以融入标签的知识,而且还是一种端到端的设计,模型能够捕捉到触发词与论元之间的依赖。模型如下图所示:整体的思路是给定模型 passage 和事件类型,然后将 passage 和对应的 prompt 拼接到一起,然后模型按照模板生成,最后从生成的模板中解析事件。
首先考虑事件检测任务(Event Detection),我们将给定的事件类型对应的描述和事件关键词,还有生成的事件检测的模板 'Event trigger is <Trigger>' 以上内容作为 Prompt 跟 passage 拼接到一起,模型将会把 trigger 词填充后的模板输出出来。针对事件论元抽取任务,对应的 Prompt 是事件类型的描述,和第一步检测出来的触发词,还有针对论元抽取设计的模板,模型将会输出用 passage 中的词填充过的模板。以上是一种 Pipeline 的方法,Joint 的方法的就是将事件类型的描述,事件的关键词,还有针对端到端设计的生成模板(如下图最下方),最终按照模板生成。

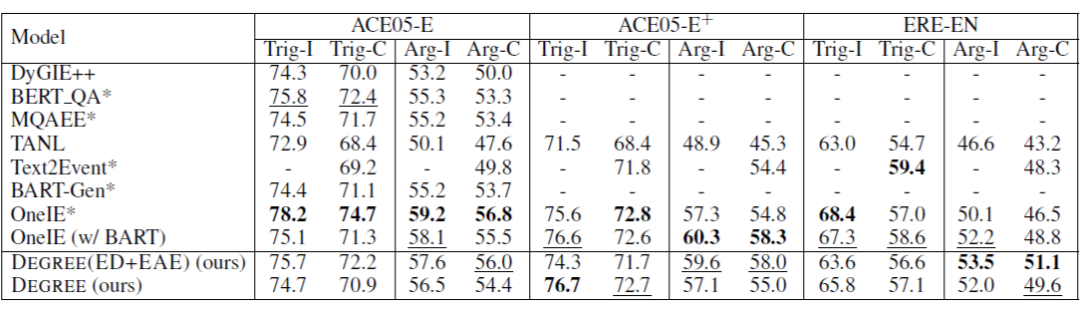
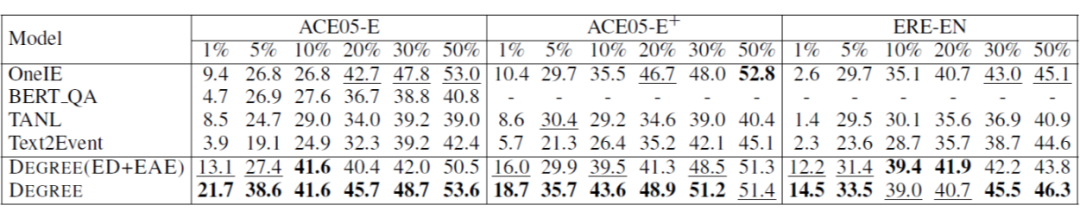

该工作 [12] 同样也是利用 Prompt 做事件抽取任务,之前的 Prompt 相关的工作大多基于简单的文本分类任务,对于事件抽取这样复杂的任务还很少被被探究过,作者使用 Prompt 来探测语言模型中的知识。
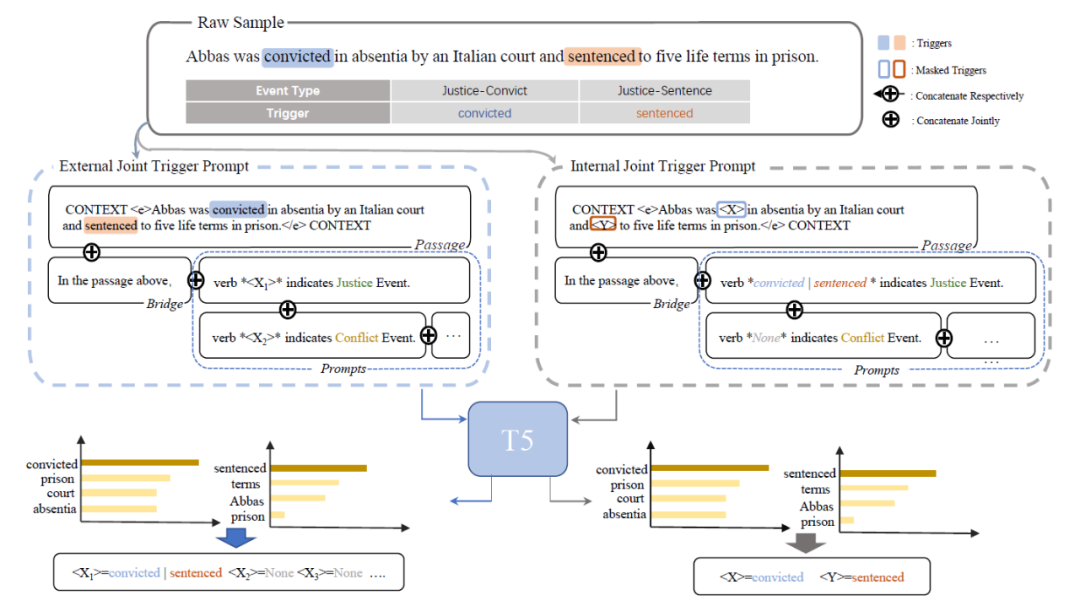
PoKE 模型用于事件检测任务的模型结构如下图所示,Prompt 分为两部分一部分是 external 的,一部分是 internal 的,这个主要是看 mask 的地方是在 passage 内部还是在添加的 prompt 上。具体来说针对 External 的 Prompt,在 passage 后面拼接上桥接词 'In the passgae above',还有针对每个事件类型的 Prompt (格式为:verb <X> indictates xxx Event)然后送进 T5 中预测 mask 处的词。为了帮助模型更好地理解,作者还使用了 internal 的 Prompt,内容上跟前者一样,只是在前者 mask 的地方填上正确的 trigger 词,反而将上下文中的 trigger 词 mask 掉,然后送入 T5 预测。
本质上这样做的动机还是靠近T5的预训练任务,更好地探测和利用模型。


参考文献
[1] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. ACL 2020
[2] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. PMLR 2020
[3] Language Models are Few-Shot Learners.
[4] Structured Prediction as Translation between Augmented Natural Languages. ICLR 2021
[5] Augmented Natural Language for Generative Sequence Labeling. EMNLP 2020
[6] Towards Generative Aspect-Based Sentiment Analysis. ACL 2020
[7] Document-Level Event Argument Extraction by Conditional Generation. NAACL 2021
[8] Event Extraction by Answering (almost) Natural Questions. EMNLP 2020
[9] TEXT2EVENT: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction. ACL 2021
[10] Document-level Entity-based Extraction as Template Generation. EMNLP 2021
[11] DEGREE: A Data-Efficient Generative Event Extraction Model. ArXiv 2021
[12] Eliciting Knowledge from Language Models for Event Extraction. ArXiv 2021
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



