【泡泡图灵智库】MapNet:一种便于动态更新的全局地图存储方法(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:MapNet: An Allocentric Spatial Memory for Mapping Environments
作者:Jo˜ao F. Henriques,Andrea Vedaldi
来源:CVPR 2018
编译:皮燕燕
审核:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,MapNet:一种用于环境地图的非自我中心空间存储器,该文章发表于CVPR 2018。
智能代理需要通过他们实时的传感器信息推理得到所处世界的信息。然而,随着时间的推移,信息集成需要从自我中心坐标系表达得地图转到非自我中心坐标系表达的地图中,即在世界坐标系中表示。同时通过在世界坐标系中定位和配准传感器实现动态更新表示。该论文开发了一个满足这些要求的可靠、高效的,同时适合集成到端到端深度网络中的微分模块。该模块包含一个非自我中心空间存储器,可以通过向其提供当前的传感信息来进行关联访问,从而获得位置信息,然后使用LSTM或类似的机制进行更新。该论文将传感器的有效位置信息以及配准信息定为内存空间中的双卷积/反卷积算子。地图本身是存储深度神经网络模块学习从RGBD输入中提取的信息的环境的2.5D表示。结果是一张包含多任务信息的地图,与传统的绘图方法(如运动结构)不同。论文使用合成迷宫,经典游戏Doom的录制游戏数小时的数据集和最近从机器人捕获的真实图像的Active Vision数据集来呈现结果。
主要贡献
1. 论文通过允许特征提取网络针对非自我中心空间存储器动态地重新布线。实现了模型同时包括自我中心和非自我中心信息。
2.该论文确定世界地图用2.5D表示,同时允许深度神经网络自动学习应从图像中提取的信息,并存储在特征向量中,以最大化重新定位的精度。
算法流程
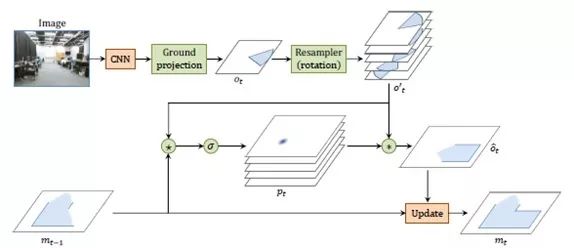
图1 论文通过卷积算子在空间存储器上
进行定位和配准。
第一步:定位模块的作用是确定t时刻相机在非自我中心世界地图中的位置和方向。
第二步:配准。将t时刻的位姿观测量ot整合到地图中。
第三步:更新。采用LSTM方法对mt-1进行更新。
第四步:投影。将RGBD图像信息,投影到3D空间中表示的ot中。
第五步:训练及定义损失函数。目标是每步计算中的估计位置和方向的负对数概率最小化。。
主要结果
文章结果:
1.1 基于合成迷宫的运行结果
论文通过随机深度优先搜索产生了100,000个随机迷宫(如图2所示),产生21 ×21个二进制占用图。 5,000个迷宫用于验证,其余的用于训练。

图2 在100,000个迷宫的合成数据集上可视化拥有五个框架的4个迷宫。 左:地面真实环境和轨迹(红色)。 中:观察相机空间(即旋转的,以轨迹为中心的环境局部视图)。 右图:位置预测的热图(更明亮意味着更高的置信度)以及相应的实际位置(红色表示)
用于解码试验的地图如图3所示。结果如图4所示。结果表明作为自主定位的副作用,地图嵌入确实对环境的可识别方面进行了编码。

图3 可视化地图解码实验中使用的数据。 这些类型是:走廊(白色),转弯(蓝色),死胡同(红色),丁字路(黄色)和十字路口(紫色,仅在倒数第二张图中可见,因为这是罕见的事件)

图4 图3中所示的语义类别的二进制分类器的准确度,表明地图嵌入与语义相关(随机概率为50%)。最后一列为一对一精度
1.2 基于3D游戏录制数据的运行结果
不同方法处理不同长度Doom游戏的数据的APE以及ATE结果进行了对比,对比结果见图5。结果表明论文提出的MapNet尽管使用了较少的LSTM单元,但对于大多数长度的数据而言定位精度更高。对于较长的数据而言各种方法的处理结果收敛于一点。 对于长期的数据处理结果来件,明确的空间记忆匹配似乎是最有用的,因为简单的测距累积了太多的错误。 正如预期的那样,添加光流式线索(MapNet-F)具有积极影响。 图6显示了定性结果。
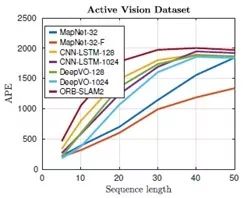
图5 不同方法处理不同时长数据的
平均定位误差(APE)

图6 基于游戏Doom数据的运行结果
1.3 基于真实数据的运行结果
对不同方法处理Active Vision数据集的数据进行了比较,比较结果如图7所示。相比ORB-SLAM2这种传统的SLAM方法,在处理低帧频的AVD数据集,论文提出得算法对所有(平面)姿势执行完全匹配每一帧,从而可以应付大位移,因此得到的结果较好。
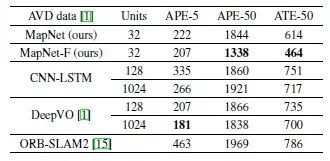
图7 不同方法处理Active Vision数据集的绝对轨迹误差(ATE)、5帧平均定位误差(APE-5)、50帧平均定位误差(APE-50)。图中数据的单位是mm
(每帧数据的步长是300mm)。
同时MAP-NET处理结果所的得APE-5与单元离散化的尺寸(300mm)量级相同,表明细化的离散化可能会改善结果,但会增加计算量。相应的结果如图8所示。

图8 基于Active Vision数据集的运行结果

Abstract
Autonomous agents need to reason about the world beyond their instantaneous sensory input. Integrating information over time, however, requires switching from an egocentric representation of a scene to an allocentric one, expressed in the world reference frame. It must also be possible to update the representation dynamically, which requires localizing and registering the sensor with respect to the world reference. In this paper, we develop a differentiable module that satisfies such requirements, while being robust, efficient, and suitable for integration in end-to-end deep networks. The module contains an allocentric spatial memory that can be accessed associatively by feeding to it the current sensory input, resulting in localization, and then updated using an LSTM or similar mechanism. We formulate efficient localization and registration of sensory information as a dual pair of convolution/deconvolution operators in memory space. The map itself is a 2.5D representation of an environment storing information that a deep neural network module learns to distill from RGBD input. The result is a map that contains multi-task information, different from classical approaches to mapping such as structurefrom-
motion. We present results using synthetic mazes, a dataset of hours of recorded gameplay of the classic game Doom, and the very recent Active Vision Dataset of real images captured from a robot.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




