【泡泡一分钟】一种用于在线视频理解的高效卷积网络
每天一分钟,带你读遍机器人顶级会议文章
标题:ECO: Efficient Convolutional Network for Online Video Understanding
作者: Mohammadreza Zolfaghari, Kamaljeet Singh and Thomas Brox
来源: Submitted to ECCV 2018
播音员:堃堃
编译:李建华
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——利用卷积神经网络高效实现在线视频的理解,该文章待发表于ECCV 2018。
当前视频理解技术存在两个问题:1)理解主要在视频的局部进行,忽视了时间跨度达几秒的动作其实存在内在联系。2)尽管局部处理方法具有快速的单帧处理速度,但整个视频的处理效率并不高,限制了其在快速视频检索或持续时间较长的行为分类中的应用。
在本文中,我们介绍了一种考虑视频内容全局性的网络架构,可以实现快速的视频理解。该架构将网络中已有的全局内容直接进行合并处理,而不是单独处理再进行事后的融合。此外,本架构采用的抽帧策略充分考虑到了相邻帧信息存在大量冗余这一特点。基于上述策略,本架构可以产生高质量的动作分类和视频描述,每秒最快可处理230个视频,每个视频由上百帧图像组成。该方法在所有的数据集上都有优异表现,而且处理速度比现有技术快10-80倍。
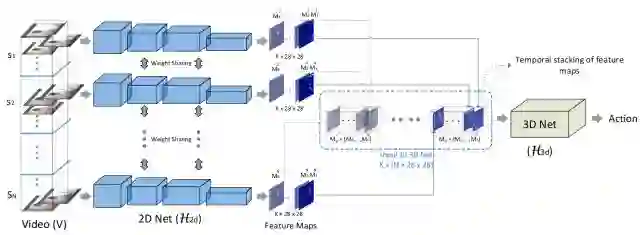
图1.本文提出的网络架构图。首先将视频分割为等大的N块(S1-SN),对每个视频块,从中随机抽取一帧图像,采用普通的二维卷积网络进行处理,得到图像的多个特征。再将所有视频块的特征按类打包成数据块,利用三维卷积网络进行处理,完成行为分类。本行为分类方法考虑到了行为的各个组成动作在时间上存在关联性的特点。
本文的主要改进点在于1)从视频全局进行抽帧处理,抽帧数固定,并利用了帧之间的内在联系进行行为分类,比局部处理方法获取的信息更全面。2)采用三维的卷积网络对抽帧数据进行端对端的处理,而不是传统的后处理方式。传统的方式先对各个抽帧图像单独处理打分,最后根据累加的得分给视频进行分类。3)网络直接输出视频级的处理结果,不需要后续的特征累加操作,处理速度更快,即使在运算能力弱的设备上,也可进行在线的实时处理。

图2 Something-Something数据集上的行为识别例子。在这个数据集中,相同的动作涉及到多个物体,与其它数据集相比,本数据集的行为识别更依赖于图像之间的关系。
此外,本文还提供了在线视频理解算法。在线的视频往往是一个视频流,开始处理时,并没有完整的视频数据,在处理的过程中,新的视频数据不断输入。传统的“视频窗”方法可以进行在线视频理解,但会丢失图像间的关联关系。如果考虑关联关系,又往往有较长的时间延时。
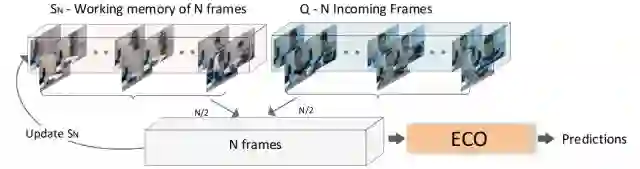
图3 本文提供的在线视频理解抽帧策略:待处理的N帧数据一半来源于工作内存中N帧图像,一半来源于视频流新进入的N帧图像,从这2N帧中均匀抽取N帧进行ECO处理。同时,将抽帧得到的N帧图像更新工作内存中的图像,新的视频流覆盖旧的视频流。上述过程不断迭代,输出新的处理结果。本抽帧策略,既可实时响应视频的最新变化,又利用了图像的前后内在关系,结果更加准确。

Abstract
The state of the art in video understanding suffers from two problems: (1) The major part of reasoning is performed locally in the video, therefore, it misses important relationships within actions that span several seconds. (2) While there are local methods with fast per-frame processing, the processing of the whole video is not efficient and hampers fast video retrieval or online classification of long-term activities. In this paper, we introduce a network architecture 1 that takes long-term content into account and enables fast per-video processing at the same time. The architecture is based on merging long-term content already in the network rather than in a post-hoc fusion. Together with a sampling strategy, which exploits that neighboring frames are largely redundant, this yields high-quality action classification and video captioning at up to 230 videos per second, where each video can consist of a few hundred frames. The approach achieves competitive performance across all datasets while being 10x to 80x faster than state-of-the-art methods.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


