基础 | 一文轻松搞懂-条件随机场CRF
阅读大概需要5分钟!
根据实验室师兄,师姐讲的条件随机场CRF,我根据我的理解来总结下。有什么疑问的尽管在评论里指出,我们共同探讨

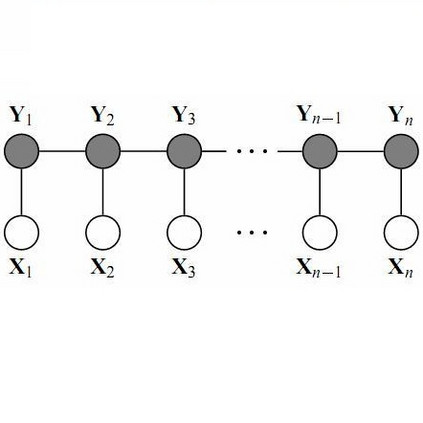
我们以命名实体识别NER为例,先介绍下NER的概念:

这里的label_alphabet中的b代表一个实体的开始,即begin;m代表一个实体的中部,即middle;e代表一个实体的结尾,即end;o代表不是实体,即None;<start>和<pad>分表代表这个标注label序列的开始和结束,类似于机器翻译的<SOS>和<EOS>。

这个就是word和label数字化后变成word_index,label_index。最终就变成下面的形式:

因为label有7种,每一个字被预测的label就有7种可能,为了数字化这些可能,我们从word_index到label_index设置一种分数,叫做发射分数emit:
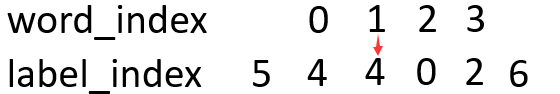
看这个图,有word_index 的 1 -> 到label_index 的 4的小红箭头,像不像发射过来的?此时的分数就记作emit[1][4]。
另外,我们想想,如果单单就这个发射分数来评价,太过于单一了,因为这个是一个序列,比如前面的label为o,那此时的label被预测的肯定不能是m或s,所以这个时候就需要一个分数代表前一个label到此时label的分数,我们叫这个为转移分数,即T:
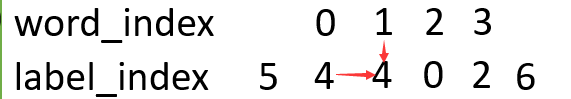
如图,横向的label到label箭头,就是由一个label到另一个label转移的意思,此时的分数为T[4][4]。
此时我们得出此时的word_index=1到label_index=4的分数为emit[1][4]+T[4][4]。
整体的score就为:
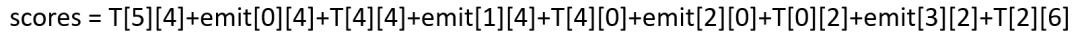
最后的公式为这样的:
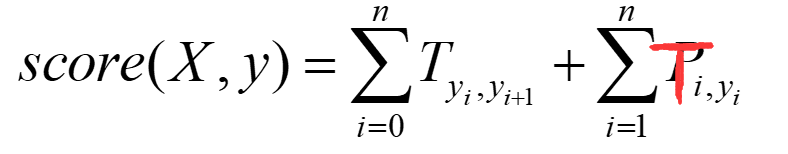
其中X为word_index序列,y为预测的label_index序列。
因为这个预测序列有很多种,种类为label的排列组合大小。其中只有一种组合是对的,我们只想通过神经网络训练使得对的score的比重在总体的所有score的越大越好。而这个时候我们一般softmax化,即:
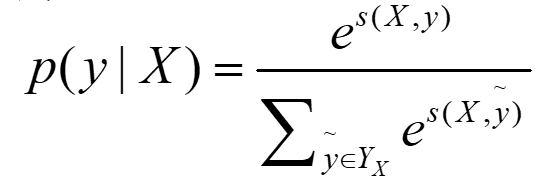
其中分子中的s为label序列为正确序列的score,分母s为每种可能的score。
这个比值越大,我们的预测就越准,所以,这个公式也就可以当做我们的loss,可是loss一般都越小越好,那我们就对这个加个负号即可,但是这个最终结果趋近于1的,我们实验的结果是趋近于0的,这时候log就派上用场了,即:
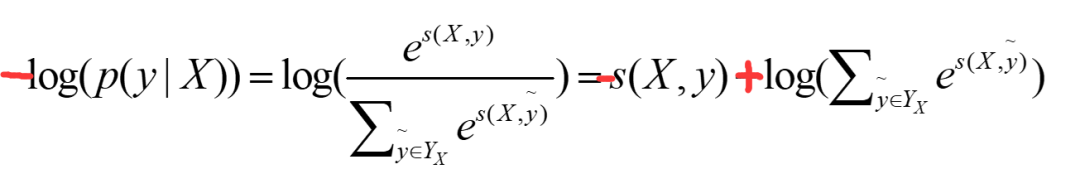
当然这个log也有平滑结果的功效。
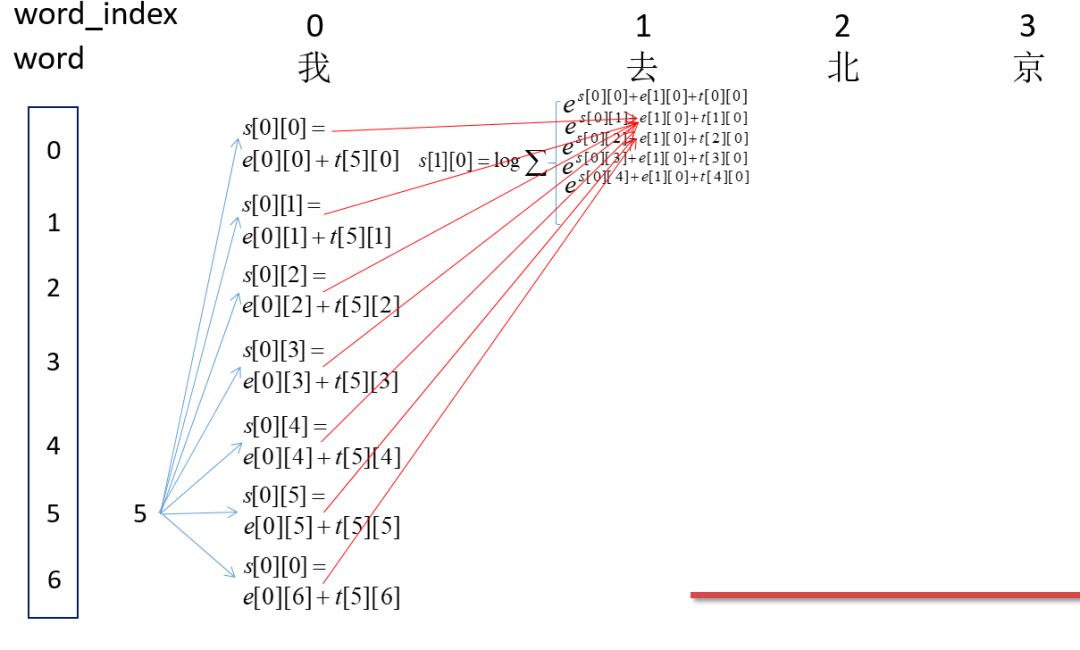
因为刚开始为<start>即为5,然后word_index为0的时候的所有可能的得分,即s[0][0],s[0][1]...s[0][6]。然后计算word_index为1的所有s[1][0],s[1][1]...s[1][6]的得分,这里以s[1][0]为例,即红箭头的焦点处:这里表示所有路径到这里的得分总和。
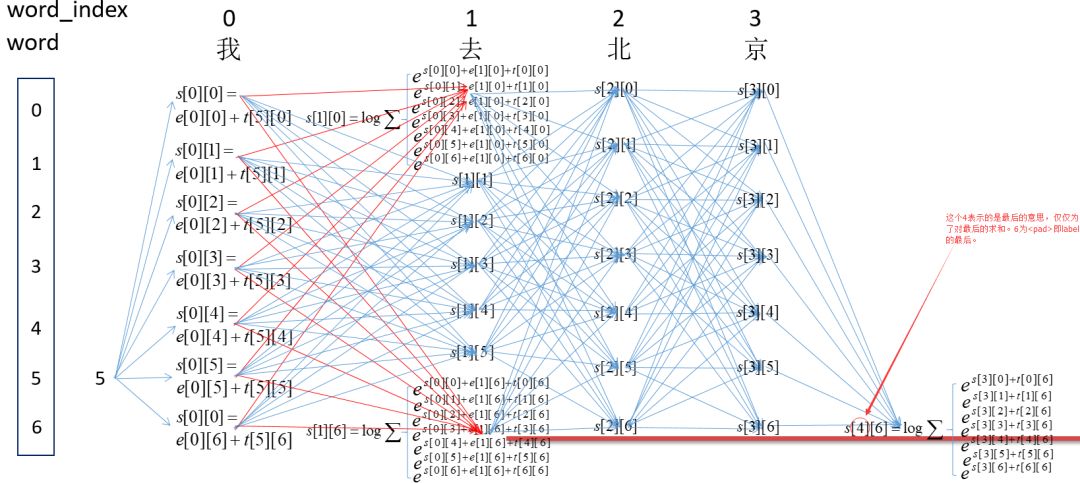
这里每个节点,都表示前面的所有路径到当前节点路径的所有得分之和。所以,最后的s[4][6]即为最终的得分之和,即:
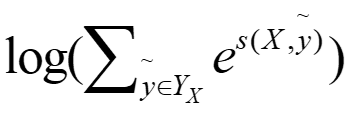
计算gold分数,即: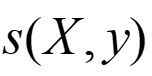
就是重复上述的求解所有路径的过程,将总和和gold的得分都求出来,得到loss,然后进行更新T,emit即可。(实现的话,其实emit是隐层输出,不是更新的对象,之后的实现会讲)
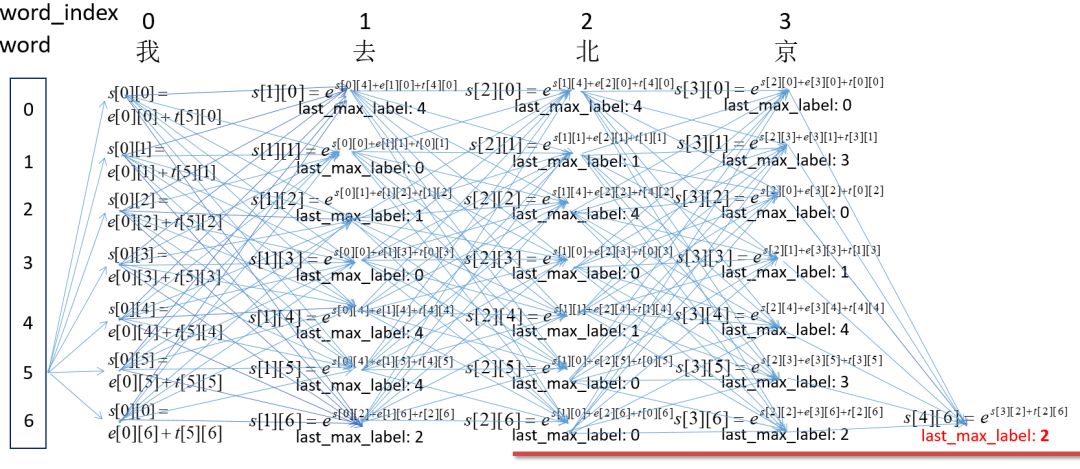
这个过程,就是动态规划,但是在这种模型中,通常叫做维特比算法。如图:
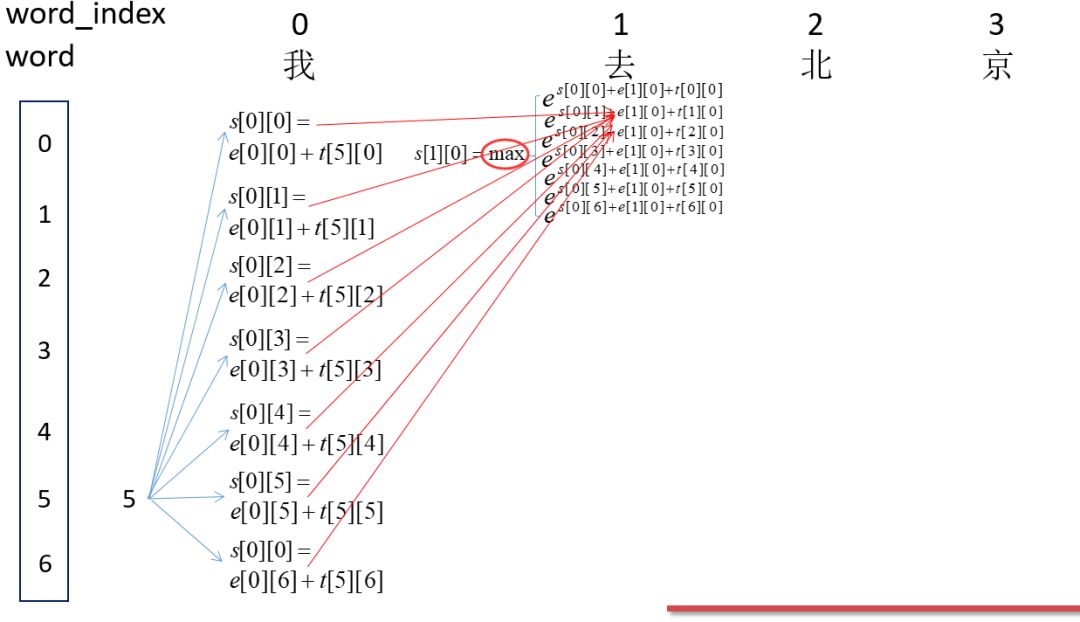
大概思路就是这次的每个节点不是求和,而是求max值和记录此max的位置。就是这样:

最后每个节点都求了出来,结果为:
最后,根据最后的节点,向前选取最佳的路径。过程为:
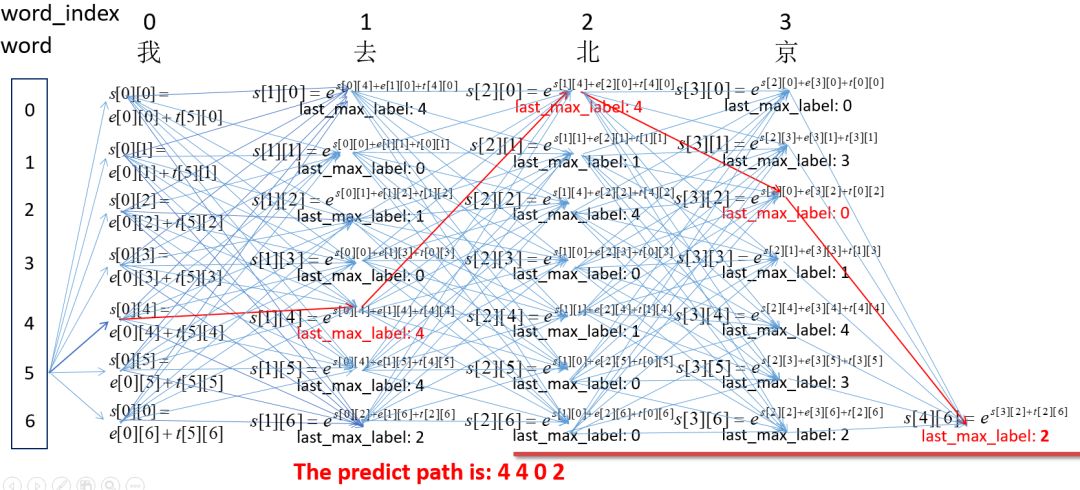
就这样,我们计算出来了预测路径。
此图来自于实验室宋阳师姐的ppt,真实精心制作!赞!也感谢师姐的耐心解答。