重磅!MobileNetV3 来了!
极市正在推出CVPR2019的专题直播分享会,邀请CVPR2019的论文作者进行线上直播,分享优秀的科研工作和技术干货,也欢迎各位小伙伴自荐或推荐优秀的CVPR论文作者到极市进行技术分享~
本周四(5月9日)晚,中科院自动化所模式识别国家重点实验室的张志鹏,将为我们分享
基于siamese网络的单目标跟踪(CVPR2019 Oral),公众号回复“41”即可获取直播详情。
作者 | CV君
来源 | 我爱计算机视觉
在现代深度学习算法研究中,通用的骨干网+特定任务网络head成为一种标准的设计模式。比如VGG + 检测Head,或者inception + 分割Head。
在移动端部署深度卷积网络,无论什么视觉任务,选择高精度的计算量少和参数少的骨干网是必经之路。这其中谷歌家去年发布的 MobileNetV2是首选。
在MobileNetV2论文发布时隔一年4个月后,MobileNetV3 来了!
这必将引起移动端网络升级的狂潮,让我们一起来看看这次又有什么黑科技!
昨天谷歌在arXiv上公布的论文《Searching for MobileNetV3》,详细介绍了MobileNetV3的设计思想和网络结构。

论文地址:https://arxiv.org/abs/1905.02244v1
先来说下结论:MobileNetV3 没有引入新的 Block,题目中Searching已经道尽该网络的设计哲学:神经架构搜索!
研究人员公布了 MobileNetV3 有两个版本,MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。
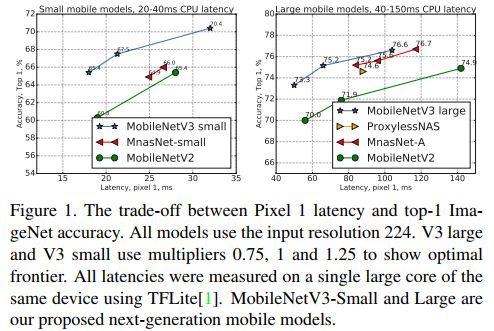
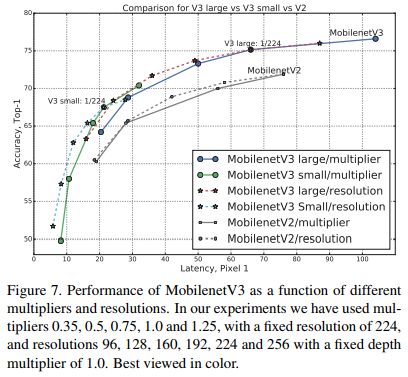
下图分别是MobileNetV3两个版本与其他轻量级网络在Pixel 1 手机上的计算延迟与ImageNet分类精度的比较。可见MobileNetV3 取得了显著的比较优势。
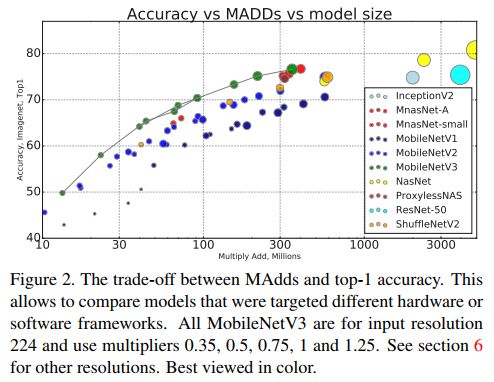
下图是ImageNet分类精度、MADD计算量、模型大小的比较,MobileNetV3依然是最优秀的。
高效的网络构建模块
前面已经说过,MobileNetV3 是神经架构搜索得到的模型,其内部使用的模块继承自:
1. MobileNetV1 模型引入的深度可分离卷积(depthwise separable convolutions);
2. MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck);
3. MnasNet 模型引入的基于squeeze and excitation结构的轻量级注意力模型。
这些被证明行之有效的用于移动端网络设计的模块是搭建MobileNetV3的积木。
互补搜索
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,后者用于对各个模块确定之后网络层的微调。
这两项技术分别来自论文:
M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le. Mnasnet: Platform-aware neural architecture search for mobile. CoRR, abs/1807.11626, 2018.
T. Yang, A. G. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In ECCV, 2018
前者相当于整体结构搜索,后者相当于局部搜索,两者互为补充。
到这里,我们还没看到算法研究人员的工作在哪里(启动训练按钮?)
继续往下看。
网络改进
作者们发现MobileNetV2 网络端部最后阶段的计算量很大,重新设计了这一部分,如下图:

这样做并不会造成精度损失。
另外,作者发现一种新出的激活函数swish x 能有效改进网络精度:
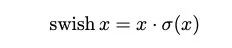
但就是计算量太大了。
于是作者对这个函数进行了数值近似:
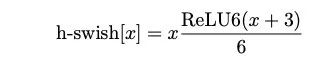
事实证明,这个近似很有效:
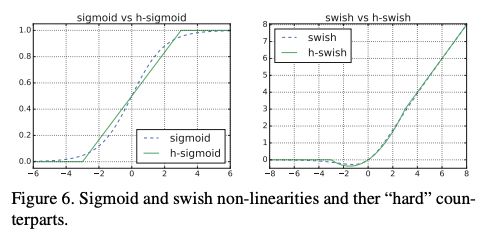
从图形上看出,这两个函数的确很接近。
MobileNetV3 网络结构!
这就是今天的主角了!
使用上述搜索机制和网络改进,最终谷歌得到的模型是这样(分别是MobileNetV3-Large和MobileNetV3-Small):
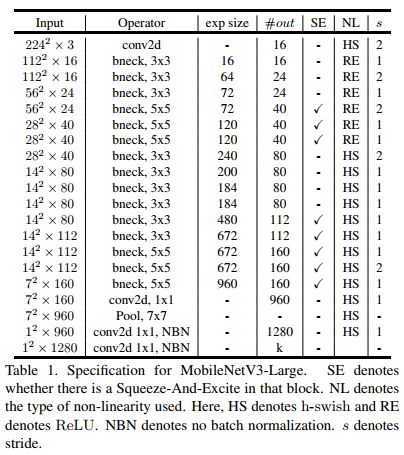
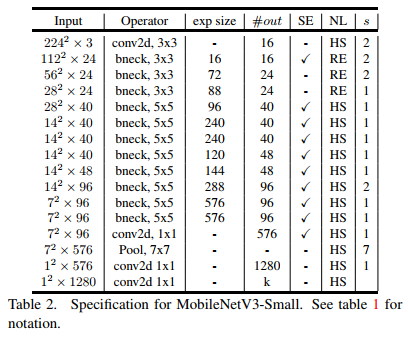
内部各个模块的类型和参数均已列出。
谷歌没有公布用了多少时间搜索训练。
目前谷歌还没有公布MobileNetV3的预训练模型,不过读者可以按照上述结构构建网络在ImageNet上训练得到权重。
实验结果
作者使用上述网络在分类、目标检测、语义分割三个任务中验证了MobileNetV3的优势:在计算量小、参数少的前提下,相比其他轻量级网络,依然在在三个任务重取得了最好的成绩。
下图是ImageNet分类Top-1精度、计算量、参数量及在Pixel系列手机实验的结果:
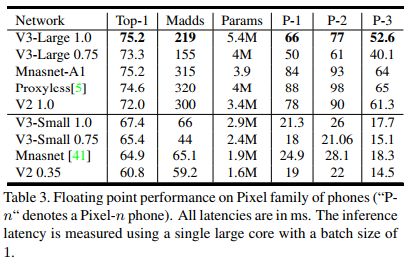
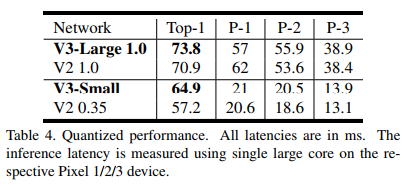
下图是与前一代MobieNetV2的比较结果:
这是使用其构筑的SSDLite目标检测算法在MS COCO数据集上的比较结果:
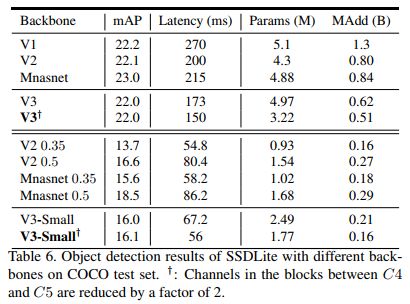
V3-Large取得了最高的精度,V3-Small 取得了V2近似的精度,速度却快很多。
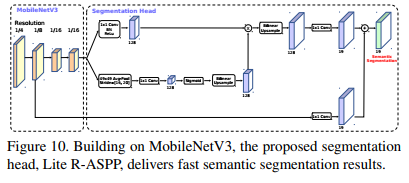
另外作者基于MobieNetV3设计了新的轻量级语义分割模型Lite R-ASPP:
下图是使用上述分割算法在CItyScapes验证集上的结果比较:
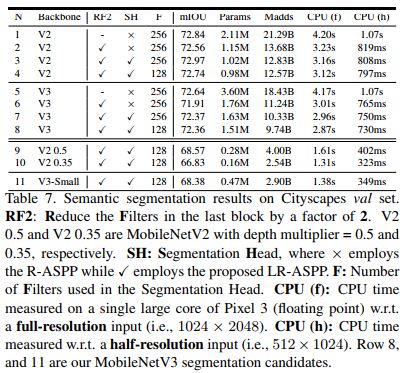
精度提升不明显,速度有显著提升。
下图是与其他轻量级语义分割算法的比较,MobileNetV3取得了不小的优势。
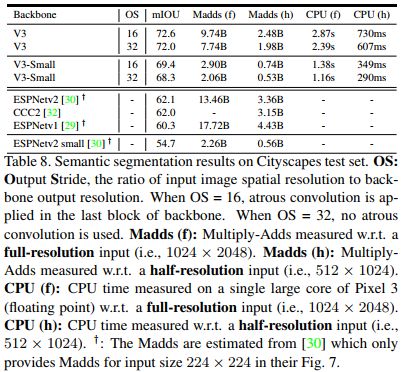
总结一下:
MobileNetV3-Large在ImageNet分类上的准确度与MobileNetV2相比提高了3.2%,同时延迟降低了15%。
MobileNetV3-large 用于目标检测,在COCO数据集上检测精度与MobileNetV2大致相同,但速度提高了25%。
在Cityscapes语义分割任务中,新设计的模型MobileNetV3-Large LR-ASPP 与 MobileNetV2 R-ASPP分割精度近似,但快30%。
期待谷歌早日将其预训练模型开源~
神经架构搜索火了,但感觉是不是算法设计也越来越乏味了。。。欢迎发表你的看法。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~


