CVPR2019 | 通过自适应的图卷积网络建模骨骼点数据进行行为识别
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:LShi
来源:https://zhuanlan.zhihu.com/p/69177318
已获作者授权,请勿二次转载
简介
在行为识别任务中,受制于数据量以及算法的制约,基于RGB图像的行为识别模型常常会受到视角的变化以及复杂背景的干扰,从而导致泛化性能不足,很难应用到实际生活中。而基于骨骼点数据的行为识别可以较好地解决这个问题。
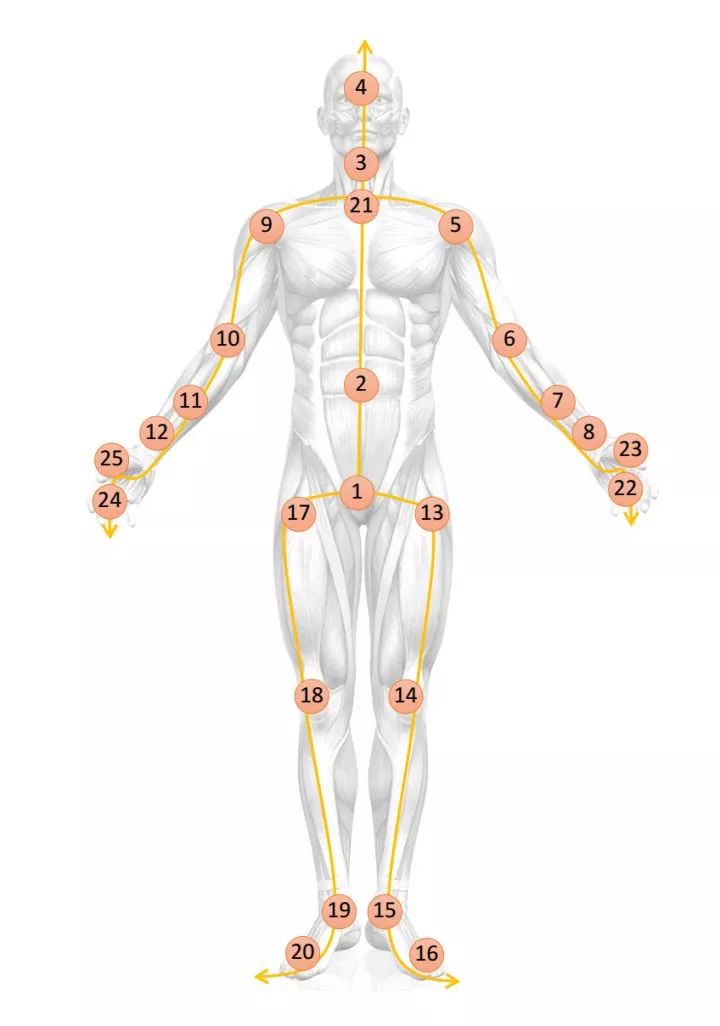
在骨骼点数据中,人体是由若干预先定义好的关键关节点在相机坐标系中的坐标来表示的。它可以很方便地通过深度摄像头(例如Kinect)以及各种姿态估计算法(例如OpenPose)获得。图 1是Kinect深度摄像机所定义的人体的关键关节点。它将人体定义为25个关键关节点的三维坐标。由于行为往往是以视频的形式存在的,所以一个长度为T帧的行为可以用Tx25x3的张量来表示。
相关工作
传统的基于骨骼点行为识别的深度学习方法主要分为基于RNN的和基于CNN的:基于RNN的方法将数据表示为三维向量的序列,然后利用LSTM等序列模型来建模;基于CNN的方法会人工设计一些规则把骨骼点数据转换成一张伪图像,然后利用图片分类中的模型进行对其识别。
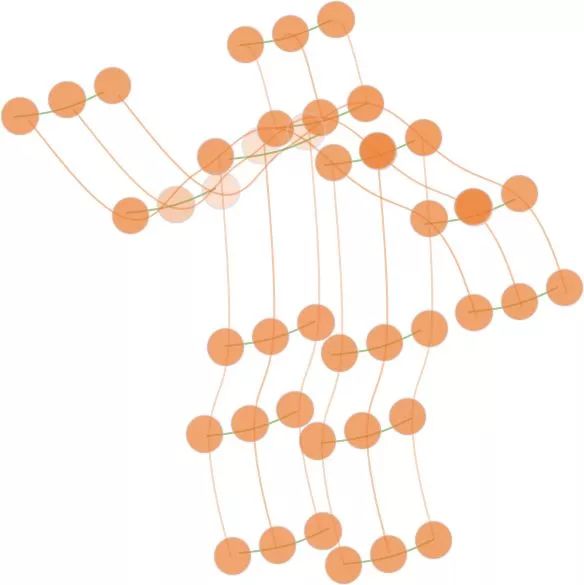
但其实骨骼点数据更自然地是一种图的形式。在AAAI2019的工作ST-GCN[1]中,作者将每个关节点定义为图的节点,关节点之间的物理连接定义为图的边,并且在相邻帧的同一个节点间加上时间维度的边,这样一个行为便可以由一张时空图(如图 2)来表示。
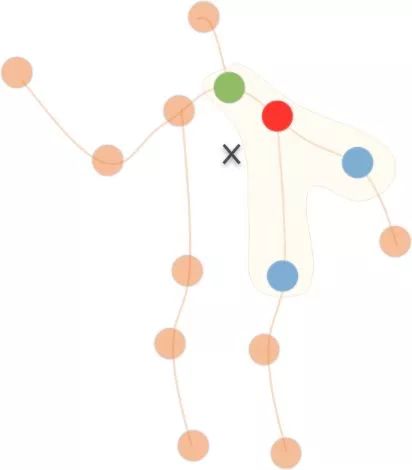
那么如何通过这张时空图来识别行为呢?作者提出采用图卷积的方式。和普通卷积操作不同,在图上做卷积时,每一个节点的邻节点数是不固定的,但是卷积操作的参数是固定的,所以需要定义一个映射函数来将固定数量的参数和不定数量的临节点数对应起来。这里作者定义卷积核大小为三,三个参数分别对应于远离人体中心(图 3 的X点)的点(图 3的蓝色点),靠近人体中心的点(图 3的绿色点)和卷积点本身(图 3的红色点)。
这样卷积操作就可以表示为:
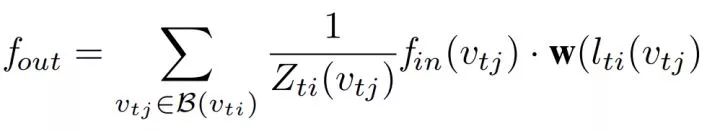
其中f是输入输出的特征张量,w是卷积参数,v是图中节点,l代表上述的节点与参数间的映射函数,Z是归一化函数。在具体实现时,映射函数可以通过图的邻接矩阵来实现,表示为:
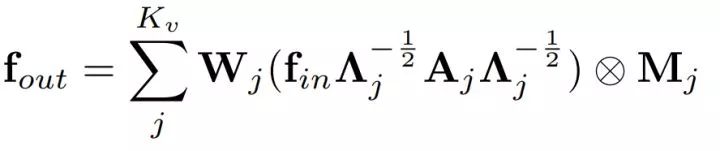
其中A代表图的邻接矩阵,K是卷积核大小。通过与邻接矩阵相乘,我们可以从特征张量中“筛选”出所需要的节点并与对应的参数相乘。
相关工作存在的问题
我们经过实验发现,ST-GCN的方法有两个缺陷:
ST-GCN中的图的拓扑结构是根据人体的物理结构定义的,这样定义的图并不一定适用于行为分类的任务。例如人体的两只手之前是没有物理连接的,在图中手之间的距离也会比较远。但是对于鼓掌这个行为,建模两只手之间的关系明显是更为重要的。另外,神经网络是多层结构,在不同的层中所包含的信息也是不同的。往往高层的网络会包含更偏向语义的信息,那么对所有的层使用相同拓扑结构的图也是不合理的。
在我们观察一个人的时候,相比于每个关节点的位置,人体各个肢体的方向,长度其实对于行为识别是更明显的特征。而在之前的工作中却都忽视了这一点。
我们的方法
为了解决以上两个问题,我们提出了一种双流自适应的图卷积神经网络来建模人体骨架并进行行为识别。
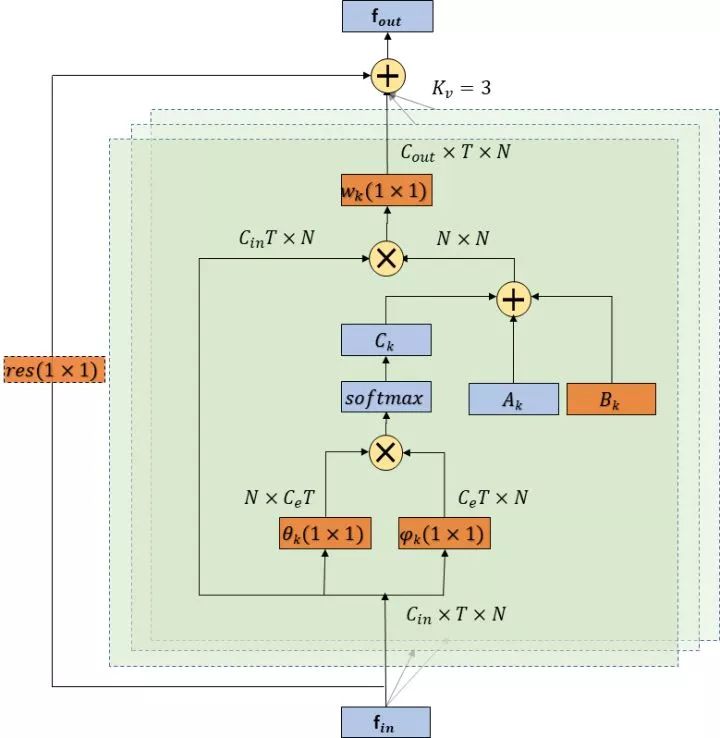
针对第一个问题,我们设计了一个自适应的图卷积层(图 4)。这里我们定义了三种图,其中A代表了根据人体物理结构定义的图,它对于所有的卷积层以及所有的样本都是相同的。B是根据数据库统计出来的适应于行为识别任务的图,它会作为网络的参数在训练过程中根据分类损失不断更新,它对于每一个卷积层都是不同的,但是对于不同样本是相同的。C是样本自适应的图,这里我们借鉴了双线性注意力机制的形式来设计[2], [3]。我们会首先将输入通过φ和θ函数降维映射到一个低维空间,然后通过相乘获得每两个点之前的特征相似性,然后将这个相似性矩阵通过softmax归一化作为最终的邻接矩阵。这个过程可以表示为:
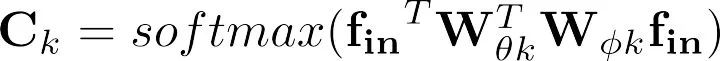
最终的自适应图卷积层可以表示为:
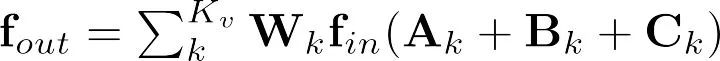
针对第二个问题,我们在实验中单独提取了人体骨骼的信息,表示为关节点之间的向量。借鉴了行为识别中常用的双流框架[4],我们将骨骼的信息使用另一个自适应图卷积神经网络来建模,然后将骨骼流(Bone)于关节点流(Joint)的softmax层分数融合来得到最终的分类结果。
实验结果
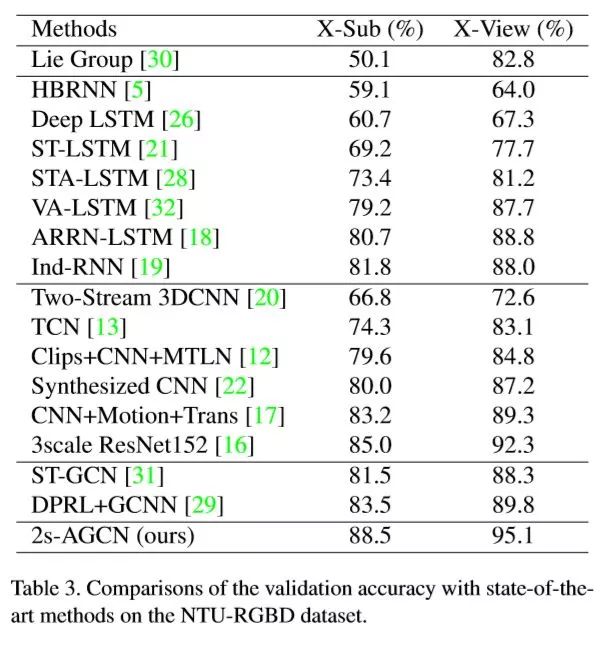
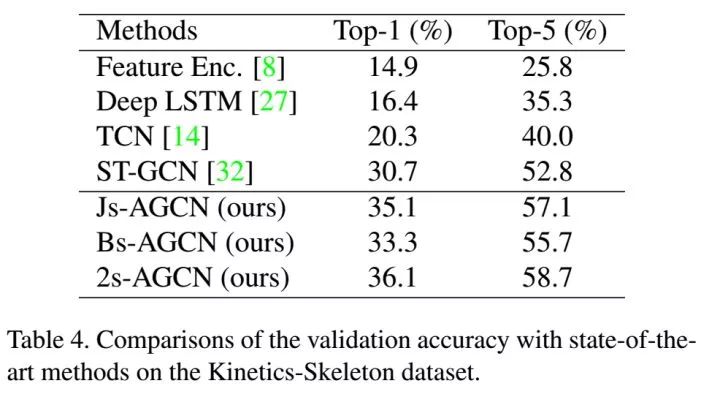
为了于ST-GCN比较,我们在NTU-RGB+D和Kinetics-Skeleton两个数据库上进行了实验。
由于骨骼点数据往往包含很多噪声,我们首先对数据进行了一些去噪操作,将基准值提升到了92.7。去噪操作分为四步:
1、基于骨架标识符将同一人体的骨架对齐:深度摄像头在检测人体骨骼点数据时会为每个人体分配一个body id,由于摄像头的误检,同一个人体在不同帧内可能会分配不一样的id。为了使人体的id具有一致性,在本算法中,我们会在每一次id消失的时候检测是否有新的id出现。如果有,就认为新的id是误分配,并把旧的id赋值给新出现的id。
2、基于骨架能量的过滤:骨骼点数据会经常出现误检,即把桌子椅子等物体检测为人体。为了过滤掉这些误捡,我们定义了一个骨骼点序列能量概念:即所有关节点的三维坐标在时间维度上标准差的平均值。由于物体通常是静止的,所以误检的物体的能量会低于人体的能量。我们会设定一个阈值过滤掉这些物体。
3、坐标数据归一化:为了统一数据的分布,减少人体中心在图像中的位置所带来地影响,简化模型训练过程。对于每一个序列,我们会以第一帧第一个人体的中心骨骼点为坐标系的原点,将其他帧归一化到这个坐标系中。具体做法就是将每个关节点的坐标减去这个中心点的坐标。
4、视角归一化:为了减少视角对于模型训练的影响,我们将每一帧的人体都旋转到一个固定的角度。具体方法是我们会以第一帧第一个人体为基准求一个旋转矩阵,使得这个人体的左肩与右肩连成的直线与坐标系的x轴平行,这个人体的脊柱与坐标系的z轴平行。
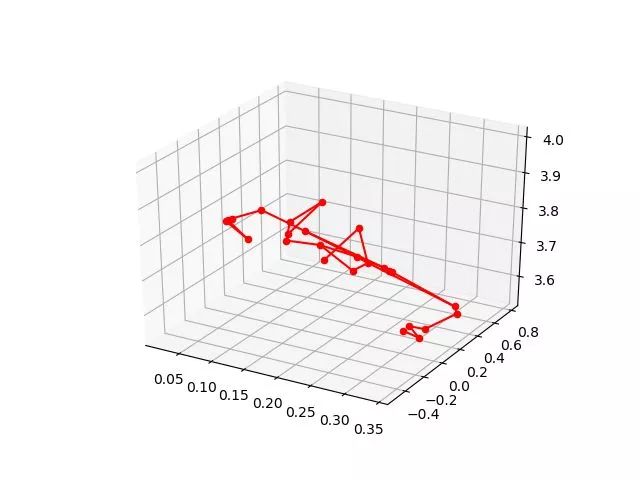
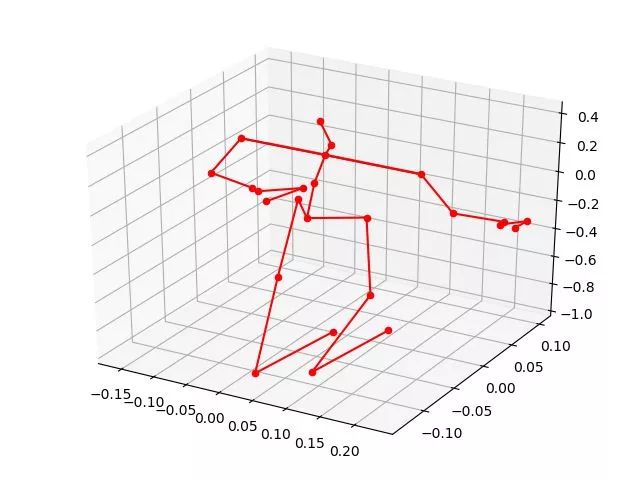
下图是一个例子,其中图 6是图 5经过去噪后的结果
接着我们在NTU-RGB+D数据库上我们进行了消融实验,结果如下:
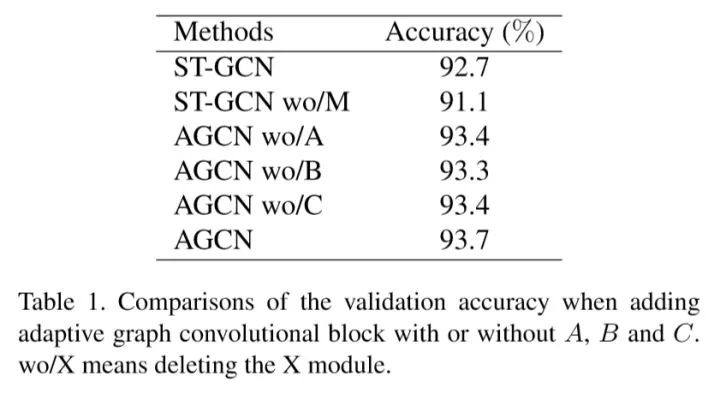
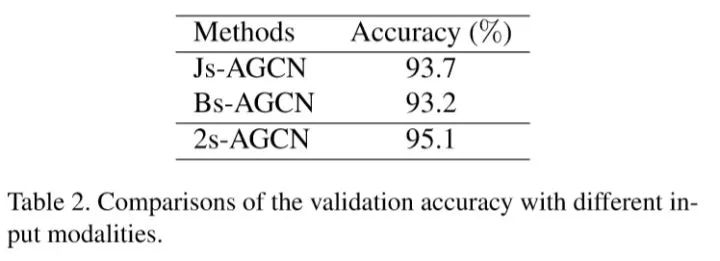
从中可以看出我们所提出的自适应图卷积层和双流法都有明显的效果。最终在NTU-RGB+D和Kinetics-Skeleton上我们都取得目前最好的结果,并且较之前的方法都有很大的提升(~7%)。
论文信息:
@inproceedings{2sagcn2019cvpr,
title = {Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition},
author = {Lei Shi and Yifan Zhang and Jian Cheng and Hanqing Lu},
booktitle = {CVPR},
year = {2019},
}
code:
https://github.com/lshiwjx/2s-AGCN
Reference
[1] S. Yan, Y. Xiong和D. Lin, 《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》, 收入 AAAI, 2018.
[2] A. Vaswani等, 《Attention is All you Need》, 收入 Advances in Neural Information Processing Systems 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan和R. Garnett, 编 Curran Associates, Inc., 2017, 页 6000–6010.
[3] X. Wang, R. Girshick, A. Gupta和K. He, 《Non-Local Neural Networks》, 收入 The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[4] K. Simonyan和A. Zisserman, 《Two-stream convolutional networks for action recognition in videos》, 收入 Advances in neural information processing systems, 2014, 页 568–576.
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~




