ICCV2019 | 旷视科技提出:ThunderNet(轻量实时)目标检测网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:牛奶可乐201809180155732
https://www.nowcoder.com/discuss/244979
本文已由作者授权,未经允许,不得二次转载
背景
《ThunderNet: Towards Real-time Generic Object Detection》是2019 ICCV的论文,也是旷视孙剑组的论文。该论文早几个月就挂在arXiv上了,个人感觉这篇还是奔着应用去的,工程性较强。

论文地址:https://arxiv.org/abs/1903.11752
一、研究动机
本篇论文最主要的目标是设计一个轻量实时的two-stage目标检测算法。从算法上说,two-stage毕竟比one-stage算法性能要好,检出也比较稳定。作者在原有的lighthead rcnn的基础上进行了再设计,对backbone、RPN、head都进行了修改,增加了CEM,SAM,从而在加速的同时又提升了性能。
二、研究方法
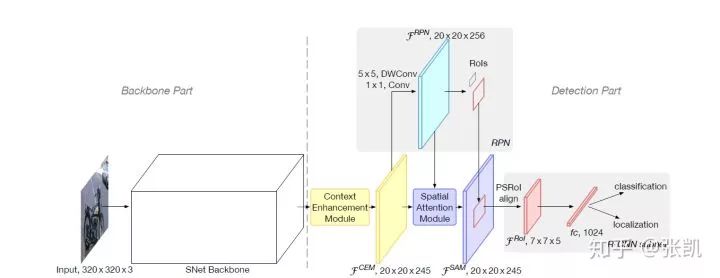
整体框架如图所示,下面分几个模块介绍下:
1)backbone
首先在该论文中采用输入320x320的分辨率,并且作者通过实验得出了一个结论:输入的分辨率要和主干网络相匹配。低分辨率和大主干网络或者高分辨率和小主干网络都不是最优的。
针对320x320的分辨率,作者设计了新的backbone。主要有两点:1)要有大的感受野。主要是获取足够多的局部信息,对目标位置至关重要。2)兼顾浅层特征和深层特征。浅层特征包含更多的位置信息。
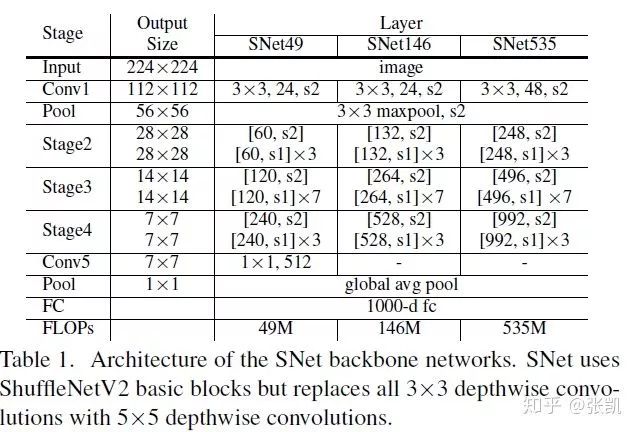
在此基础,作者认为ShuffleNetv2缺乏浅层特征,并进行了改进,提出了SNet,主要包括:SNet49,速度快;SNet535,准确率高;SNet146,兼顾速度和准确率。
改进主要包括:
(1)用5x5的depthwise卷积替代3x3,这是为了增加感受野;
(2)在SNet535和146中,直接去除了conv5,同时增加了浅层特征的通道数,获取丰富的位置信息;在SNet49中,则是对conv5进行了压缩。
总体情况如下图所示:
2)RPN部分
作者采用5x5的depthwise卷积和1x1的普通卷积替代3x3卷积,降低了计算量。(不知道在ARM上depthwise卷积优化得怎么样,是不是速度确实更快)
3)detection head
主要是对light head RCNN的修改,α=5替换原来的α=10,同时使用PSRoI align代替RoI warping。
4)CEM模块(Context Enhancement Module)
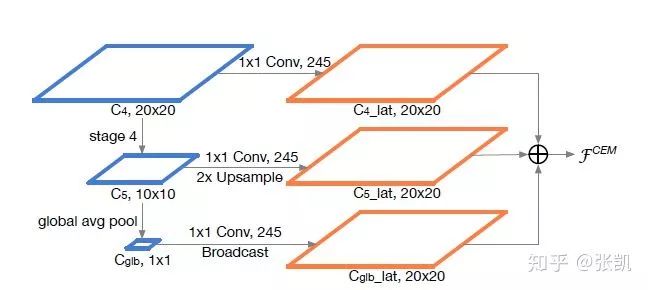
区别于FPN,该网络应该只有一个尺度的特征进行检测。借鉴FPN的思想,最后的特征会做一个融合,包括浅层特征和深层的特征。具体结构如图所示。
5)SAM模块(Spatial Attention Module)
借鉴注意力机制的思想,做一个通道上的attention:
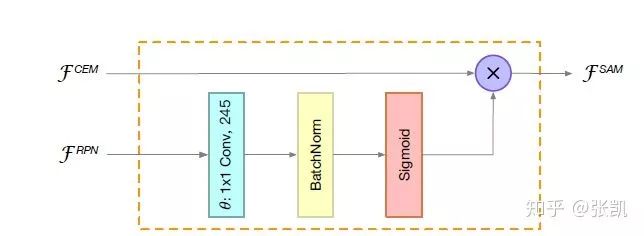
由RPN的特征产生一个权重,对CEM的特征进行加权,得到RCNN中待检测的特征。
三、实验结果
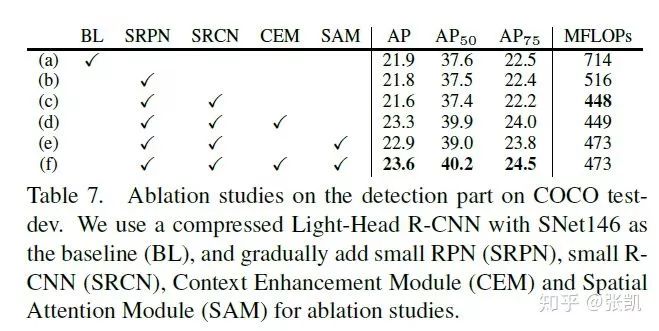
从消融实验中可以看到本文的研究思路,SRPN和SRCN降低了一半的计算量,但是性能只掉了0.3个点。CEM和SAM增加了少量的计算量,却提升了2个点。
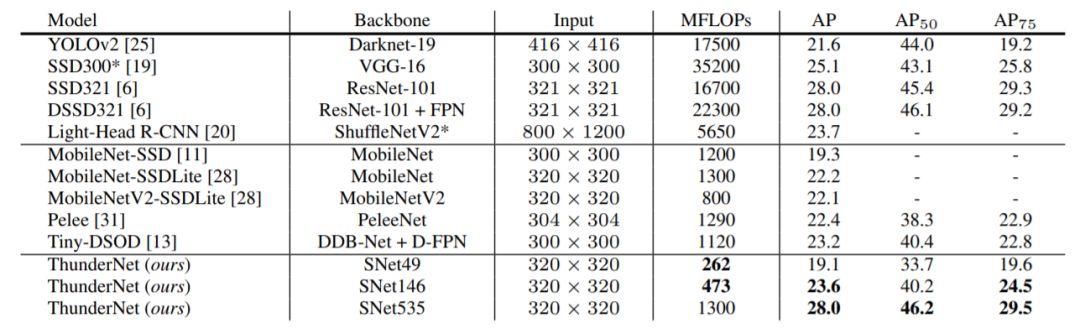
最后性能对比,最高是28.0,和MobileNet-SSD相似的计算量,却高了9个点。
四、总结分析
总体上,感觉还是有很大的工程价值,SNet、SRPN、SRCN、CEM和SAM大多数现有方法的简单改进,但是实现了ARM上的快速检测,同时得出了一些设计的原则和技巧,还是有比较大的借鉴意义的。
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测交流群,同时还可以加入目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



