【学界】CVPR2019 | 快、好、实现简单并且开源的显著性检测方法
来源 | 极市平台

论文:https://arxiv.org/abs/1904.08739
代码:https://github.com/wuzhe71/CPD
算法流程

上图(a)是目前比较流行的显著性检测方法的网络结构图,一般都是提取网络结构的浅层和深层feature,并对这些feature进行反卷积,并将反卷积得到的输出进行融合,得到最终的显著性图。
上图(b)是本文算法的流程。可以发现作者并没有使用前两个浅层的feature了,而是直接从第3个稍微深的feature开始使用。图中每个conv block之后,特征分辨率都会变小两倍。
1、提取第3、4、5个Conv block的feature,并通过一个解码器直接得到初步的显著性图![]()
2、将此显著性图输入到一个Holistic attention module中,得到进一步的显著性图。
3、将与第三个Conv block的特征进行元素相加,再次传入到两个Conv block中进行进一步特征提取
4、仿照第一步将特征传入decoder,得到了最终的显著性结果![]()

具体细节
1、为何不适用浅层feature了
作者通过实验发现浅层的feature对于最终的显著性检测结果影响不大,但是运算消耗却很大。
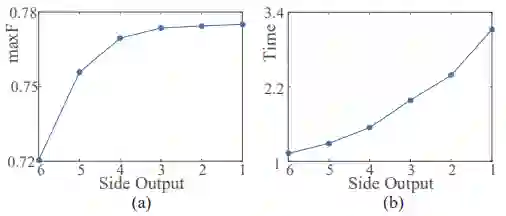
例如下图(1)和图(2)。
图1 a是作者绘制的不同层的feature对最终的结果影响。发现第2和1层对结果的提升几乎没有影响。图1b 是运算时间,发现浅层feature的运算时间比较的大。
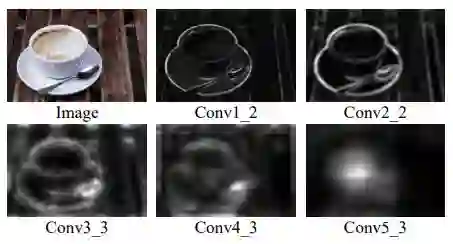
图2 是作者绘制的VGG16不同层输出的显著性结果。发现浅层显著性多集中于边缘信息,深层显著性才比较接近真正的显著性。
综上所述,作者没有使用前两层的feature,而直接从第三层feature开始使用。
2、loss计算
作者算法一共输出了两个显著性图 


3、Holistic Attention Module
这部分其实方法也非常的简单:

具体就是对于初步得到的显著性 
3、解码器(Decoder)
这部分实现也非常的简单,但是作者描述的有些复杂,建议看看代码,一下就懂了。主要操作就是使用不同大小的卷积和对每一层的特征进行进一步卷积,获得不同感受野。最后就是在不同层的feature之间进行有效的融合了。
实验
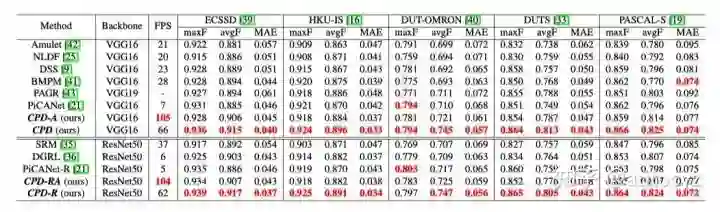
可以看到与DSS相比,无论是分数还是性能都有提升。所以说又快又好。
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得

