使用LSTM模型预测股价基于Keras

本期作者:Derrick Mwiti
本期翻译:HUDPinkPig
未经授权,严禁转载
编者按:本文介绍了如何使用LSTM模型进行时间序列预测。股票市场的数据由于格式规整和非常容易获得,是作为研究的很好选择。但不要把本文的结论当作理财或交易建议。
本文将通过构建用Python编写的深度学习模型来预测未来股价走势。
虽然预测股票的实际价格非常难,但我们可以建立模型来预测股票价格是上涨还是下跌。本文使用的数据可以在https://github.com/mwitiderrick/stockprice下载。另外,本文将不考虑诸如政治氛围和市场环境等因素对股价的影响。。
介绍
LSTM在解决序列预测的问题时非常强大,因为它们能够存储之前的信息。而之前的股价对于预测股价未来走势时很重要。
本文将通过导入NumPy库来进行科学计算、导入Matplotlib库来绘制图形、以及导入Pandas库来加载和操作数据集。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd加载数据集
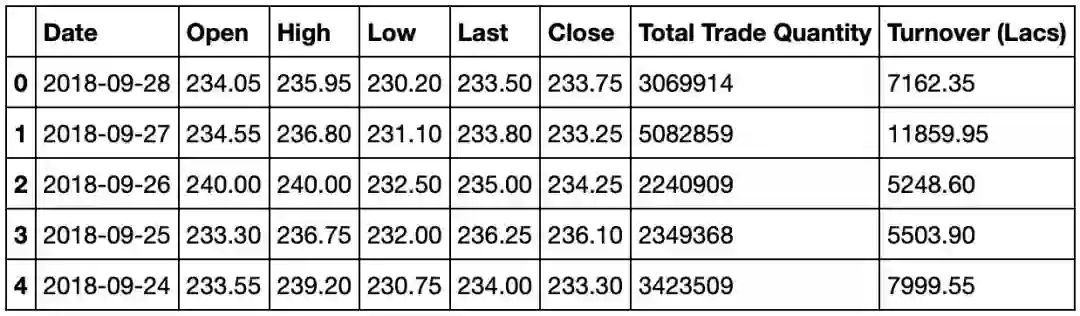
模型选择开盘价(Open)和最高价(High)两列。我们查看数据集的表头,可以大致了解数据集的类型。
dataset_train = pd.read_csv('NSE-TATAGLOBAL.csv')
training_set = dataset_train.iloc[:, 1:2].valuesOpen列是股票交易的开盘价,Close列是收盘价,High列是最高价,Low列是最低价。
特征归一化
从以前使用深度学习模型的经验来看,我们需要进行数据归一化以获得最佳的测试表现。本文的例子中,我们将使用Scikit- Learn的MinMaxScaler函数将数据集归一到0到1之间。
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0, 1))
training_set_scaled = sc.fit_transform(training_set)按步长创建数据
LSTM要求数据有特殊格式,通常是3D数组格式。初始按照60的步长创建数据,并通过Numpy转化到数组中。然后,把 X_train的数据转化到3D维度的数组中,时间步长设置为60,每一步表示一个特征。
X_train = []
y_train = []
for i in range(60, 2035):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))构建LSTM
我们需要导入Keras的一些模型来构建LSTM
1、顺序初始化神经网络
2、添加一个紧密连接的神经网络层
3、添加长短时记忆层(LSTM)
4、添加dropout层防止过拟合
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout为了防止过拟合,我们添加了LSTM层和Dropout层,其中LSTM层的参数如下:
1、50 units 表示输出空间是50维度的单位
2、return_sequences=True 表示是返回输出序列中的最后一个输出,还是返回完整序列
3、input_shape 训练集的大小
在定义Dropout层时,我们指定参数为0.2,意味着将删除20%的层。然后,我们指定1个单元的输出作为全连接层(Dense layer)。接着,我们使用目前流行的adam优化器编译模型,并用均方误差(mean_squarred_error)来计算误差。最后,模型运行100epoch,设置batch大小为32。这个参数是根据电脑的配置来设定的,并且将耗费几分钟时间来完成实验。
regressor = Sequential()
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
regressor.add(Dense(units = 1))
regressor.compile(optimizer = 'adam', loss = 'mean_squared_error')
regressor.fit(X_train, y_train, epochs = 100, batch_size = 32)
在测试集上预测股价
先导入我们要做股价预测的测试集:
dataset_test = pd.read_csv('tatatest.csv')
real_stock_price = dataset_test.iloc[:, 1:2].values为了预测未来的股票价格,我们需要在测试集加载后做如下几个工作:
1、在0轴上合并训练集和测试集
2、将时间步长设置为60(如前面所介绍的)
3、使用MinMaxScaler函数转换新数据集
4、按照前面所做的那样重新规整数据集
在做出预测之后,我们用inverse_transform函数处理,以返回正常可读格式的股票价格。
dataset_total = pd.concat((dataset_train['Open'], dataset_test['Open']), axis = 0)
inputs = dataset_total[len(dataset_total) - len(dataset_test) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = sc.transform(inputs)
X_test = []
for i in range(60, 76):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
predicted_stock_price = regressor.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)展示结果
最后,我们用Matplotlib库可视化显示真实股价和预测股价的对比。
plt.plot(real_stock_price, color = 'black', label = 'TATA Stock Price')
plt.plot(predicted_stock_price, color = 'green', label = 'Predicted TATA Stock Price')
plt.title('TATA Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('TATA Stock Price')
plt.legend()
plt.show()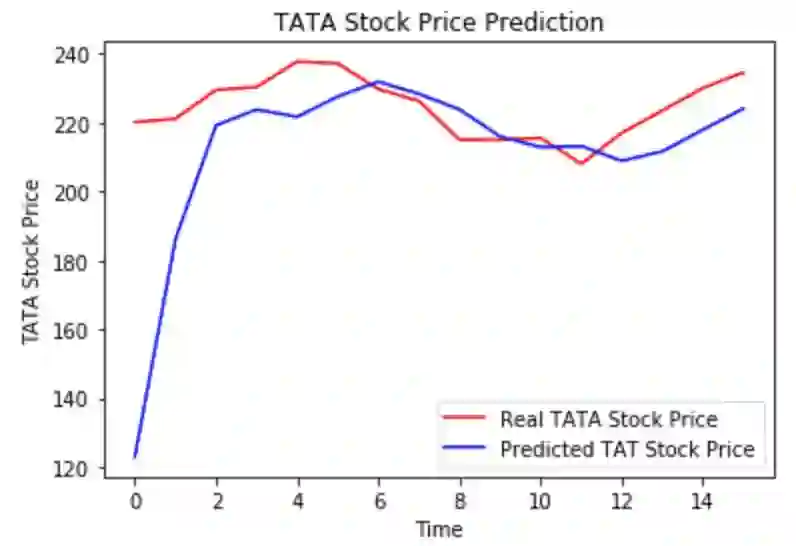
从图中我们可以看到,股票实际价格出现上涨时,模型也预测股价会上涨,较为吻合。这清晰地显示了LSTMs在分析时间序列和序列数据等方面的强大作用。
结论
预测股价的方法还有很多,比如移动平均线、线性回归、k近邻、ARIMA和Prophet。读者可以自行测试这些方法的准确率,并与Keras LSTM的测试结果进行比较。
推荐阅读
09、Facebook开源神器Prophet预测时间序列基于Python
10、Facebook开源神器Prophet预测股市行情基于Python
11、2018第三季度最受欢迎的券商金工研报前50(附下载)
13、Markowitz有效边界和投资组合优化基于Python(附代码)
公众号官方QQ群
每天很多干货分享
没有按规则加群者一律忽略