如何衡量目标检测模型的优劣

极市导读
机器学习算法的落地从数据>>建模>>训练>>评估>>部署,生命周期中的这5个环节一样都不能少,其中算法的评估尤为重要,不同的任务有其自身的衡量标准.
本文我们走进目标检测任务的各项评价指标,回顾各项衡量标准的优劣及使用环境。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
细数目标检测中的评价指标
计算机视觉中的目标检测即包含了分类和回归两大任务,对于预测的结果我们不能凭直觉判断模型的好坏,而是需要一个量化指标。业界对模型的性能评估已经有很多不同的指标:比如准确率、精确率、召回率、平方误差、余弦距离、P-R曲线、ROC曲线、AP、mAP、AUC、IOU等等。本文我们从最简单的准确率说起。
最简单的评价指标—准确率
准确率是分类问题中最简单的评价指标,表示正确的样本占总样本的比例。这里我们会有一个疑问:是不是模型的准确率越高性能就越好呢?
当然不是。准确率一般是从全局角度评估模型的优劣。但是它存在一定的局限性,比如训练阶段有1000个样本,其中999个负样本,1个正样本。那么如果我们将所有样本都预测成负样本,准确率可以达到99.9%,从数据上看感觉性能很好,但是部署上线后可能大部分正样本都预测错误,造成用户体验的下降。
原因是由于样本类别的不平衡导致训练过程虽然准确率很高,但是实际效果却不好,得到误导性的结果。如果准确率不能很有效的评估模型性能,那么我们可以采用什么指标来评估呢?
精确率和召回率一对矛盾共生体
在日常生活中我们经常遇到这样的情况:比如你去超市买橘子,我们关心的是挑选的橘子中有多少个是甜的;或者所有甜的橘子中有多少个被你选中了。前者叫做精确率,后者叫做召回率。
精确率又叫查准率,是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
召回率又叫查全率,是指分类正确的正样本个数占真正的正样本个数的比例。
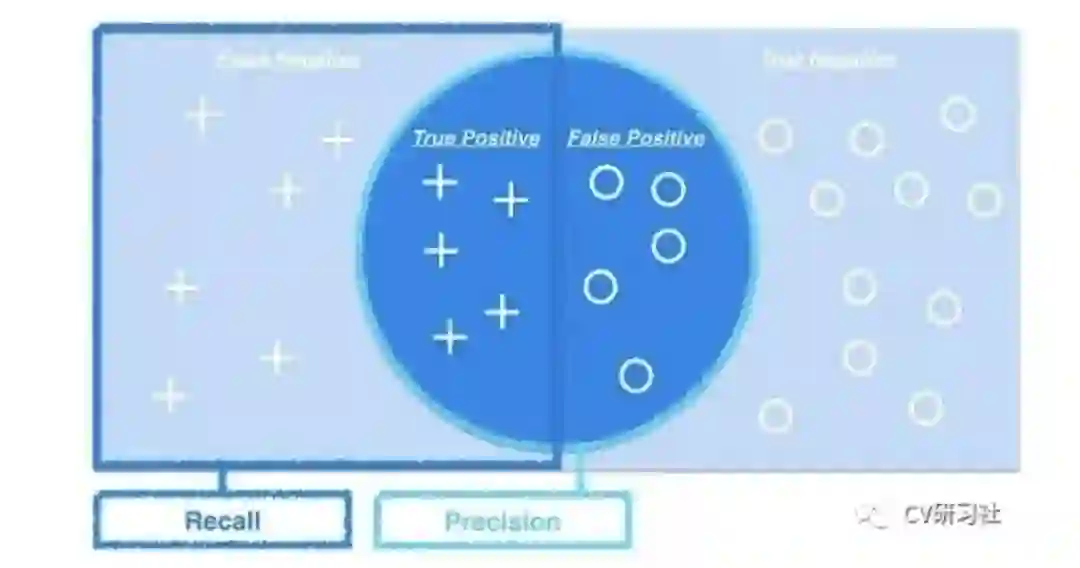
这两个定义有点拗口,具体可以借助下面的混淆矩阵直观理解(本文图片来源于网络,如有侵权联系删除)
精准度和召回率是最常见的指标之一,模型的性能需要在两者之间权衡。往往为了提供精确率,需要尽量在更有把握时才将待测样本判定为正样本,但如此保守的策略也会漏掉很多真值。
和谁都有关系的混淆矩阵
为了可视化算法的性能如何,这里引出一个混淆矩阵的概念,它能够快速直观的帮助算法人员分析每个类别的误分类情况。
我们经常会看到这么几个简写:TP,TN,FP,FN:
-
TP代表真阳性,即正样本被预测成正样本 -
TN代表真阴性,即负样本被预测成负样本 -
FP代表假阳性,即负样本被预测成正样本 -
FN代表假阴性,即正样本被预测成负样本
这四个简称小编以前经常会记混,第一个字母表示预测的对错True/False,第二个字母表示预测的结果Positive/Negative。
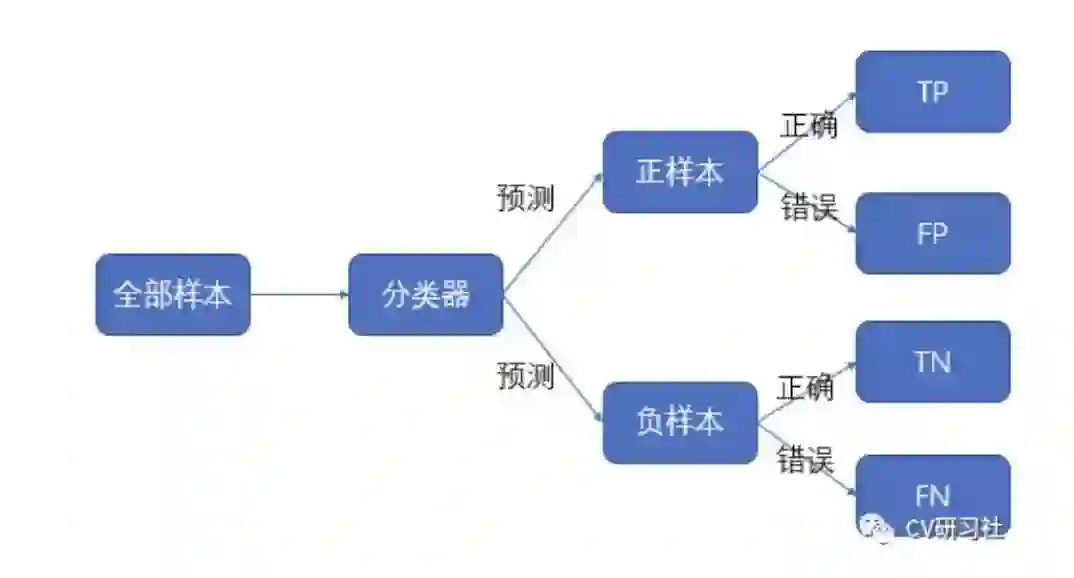
通过这四个统计量可以帮我们构建出下图的矩阵,这里我们是以二分类为例,构建2×2的矩阵;如果是K个类别,可以推广到K×K的矩阵:
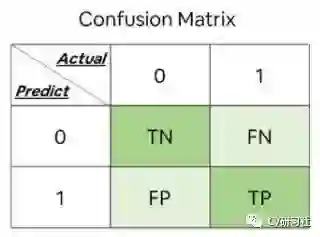
其中每一列代表预测值,每一行代表实际值。每一行的个数之和代表该类别的实际个数,所有正确预测的结果都在矩阵的对角线上,它可以解决上面提到的正确率指标的局限性,直观的看出每个类别正确识别的数量和错误识别的数量。
混淆矩阵也可以延伸出各个评价指标的表达方式:
-
准确率 = TP / (TP + TN + FP + FN) -
精确率 = TP / (TP + FP) -
召回率 = TP / (TP + FN) -
F1 = 2 × 精确率 × 召回率 / (精确率 + 召回率)
备注:F1得分是精确率和召回率的调和平均值。
上面我们讨论的精确率/召回率都是在固定阈值下得到的一个数值,为了综合评估一个模型的优劣,是否需要在不同的Top N下的观察P-R两方面的结果呢?
P-R 曲线和AP值的用途
P-R 曲线是由精确率和召回率构成的一张曲线图,以召回率作为横坐标轴,精确率作为纵坐标轴。在某个阈值下,模型将大于该阈值的结果判定成正样本,将小于该阈值的结果判定成负样本,再结合真值得到精确率和召回率,即表示P-R曲线上的一个点。如果想要生成一幅 P-R 曲线图,通常需要执行以下几步:
-
用训练好的模型评估所有测试样本的得分; -
每一类分别分开统计,并对分类概率值排序; -
从Top-1开始,将第1个置信度作为阈值,当前预测的为正样本,其余得分小于该阈值的作为负样本,统计TP,FP,FN; -
根据统计值计算当前阈值下的精确度和召回率; -
从Top-1至Top-N重复步骤3和4; -
将不同阈值下的P-R值绘制成P-R曲线图;
通常P-R曲线可以显示出分类器在查准率与查全率之间的权衡。在各大刷榜论文中给出的AP值就是指P-R曲线下面的面积。下图是包含A,B,C三个分类器的P-R曲线图:
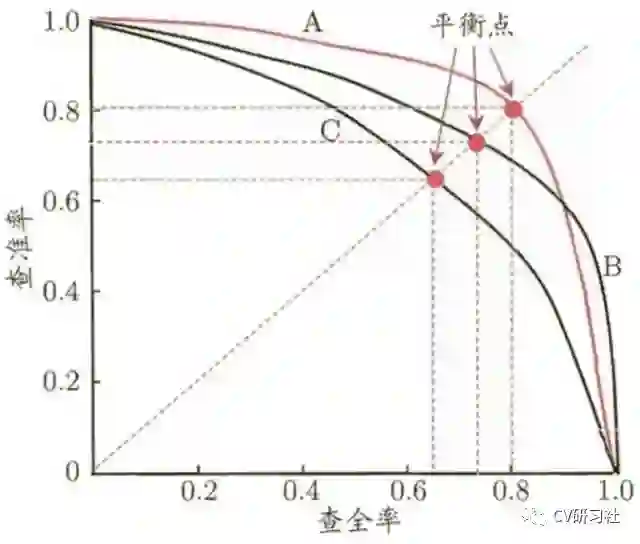
根据P-R曲线图如何评估不同分类器的性能呢?
分类器C的P-R曲线被分类器A或B的P-R曲线完全包住,则说明分类器A和B的性能优于C;
当A和B两个分类器的P-R曲线交叉时又该怎么评估性能优劣呢?
一般可以统计A和B曲线下的面积来衡量,该面积又叫做平均精度AP,值越大性能越好。为了更加准确的计算,还可以采用平衡点或者F1 score的方式度量。
如果用户场景对模型的性能更偏向于全面性或者精确性怎么办?
我们知道F1 score是调和平均数,认为精确率和召回率重要程度一样的一个统计平均值。当用户的业务场景本身就需要偏向某一方时,该值就不在适用了。针对用户的不同偏好,可以在F1的基础上增加权重a,即(1 + a×a) P×R / ((a × a × P) + R),权重a>1时,召回率占比更大,权重a < 1时,精准率占比更大。
在P-R曲线中,不管是精确率还是召回率关注点都在于正样本的占比,如果在测试集中的正负样本占比发生变化后,P-R曲线的统计值就会发生很大的变化,但是在实际应用中,在类别不平衡的数据中用户关心的也还是正样本,所以P-R曲线仍然被广泛应用。
如果有小伙伴非要兼顾正样本和负样本,评估分类器的整体水平怎么办呢?这里我们有另一种曲线——ROC曲线!
ROC 曲线和 AUC 值的用途
ROC曲线反映了真阳性率和假阳性率之间的变化关系。横轴就是FPR,纵轴就是TPR,然后选择不同的阈值时,就可以对应坐标系中一个点。
真阳性率即TPR = TP / (TP + FN),表示在所有正样本中被预测为正样本的比例,俗称命中率。
假阳性率即FPR = FP / (FP + TN),表示在所有负样本中被预测成正样本的比例,俗称虚警率。
如下图所示:我们主要看正方形的四个顶点(0,0),(0,1),(1,0),(1,1)的含义:
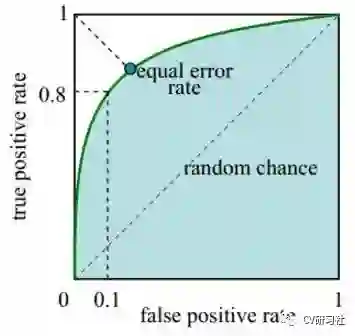
我们根据ROC计算的两个数学公式来进一步分析:
-
(0,0)点表示TPR=0且TFR=0,也就是说TP和FP都是0,换句话说就是给我任何一个样本,都会被预测成正样本。
-
(1,1)点表示TPR=1且TFR=1,也就是说TP和FP都是1,和(0,0)点的含义刚好相反,给我任何一个样本,都会被预测成负样本。
-
(0,1)点表示FPR=0且TPR=1,也就是说FP和FN都是0,既没有把任何一个负样本预测成正样本,也没有把任何一个正样本预测成负样本,这不是完美嘛!所以曲线越趋近于左上角,预测结果越准确。
-
(1,0)点表示FPR=1且TPR=0,也就是说TP和TN都是0,这简直是史上运气最差的分类器,没有一个正样本预测正确,也没有一个负样本预测正确。
这里计算的ROC仍然是根据固定阈值进行混淆矩阵的统计最后得到的一个点,曲线的绘制和P-R曲线流程相似,都是根据测试数据的类别置信度进行从高到低的排序,依次将置信度得分作为阈值统计不同区域时的FPR和TPR。
被绕进去的小伙伴可以在回到上面重温混淆矩阵,构建一个高性能的分类器我们希望假阳性率越小越好,真阳性率越大越好。相比于P-R曲线,TPR更加关注正样本,FPR更加关注负样本,所以是一种对正负样本更加均衡的评估方式。
ROC曲线在数据分布发生变化时表现的平稳性,也注定是它的缺陷所在,在模型评估的时候,当正负样本比例是1:1、1:10、1:100等等,ROC曲线形式都是惊人的相似,而P-R曲线更加明显的表现出模型之间的优劣。
AP表示P-R曲线下的面积,那么ROC曲线下的面积又有什么物理意义呢?
ROC曲线下面积越大,该模型越有可能将正样本排在负样本前面,表明分类器的性能越好,这个概率值就叫做AUC。
- END -
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



