BN究竟起了什么作用?一个闭门造车的分析

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
BN,也就是 Batch Normalization [1],是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的 batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到 N (0, 1) 上,减少了所谓的 Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布 N (0, 1) ;其次,就算能做到 N (0, 1) ,这种诠释也无法进一步解释其他归一化手段(如 Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文 How Does Batch Normalization Help Optimization? [2] 里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于 BN 的新理解:他们认为 BN 主要作用是使得整个损失函数的 landscape 更为平滑,从而使得我们可以更平稳地进行训练。
本文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
阅读本文之前,请确保你已经清楚知道 BN 是什么,本文不再重复介绍 BN 的概念和流程。
一些基础结论
在这部分内容中我们先给出一个核心的不等式,继而推导梯度下降,并得到一些关于模型训练的基本结论,为后面 BN 的分析铺垫。
核心不等式
假设函数 f(θ) 的梯度满足 Lipschitz 约束( L 约束),即存在常数 L 使得下述恒成立:

那么我们有如下不等式:
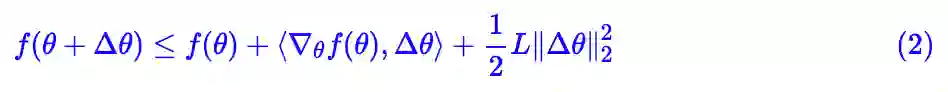
证明并不难,定义辅助函数 f(θ+tΔθ), t∈[0,1],然后直接得到:
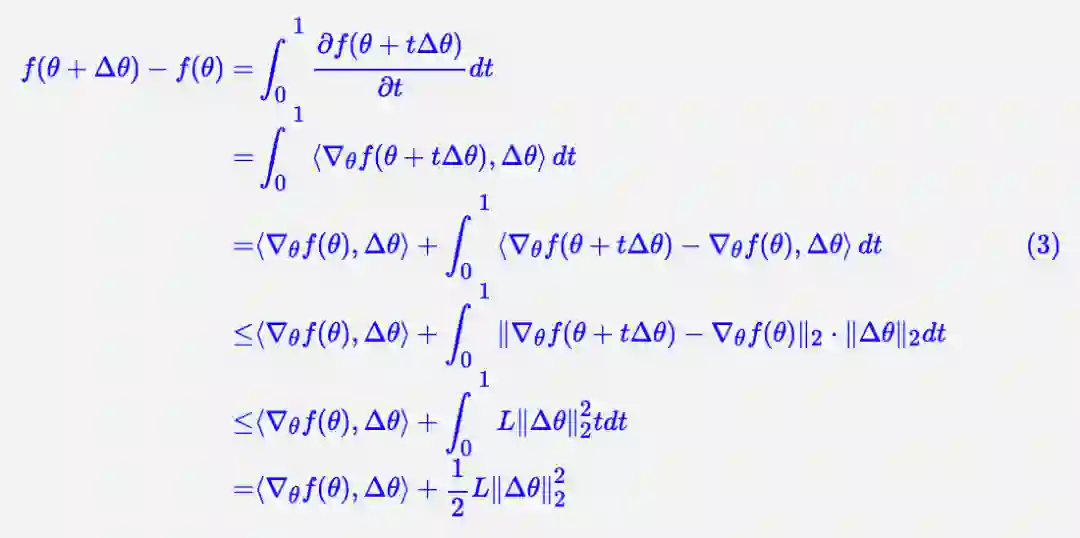
梯度下降
假设 f(θ) 是损失函数,而我们的目标是最小化 f(θ),那么这个不等式告诉我们很多信息。首先,既然是最小化,自然是希望每一步都在下降,即 f(θ+Δθ)<f(θ),而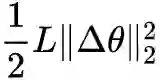
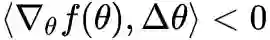

这里 η>0 是一个标量,即学习率。
可以发现,式 (4) 就是梯度下降的更新公式,所以这也就是关于梯度下降的一种推导了,而且这个推导过程所包含的信息量更为丰富,因为它是一个严格的不等式,所以它还可以告诉我们关于训练的一些结论。
Lipschitz约束
将梯度下降公式代入到不等式 (2) ,我们得到:
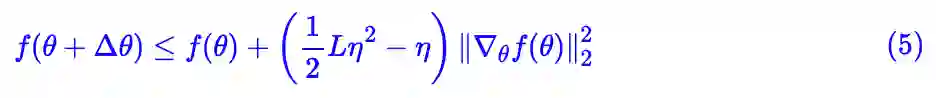
注意到,保证损失函数下降的一个充分条件是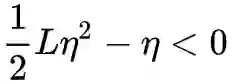
但 L 是 f(θ) 的内在属性,因此只能通过调整 f 本身来降低 L。
BN是怎样炼成的
本节将会表明:以降低神经网络的梯度的 L 常数为目的,可以很自然地导出 BN。也就是说,BN 降低了神经网络的梯度的 L 常数,从而使得神经网络的学习更加容易,比如可以使用更大的学习率。而降低梯度的 L 常数,直观来看就是让损失函数没那么“跌宕起伏”,也就是使得 landscape 更光滑的意思了。
注:我们之前就讨论过 L 约束,之前我们讨论的是神经网络关于“输入”满足 L 约束,这导致了权重的谱正则和谱归一化(请参考深度学习中的Lipschitz约束:泛化与生成模型),本文则是要讨论神经网络(的梯度)关于“参数”满足 L 约束,这导致了对输入的各种归一化手段,而 BN 是其中最自然的一种。
梯度分析
以监督学习为例,假设神经网络表示为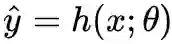
,那么我们要做的事情是:
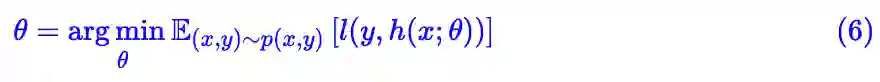
也就是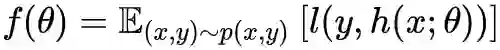
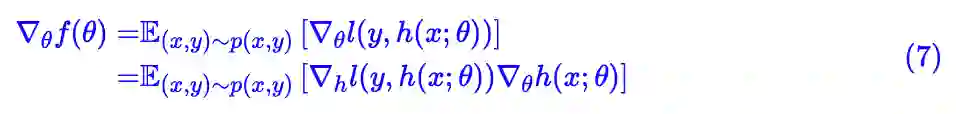
顺便说明一下,本文的每个记号均没有加粗,但是根据实际情况不同它既有可能表示标量,也有可能表示向量。
非线性假设
显然, f(θ) 是一个非线性函数,它的非线性来源有两个:
1. 损失函数一般是非线性的;
2. 神经网络 h(x;θ) 中的激活函数是非线性的。
关于激活函数,当前主流的激活函数基本上都满足一个特性:导数的绝对值不超过某个常数。我们现在来考虑这个特性能否推广到损失函数中去,即(在整个训练过程中)损失函数的梯度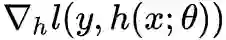
看上去,这个假设通常都是不成立的,比如交叉熵是 −log p,而它的导数是 −1/p,显然不可能被约束在某个有限范围。但是,损失函数联通最后一层的激活函数一起考虑时,则通常是满足这个约束的。比如二分类是最后一层通常用 sigmoid 激活,这时候配合交叉熵就是:
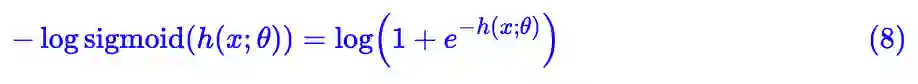
这时候它关于 h 的梯度在 -1 到 1 之间。当然,确实存在一些情况是不成立的,比如回归问题通常用 mse 做损失函数,并且最后一层通常不加激活函数,这时候它的梯度是一个线性函数,不会局限在一个有限范围内。
这种情况下,我们只能寄望于模型有良好的初始化以及良好的优化器,使得在整个训练过程中
柯西不等式
我们的目的是探讨满足 L 约束的程度,并且探讨降低这个 L 的方法。为此,我们先考虑最简单的单层神经网络(输入向量,输出标量) h(x;w,b)=g(⟨x,w⟩+b) ,这里的 g 是激活函数。这时候:
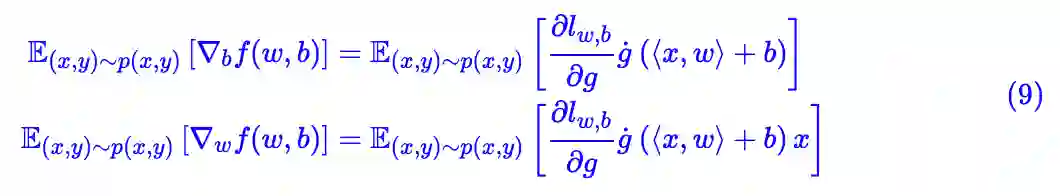
基于我们的假设,和
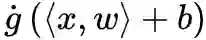
关于 w 的梯度差,我们有:
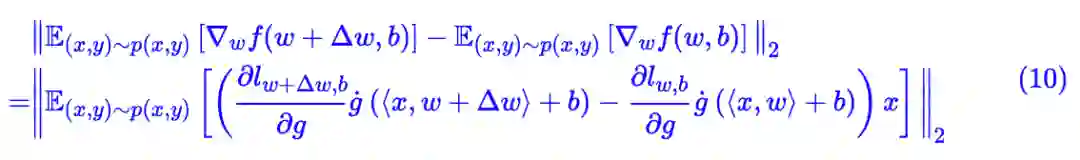
将圆括号部分记为 λ(x,y;w,b,Δw),根据前面的讨论,它被约束在某个范围之内,这部分依然是平稳项,既然如此,我们不妨假设它天然满足 L 约束,即:
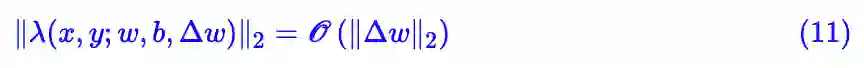
这时候我们只需要关心好额外的 x。根据柯西不等式,我们有:
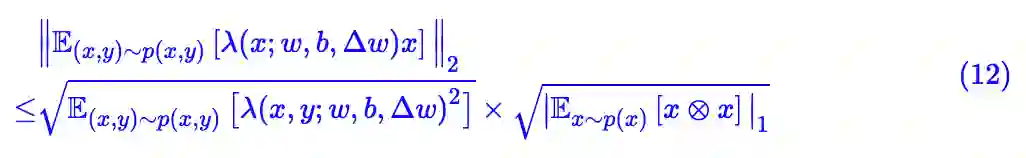
这样一来,我们得到了与(当前层)参数无关的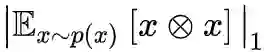
减均值除标准差
要注意,虽然我们很希望降低梯度的 L 常数,但这是有前提的——必须在不会明显降低原来神经网络拟合能力的前提下,否则只需要简单乘个 0 就可以让 L 降低到 0 了,但这并没有意义。
式 (12) 的结果告诉我们,想办法降低

最小化。这只不过是一个二次函数的最小值问题,不难解得最优的 μ 是:

于是,我们得到:
结论 1:将输入减去所有样本的均值,能降低梯度的 L 常数,是一个有利于优化又不降低神经网络拟合能力的操作。
接着,我们考虑缩放变换,即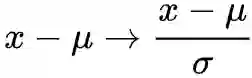
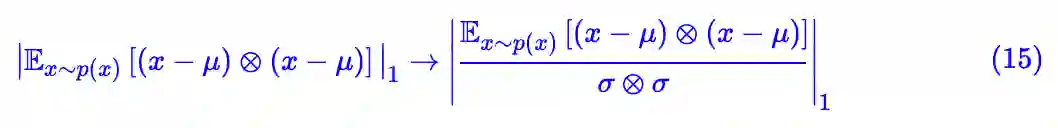
σ 是对 L 的一个最直接的缩放因子,但问题是缩放到哪里比较好?如果一味追求更小的 L,那直接 σ→∞ 就好了,但这样的神经网络已经完全没有拟合能力了;但如果 σ 太小导致 L 过大,那又不利于优化。所以我们需要一个标准。
以什么为标准好呢?再次回去看梯度的表达式 (9),前面已经说了,偏置项的梯度不会被 x 明显地影响,所以它似乎会是一个靠谱的标准。如果是这样的话,那相当于将输入 x 的这一项权重直接缩放为 1,那也就是说,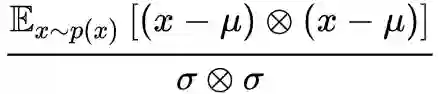
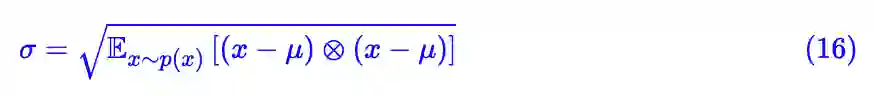
这样一来,一个相对自然的原则是将 σ 取为输入的标准差。这时候,我们能感觉到除以标准差这一项,更像是一个自适应的学习率校正项,它一定程度上消除了不同层级的输入对参数优化的差异性,使得整个网络的优化更为“同步”,或者说使得神经网络的每一层更为“平权”,从而更充分地利用好了整个神经网络,减少了在某一层过拟合的可能性。当然,如果输入的量级过大时,除以标准差这一项也有助于降低梯度的 L 常数。
于是有结论:
结论 2:将输入(减去所有样本的均值后)除以所有样本的标准差,有类似自适应学习率的作用,使得每一层的更新更为同步,减少了在某一层过拟合的可能性,是一个提升神经网络性能的操作。
推导穷,BN现
前面的推导,虽然表明上仅以单层神经网络(输入向量,输出标量)为例子,但是结论已经有足够的代表性了,因为多层神经网络本质上也就是单层神经网络的复合而已(关于这个论点,可以参考笔者旧作《从 Boosting 学习到神经网络:看山是山?》[3] )。
所以有了前面的两个结论,那么 BN 基本就可以落实了:训练的时候,每一层的输出都减去均值除以标准差即可,不过由于每个 batch 的只是整体的近似,而期望 (14) , (16) 是全体样本的均值和标准差,所以 BN 避免不了的是 batch size 大点效果才好,这对算力提出了要求。
此外,我们还要维护一组变量,把训练过程中的均值方差存起来,供预测时使用,这就是 BN 中通过滑动平均来统计的均值方差变量了。至于 BN 的标准设计中,减均值除标准差后还补充上的 β , γ 项,我认为仅是锦上添花作用,不是最必要的,所以也没法多做解释了。
简单的总结
本文从优化角度分析了 BN 其作用的原理,所持的观点跟 How Does Batch Normalization Help Optimization? 基本一致,但是所用的数学论证和描述方式个人认为会更简单易懂写。最终的结论是减去均值那一项,有助于降低神经网络梯度的 L 常数,而除以标准差的那一项,更多的是起到类似自适应学习率的作用,使得每个参数的更新更加同步,而不至于对某一层、某个参数过拟合。
当然,上述诠释只是一些粗糙的引导,完整地解释 BN 是一件很难的事情,BN 的作用更像是多种因素的复合结果,比如对于我们主流的激活函数来说, [−1,1] 基本上都是非线性较强的区间,所以将输入弄成均值为 0、方差为 1,也能更充分地发挥激活函数的非线性能力,不至于过于浪费神经网络的拟合能力。
总之,神经网络的理论分析都是很艰难的事情,远不是笔者能胜任的,也就只能在这里写写博客,讲讲可有可无的故事来贻笑大方罢了。
相关链接

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客


