万文长字总结「类别增量学习」的前世今生、开源工具包
随着统计机器学习的逐渐成熟, 现在已经是时候打破孤立学习地传统模式,转而研究终身学习, 将机器学习推向崭新的高度。
一、什么是终身学习(Life-Long Machine Learning)?
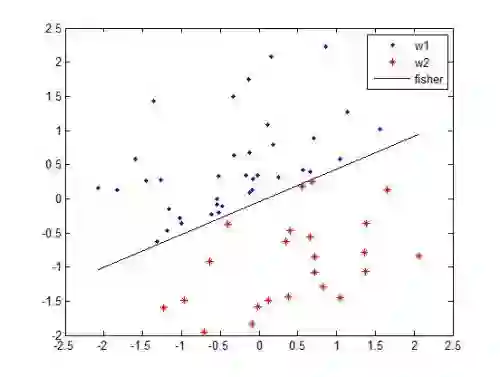
二、什么是灾难性的遗忘[2]?
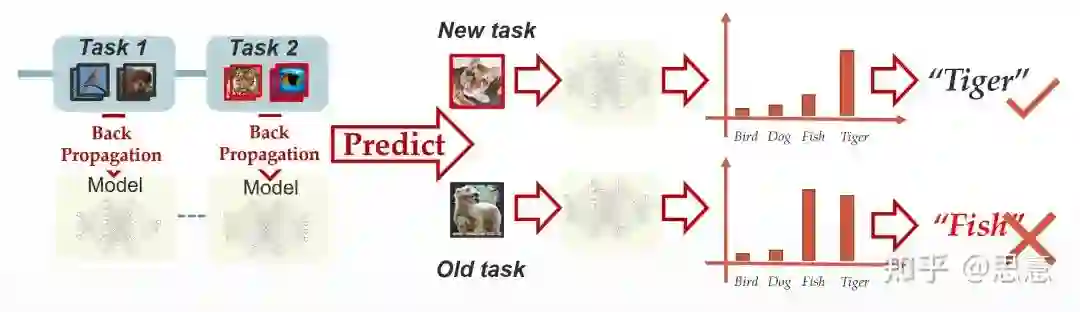
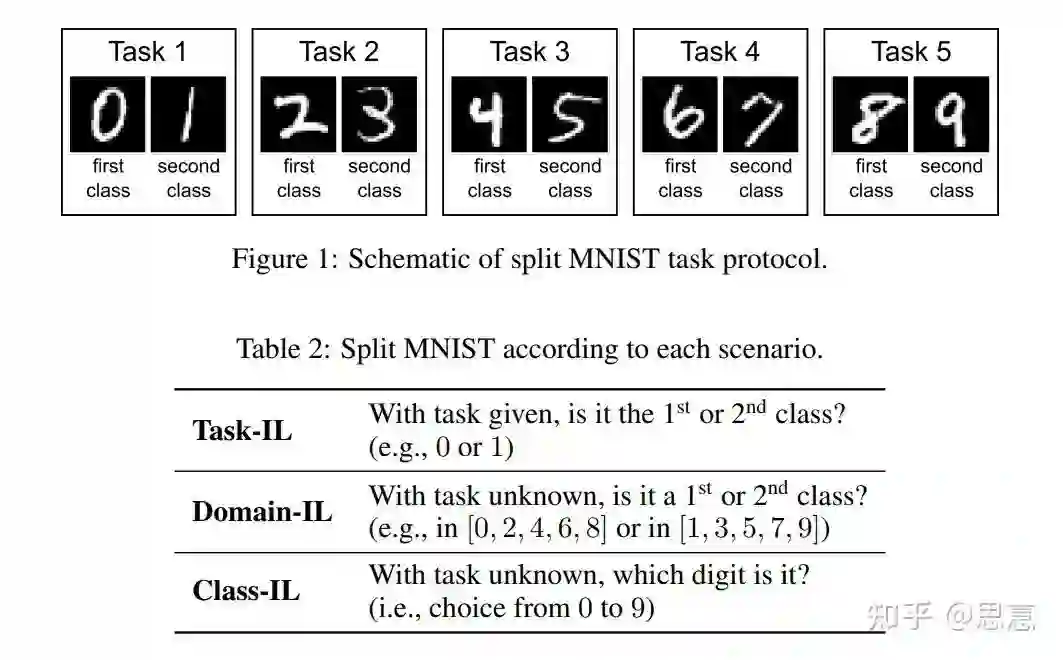
三、Continual Learning 有哪些场景?
场景一:Task-IL
场景二:Domain-IL
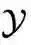 相同,但输入分布
相同,但输入分布
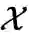 不同的问题。例如动漫中的老虎和现实中的老虎(虎年彩蛋)。
不同的问题。例如动漫中的老虎和现实中的老虎(虎年彩蛋)。


场景三:Class-IL
举例[4]
此外,目前还有更为严格地data-IL, 我们在训练时就并不显示的告知task的阶段,希望模型能够适应这种类别不稳定不均衡的数据流。此处我们不展开讨论。
四、什么是类增量学习?
一个简单的例子
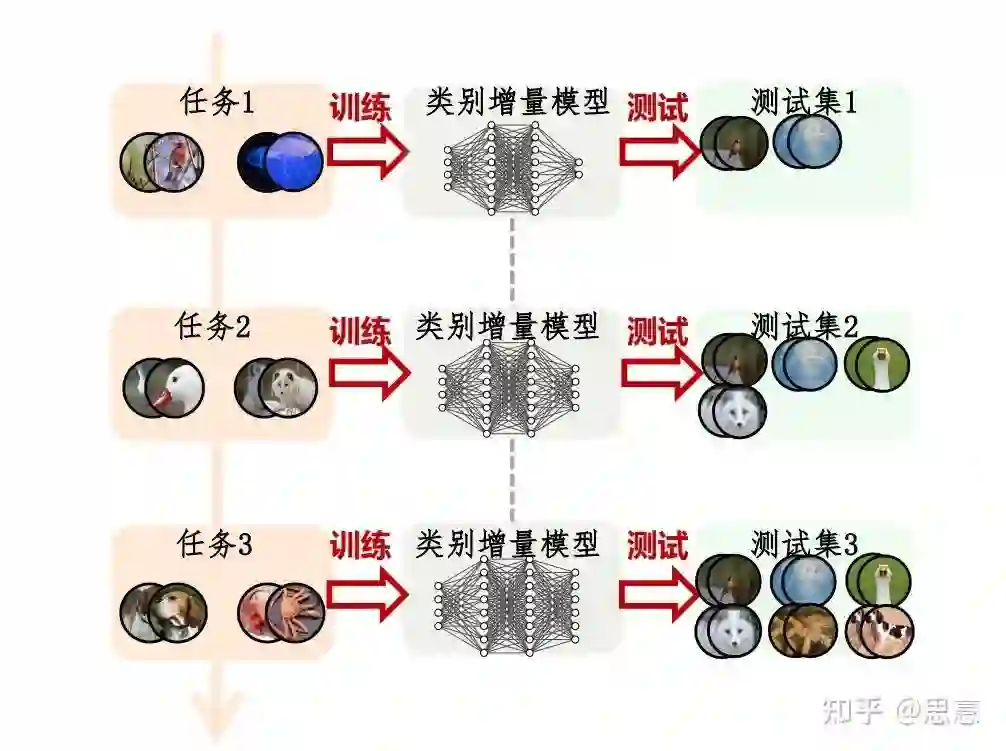
形式化定义
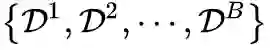 , 其中
, 其中
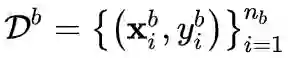 表示第 b
个增量学习训练数 据集, 又称作训练任务 (task)。
表示第 b
个增量学习训练数 据集, 又称作训练任务 (task)。
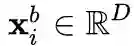 是来自于类别
是来自于类别
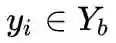 的一个训练样本, 其中
的一个训练样本, 其中
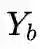 是第
是第
 b 个任务的标记空间。不同任务间不存在类别重合, 即对于
b 个任务的标记空间。不同任务间不存在类别重合, 即对于
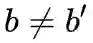 有:
有:
 。在学习第 b
个任务的过程中,只能使用当前阶段的训练数据集
。在学习第 b
个任务的过程中,只能使用当前阶段的训练数据集
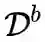 更新模型. 在每个训练阶段, 模型的目标不仅是学得当前 数据集
更新模型. 在每个训练阶段, 模型的目标不仅是学得当前 数据集
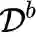 中新类的知识,同时也要保持不遗忘之前所有学过类别的知识. 因此, 我们基于模型在所 有已知类集合
中新类的知识,同时也要保持不遗忘之前所有学过类别的知识. 因此, 我们基于模型在所 有已知类集合
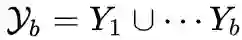 上的判别能力评估其增量学习能力. 将增量学习模型对样本
上的判别能力评估其增量学习能力. 将增量学习模型对样本
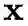 的输出 记作
的输出 记作
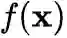 , 则模型要优化的期望风险描述为:
, 则模型要优化的期望风险描述为:
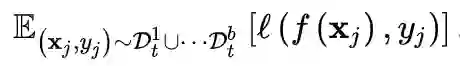
 表示第 b
个任务的样本分布。
表示第 b
个任务的样本分布。
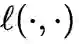 评估输入之间的差异, 在分类任务中一般使用交叉熵损 失函数。由于模型需要同时在见过的所有分布上最小化期望风险,能够满足公式 1 的模型能够在学习 新类的同时不遗忘旧类的知识。进一步地, 可以将深度神经网络按照特征提取和线性分类器层进行解耦, 则模型
评估输入之间的差异, 在分类任务中一般使用交叉熵损 失函数。由于模型需要同时在见过的所有分布上最小化期望风险,能够满足公式 1 的模型能够在学习 新类的同时不遗忘旧类的知识。进一步地, 可以将深度神经网络按照特征提取和线性分类器层进行解耦, 则模型
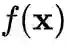 由特征提取模块
由特征提取模块
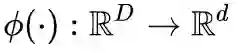 和线性分类器
和线性分类器
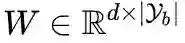 组成,即
组成,即
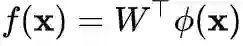 。
为了表述方便, 我们将线性分类器
。
为了表述方便, 我们将线性分类器
 进一步表示成对于每个类分类器
进一步表示成对于每个类分类器
 的组合:
的组合:
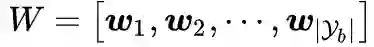 。
。
五、论文方法解读
模型解耦
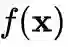 由特征提取模块
由特征提取模块
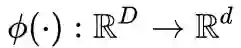 和线性分类器
和线性分类器
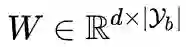 组成, 即
组成, 即
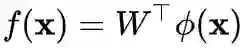 。为了表述方便, 我们将线性分类器
。为了表述方便, 我们将线性分类器
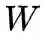 进一步表示成对于每个类分类器
进一步表示成对于每个类分类器
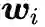 的组合:
的组合:
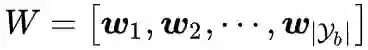 。
。
5.1 LwF: Learning without Forgetting[5]
核心摘要
除了LwF本身外,还提出了Fine-tunine, Feature Extraction, Joint Training三种基本的对比方法,并对不同方法进行了分析与实验对比。
提出了使用知识蒸馏(Knowledge Distillation)的方法提供旧类的“软监督”信息来缓解灾难性遗忘的问题。并且发现,这种监督信息即使没有旧类的数据仍然能够很大程度上提高旧类的准确率。
对参数偏移的正则惩罚系数、正则形式、模型拓展方式等等因素进行了基本的实验对比。(不过具论文中结果这些因素的影响并不明显)。
方法比较
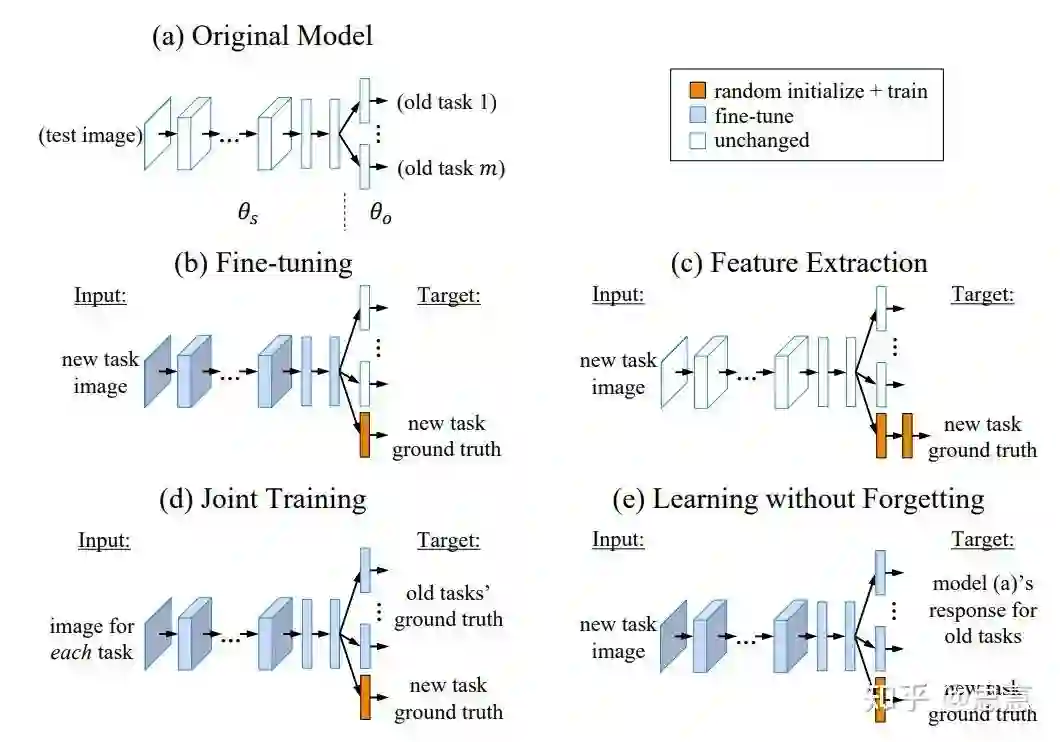
-
(a) 中为传统的多分类模型,它接受一张图片,然后通过线性变换、非线性激活函数、卷积、池化等运算操作符输出该图片在各个类别上的概率。 -
(b) 中为Fine-tuning方法,即训练新类时,我们保持旧的分类器不变,直接训练前面的特征提取器和新的分类器权重。 -
(c) 称为Feature Extraction,保持特征提取器不变,保持旧的分类器权重不变,只训练新的任务对应的参数。 -
(d) 中为Joint Training的方法,它在每个训练任务时刻都同时接受所有的训练数据进行训练。 -
(e) 中为LwF方法,他在Fine-tuning的基础上,为旧类通过知识蒸馏提供了一种“软”监督信息。
知识蒸馏(Knowledge Distillation)[6]
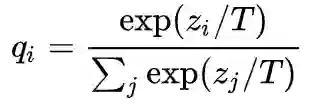
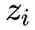 为第i
类的logits输出,
为第i
类的logits输出,
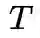 为温度系数。知识蒸馏的损失函数可以看作是最小化Teacher模型和Student模型在已有数据集上数据似然的KL散度。这种监督信息相较于一般的标签分布一方面更加的平滑,另外一方面能够一定程度上反应不同类别之间的相似关系。
为温度系数。知识蒸馏的损失函数可以看作是最小化Teacher模型和Student模型在已有数据集上数据似然的KL散度。这种监督信息相较于一般的标签分布一方面更加的平滑,另外一方面能够一定程度上反应不同类别之间的相似关系。
训练流程
新类的标签监督信息:即新类对应的logits与标签的交叉熵损失(KL散度)
旧类的知识蒸馏:新旧模型在旧类上的的logits的交叉熵损失(包含温度系数:设置温度系数大于一,来增强模型对于类别相似性的编码能力)
参数偏移正则项,对于新模型参数关于旧模型参数偏移的正则项。

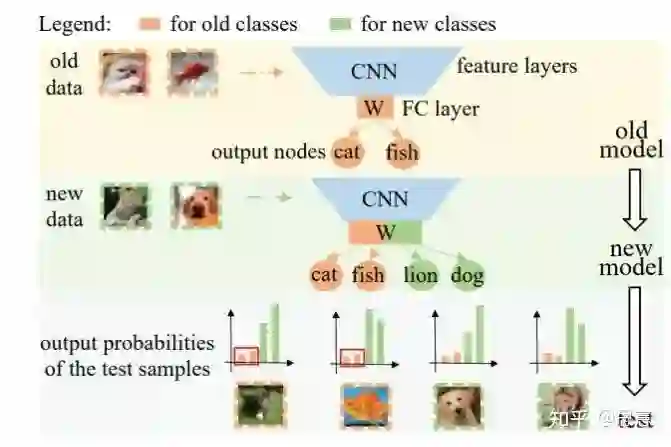
5.2 iCaRL: Incremental Classifier and Representation Learning[7]
核心摘要
给Class-Incremental Learning的设定一个规范的定义:
模型需要在一个新的类别不断出现的流式数据中进行训练。
模型在任意阶段,都应该能够对目前见到的所有类别进行准确的分类。
模型的计算消耗和存储消耗必须设置一个上界或者只会随着任务数量缓慢增长。
将新来的类别数据集与保留的旧类数据的exemplar set合并得到当前轮的数据集。
使用sigmoid将模型输出的logits转化为0-1之间。将目标标签转化为one-hot向量表示。
对于新类的分类,我们使用binary cross entropy来计算损失。这里的binary cross entropy的计算仅仅考虑了所有的新的类别的计算,这种方式能够使得我们在学习新的样本的时候,不会更新旧的线性分类器中的权重向量,从而减少不均衡的数据流对样本分类的影响。
对于旧类的分类,则仿照LwF的模式,计算新旧模型在旧类上的概率输出的binary cross entropy的损失来训练模型。
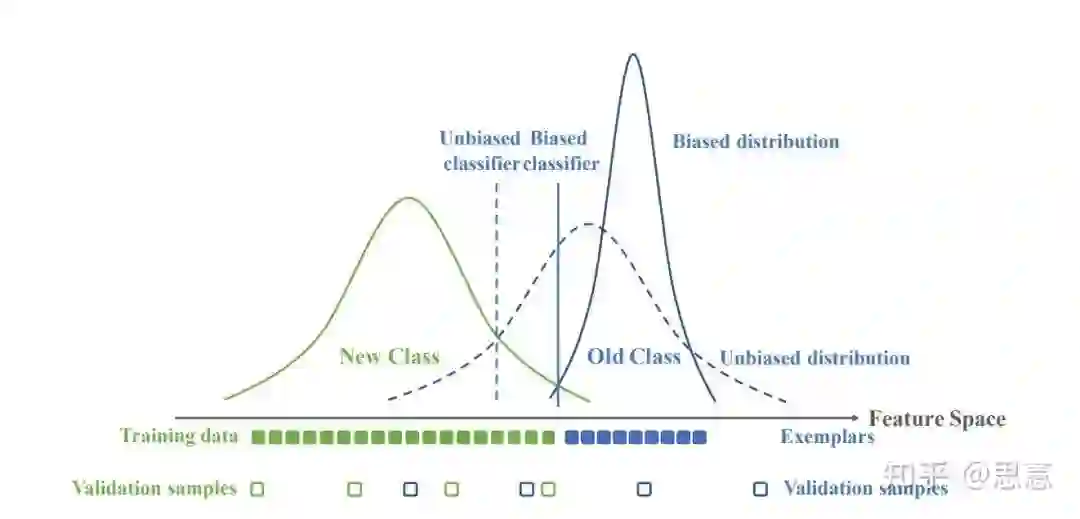
没有足够的旧类样本来进行训练,导致模型不能够保持旧类内部之间的分辨能力。
旧类样本显著少于新类样本,导致模型出现了极大的分类偏执,这种bias导致模型无论遇到旧类样本还是新类样本,都会在新类的概率输出上给出一个较大的值。
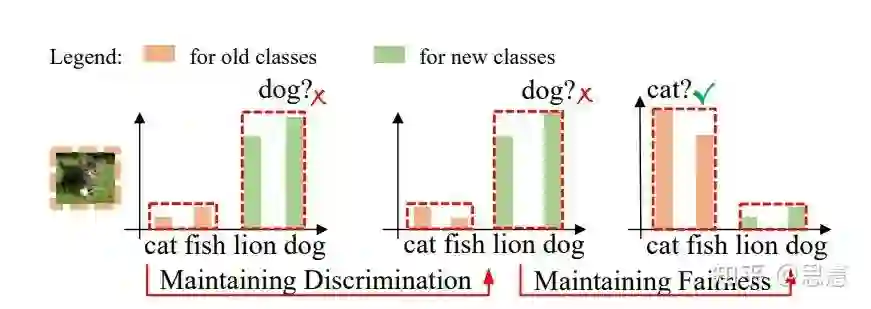
保持旧类之间的相对大小:即Maintaining Discrimination
处理新旧类的公平问题,即实现新旧类分类偏好的对齐:Maintaining Fairness
DER固定住原有的特征提取器
,并创建新的特征提取器
,将两特征拼接得到总的特征提取器
。
将
提取得到的特征送入新创建的分类器
,并计算与目标的交叉熵损失。
为了更好地提取特征,DER另外使用了一个辅助分类器
,仅仅使用新的特征,并要求新的特征空间能够良好的实现新类之间的辨别。而对于所有的旧类样本,辅助分类器会将他们分类到同一个标签上面。
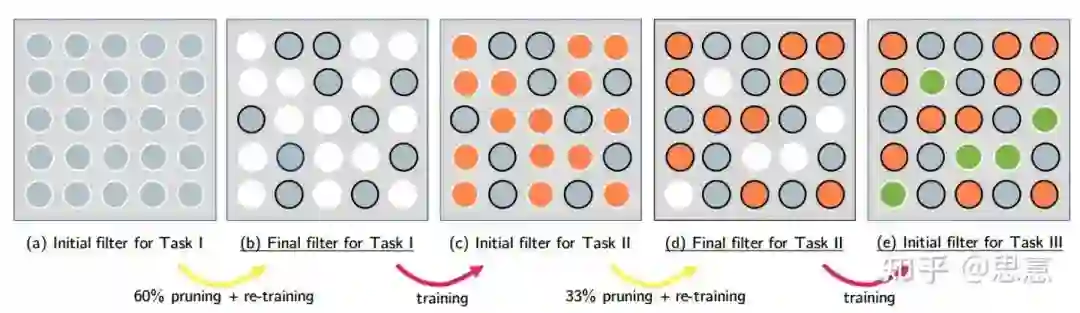
DER还设计了一种剪枝的方式,能够在尽可能保持模型性能的基础上实现大幅度的参数削减。这种剪枝策略从Task-IL的经典方法HAT[11]中借鉴而来,将HAT的以filter的权值的掩码,转变成整个channel的掩码。
FineTune: Baseline method which simply updates parameters on new task, suffering from Catastrophic Forgetting. By default, weights corresponding to the outputs of previous classes are not updated.
EWC: Overcoming catastrophic forgetting in neural networks. PNAS2017 [paper]
LwF: Learning without Forgetting. ECCV2016 [paper]
Replay: Baseline method with exemplars.
GEM: Gradient Episodic Memory for Continual Learning. NIPS2017 [paper]
iCaRL: Incremental Classifier and Representation Learning. CVPR2017 [paper]
BiC: Large Scale Incremental Learning. CVPR2019 [paper]
WA: Maintaining Discrimination and Fairness in Class Incremental Learning. CVPR2020 [paper]
PODNet: PODNet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. ECCV2020 [paper]
DER: DER: Dynamically Expandable Representation for Class Incremental Learning. CVPR2021 [paper]
Coil: Co-Transport for Class-Incremental Learning. ACM MM2021 [paper]
Zhiyuan Chen; Bing Liu; Ronald Brachman; Peter Stone; Francesca Rossi, Lifelong Machine Learning: Second Edition , Morgan & Claypool, 2018. https://ieeexplore.ieee.org/document/8438617
Catastrophic forgetting in connectionist networks https://www.sciencedirect.com/science/article/pii/S1364661399012942
PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning https://arxiv.org/abs/1711.05769
Three scenarios for continual learning https://arxiv.org/abs/1904.07734
Learning without Forgetting https://arxiv.org/abs/1606.09282
Distilling the Knowledge in a Neural Network https://arxiv.org/abs/1503.02531
iCaRL: Incremental Classifier and Representation Learning https://arxiv.org/abs/1611.07725
Large Scale Incremental Learning https://arxiv.org/abs/1905.13260
Maintaining Discrimination and Fairness in Class Incremental Learning https://arxiv.org/abs/1911.07053
DER: Dynamically Expandable Representation for Class Incremental Learning https://arxiv.org/abs/2103.16788
https://arxiv.org/abs/1801.01423 https://arxiv.org/abs/1801.01423
Co-Transport for Class-Incremental Learning https://arxiv.org/abs/2107.12654
PyCIL: A Python Toolbox for Class-Incremental Learning https://arxiv.org/abs/2112.12533

提出了使用保留的旧类数据来进行nearest-mean-of-exemplars的分类方式,而非直接使用训练阶段的到的线性分类器。这是因为使用交叉熵损失函数在不平衡的数据集上直接进行训练,很容易出现较大的分类器的偏执。而模型提取的特征则能够很大程度上缓解这个问题。
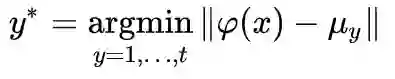
训练流程

5.3 BiC[8]
核心摘要
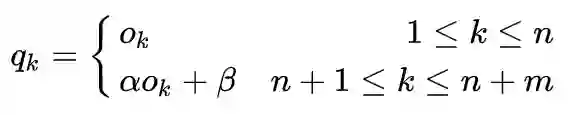
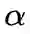 并加上
并加上
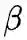 , 其中
, 其中
 由Bias Correction的训练阶段得到。
由Bias Correction的训练阶段得到。
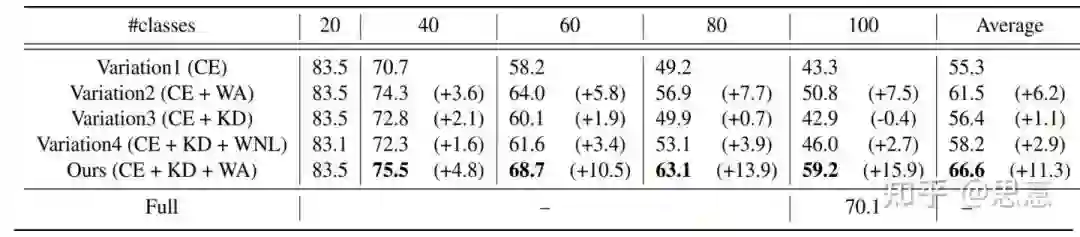
5.4 WA[9]
核心摘要

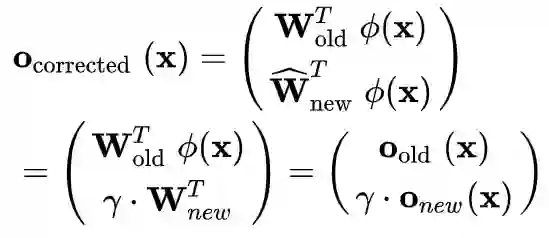
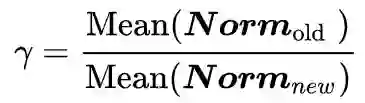
5.5 DER[10]
核心摘要
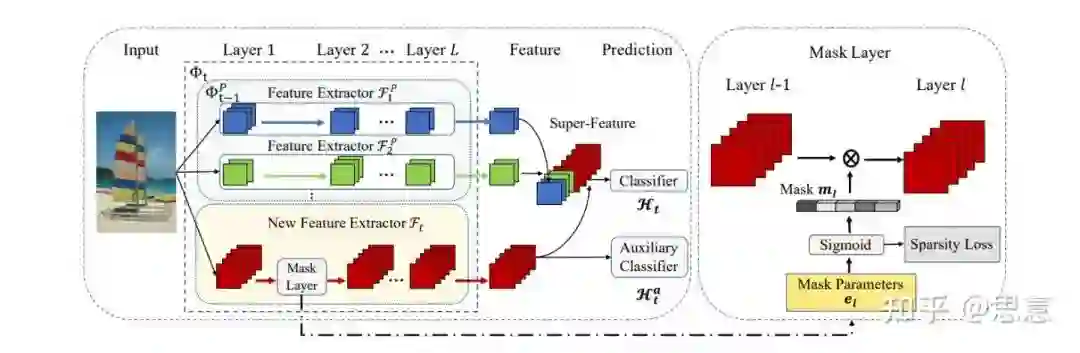
训练流程
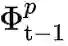
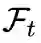
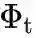
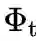
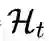
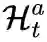
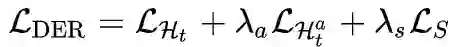
5.6 COIL[12]
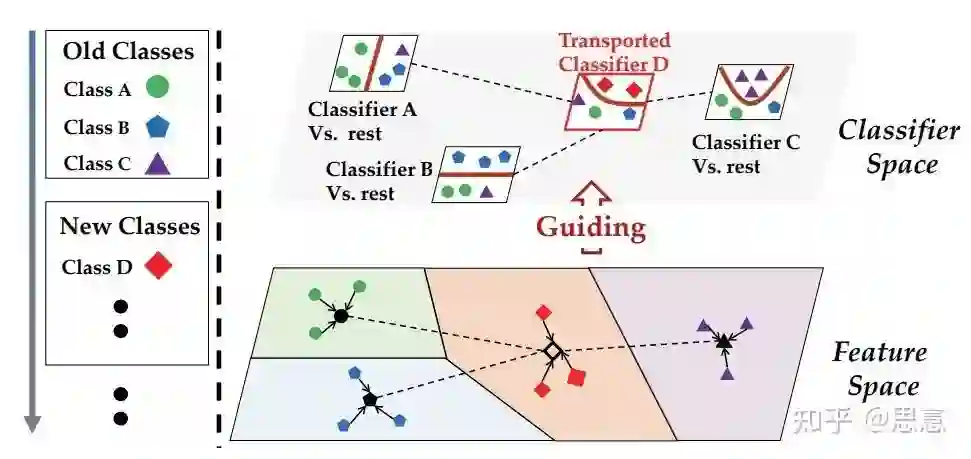
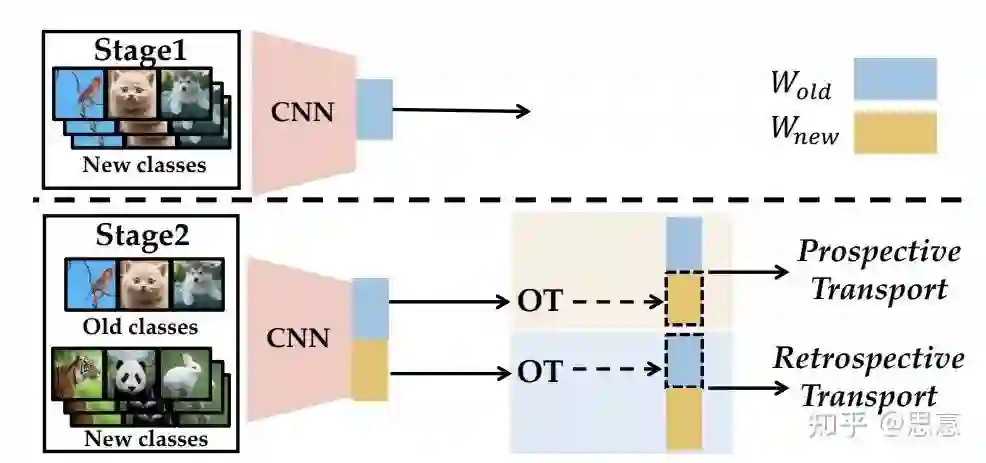
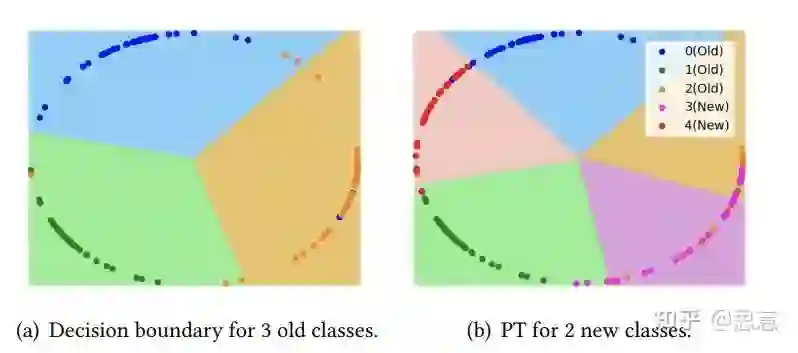
六、PyCIL: A Python Toolbox for Class-Incremental Learning
Methods Reproduced
部分实验结果
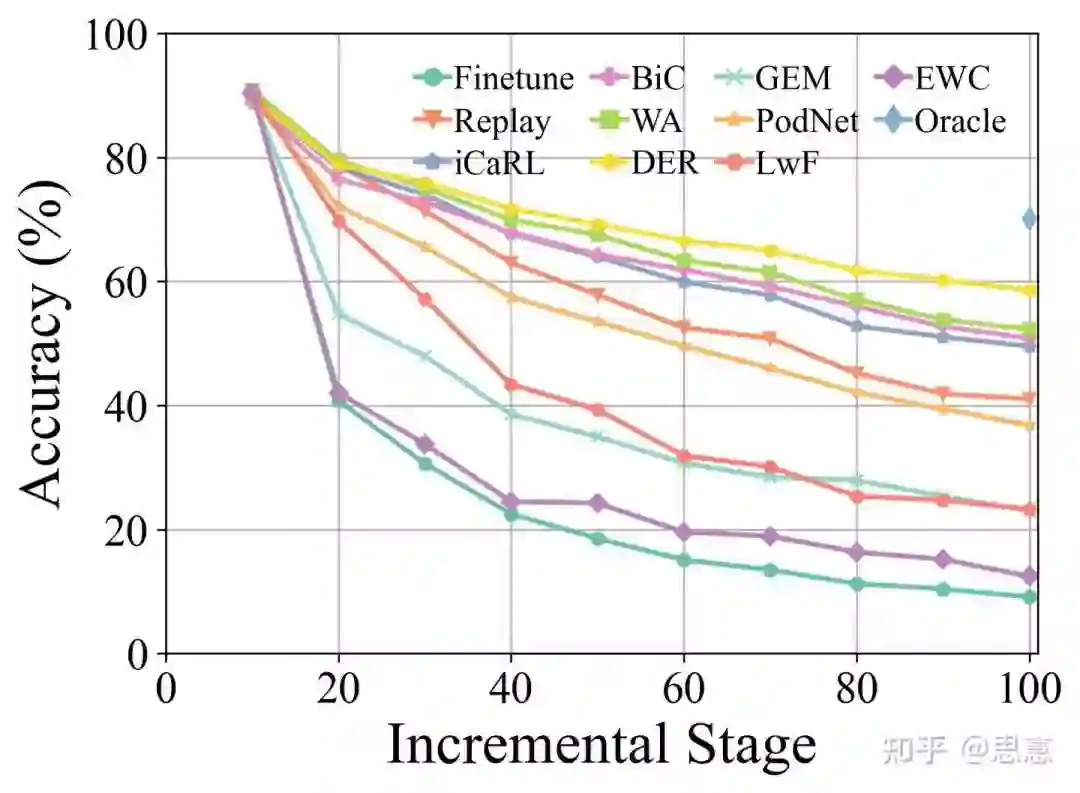
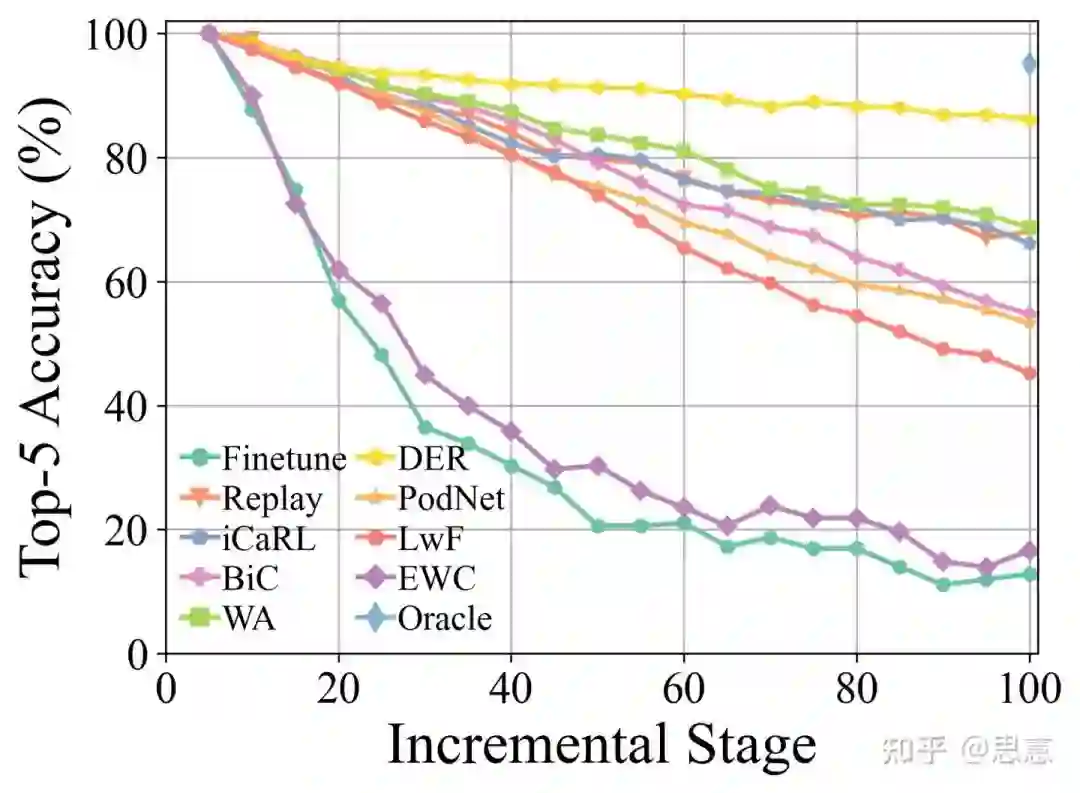
参考

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com